 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAS-Net: Conditional Atlas Generation and Brain Segmentation for Fetal MRI
May 17, 2022Fetal Magnetic Resonance Imaging (MRI) is used in prenatal diagnosis and to assess early brain development. Accurate segmentation of the different brain tissues is a vital step in several brain analysis tasks, such as cortical surface reconstruction and tissue thickness measurements. Fetal MRI scans, however, are prone to motion artifacts that can affect the correctness of both manual and automatic segmentation techniques. In this paper, we propose a novel network structure that can simultaneously generate conditional atlases and predict brain tissue segmentation, called CAS-Net. The conditional atlases provide anatomical priors that can constrain the segmentation connectivity, despite the heterogeneity of intensity values caused by motion or partial volume effects. The proposed method is trained and evaluated on 253 subjects from the developing Human Connectome Project (dHCP). The results demonstrate that the proposed method can generate conditional age-specific atlas with sharp boundary and shape variance. It also segment multi-category brain tissues for fetal MRI with a high overall Dice similarity coefficient (DSC) of $85.2\%$ for the selected 9 tissue labels.
Split HE: Fast Secure Inference Combining Split Learning and Homomorphic Encryption
Feb 27, 2022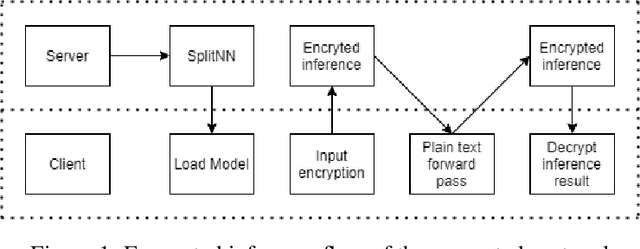

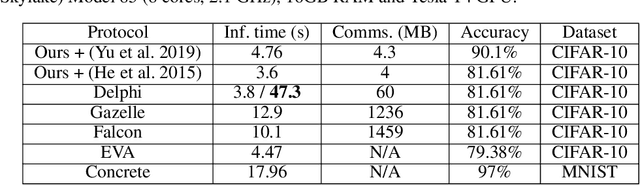
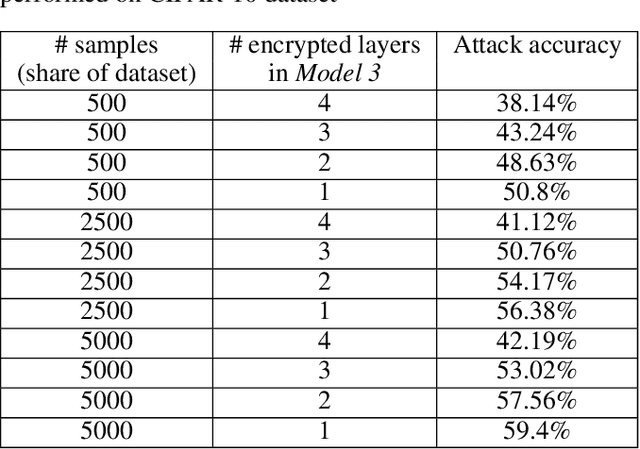
This work presents a novel protocol for fast secure inference of neural networks applied to computer vision applications. It focuses on improving the overall performance of the online execution by deploying a subset of the model weights in plaintext on the client's machine, in the fashion of SplitNNs. We evaluate our protocol on benchmark neural networks trained on the CIFAR-10 dataset using SEAL via TenSEAL and discuss runtime and security performances. Empirical security evaluation using Membership Inference and Model Extraction attacks showed that the protocol was more resilient under the same attacks than a similar approach also based on SplitNN. When compared to related work, we demonstrate improvements of 2.5x-10x for the inference time and 14x-290x in communication costs.
CortexODE: Learning Cortical Surface Reconstruction by Neural ODEs
Feb 16, 2022
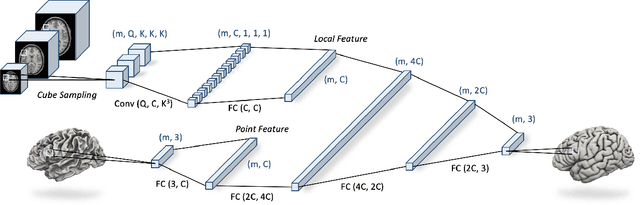

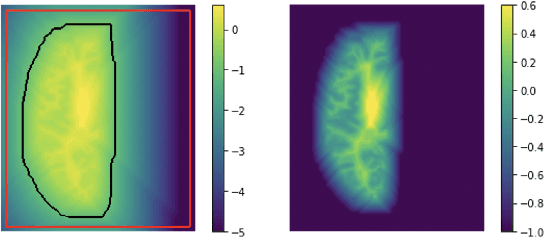
We present CortexODE, a deep learning framework for cortical surface reconstruction. CortexODE leverages neural ordinary different equations (ODEs) to deform an input surface into a target shape by learning a diffeomorphic flow. The trajectories of the points on the surface are modeled as ODEs, where the derivatives of their coordinates are parameterized via a learnable Lipschitz-continuous deformation network. This provides theoretical guarantees for the prevention of self-intersections. CortexODE can be integrated to an automatic learning-based pipeline, which reconstructs cortical surfaces efficiently in less than 6 seconds. The pipeline utilizes a 3D U-Net to predict a white matter segmentation from brain Magnetic Resonance Imaging (MRI) scans, and further generates a signed distance function that represents an initial surface. Fast topology correction is introduced to guarantee homeomorphism to a sphere. Following the isosurface extraction step, two CortexODE models are trained to deform the initial surface to white matter and pial surfaces respectively. The proposed pipeline is evaluated on large-scale neuroimage datasets in various age groups including neonates (25-45 weeks), young adults (22-36 years) and elderly subjects (55-90 years). Our experiments demonstrate that the CortexODE-based pipeline can achieve less than 0.2mm average geometric error while being orders of magnitude faster compared to conventional processing pipelines.
FedRAD: Federated Robust Adaptive Distillation
Dec 02, 2021
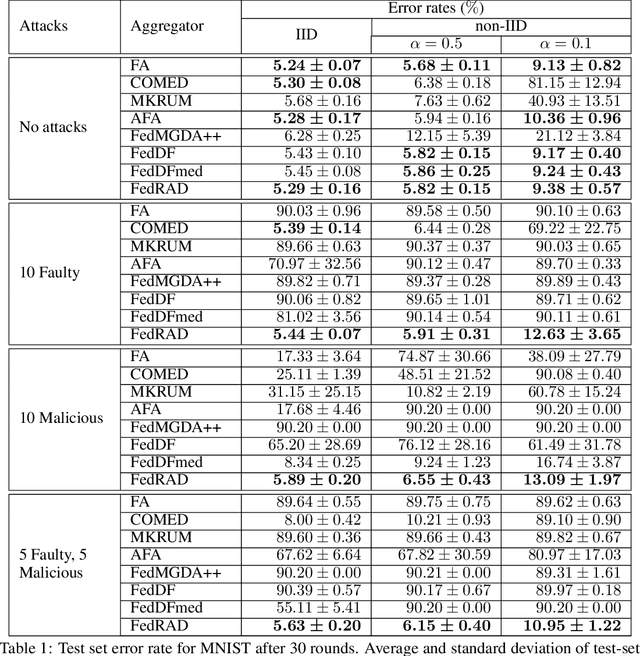
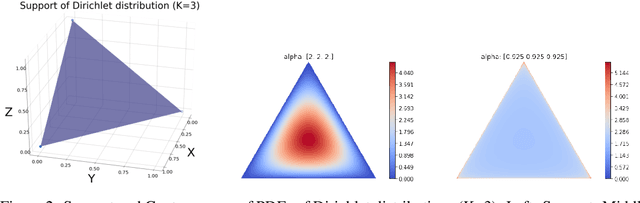
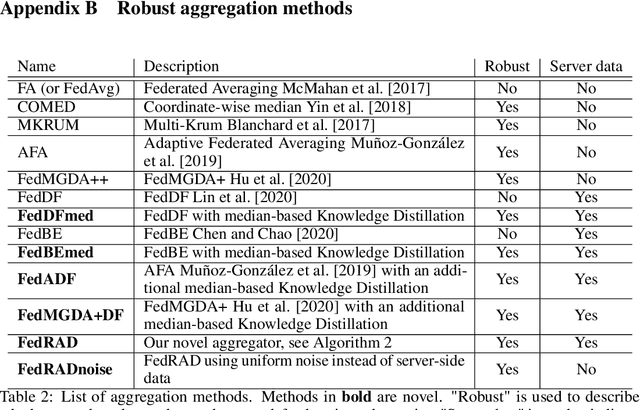
The robustness of federated learning (FL) is vital for the distributed training of an accurate global model that is shared among large number of clients. The collaborative learning framework by typically aggregating model updates is vulnerable to model poisoning attacks from adversarial clients. Since the shared information between the global server and participants are only limited to model parameters, it is challenging to detect bad model updates. Moreover, real-world datasets are usually heterogeneous and not independent and identically distributed (Non-IID) among participants, which makes the design of such robust FL pipeline more difficult. In this work, we propose a novel robust aggregation method, Federated Robust Adaptive Distillation (FedRAD), to detect adversaries and robustly aggregate local models based on properties of the median statistic, and then performing an adapted version of ensemble Knowledge Distillation. We run extensive experiments to evaluate the proposed method against recently published works. The results show that FedRAD outperforms all other aggregators in the presence of adversaries, as well as in heterogeneous data distributions.
PialNN: A Fast Deep Learning Framework for Cortical Pial Surface Reconstruction
Sep 06, 2021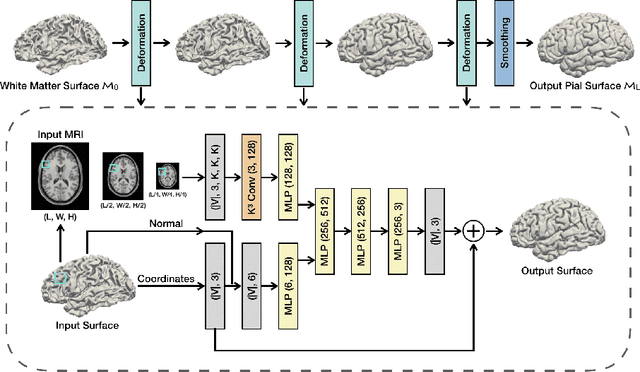
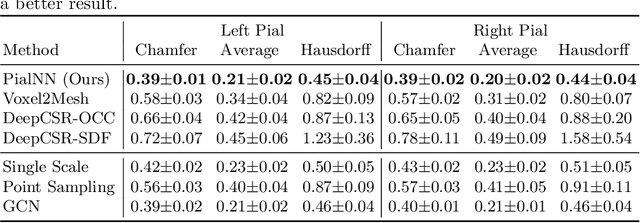
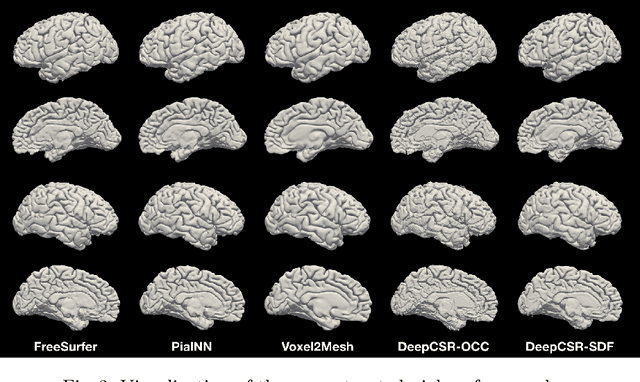
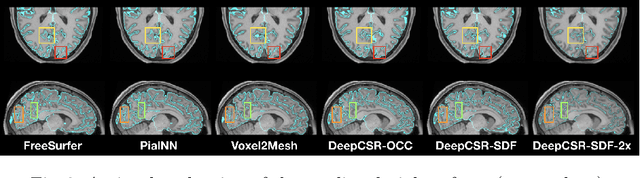
Traditional cortical surface reconstruction is time consuming and limited by the resolution of brain Magnetic Resonance Imaging (MRI). In this work, we introduce Pial Neural Network (PialNN), a 3D deep learning framework for pial surface reconstruction. PialNN is trained end-to-end to deform an initial white matter surface to a target pial surface by a sequence of learned deformation blocks. A local convolutional operation is incorporated in each block to capture the multi-scale MRI information of each vertex and its neighborhood. This is fast and memory-efficient, which allows reconstructing a pial surface mesh with 150k vertices in one second. The performance is evaluated on the Human Connectome Project (HCP) dataset including T1-weighted MRI scans of 300 subjects. The experimental results demonstrate that PialNN reduces the geometric error of the predicted pial surface by 30% compared to state-of-the-art deep learning approaches.
Bayesian analysis of the prevalence bias: learning and predicting from imbalanced data
Jul 31, 2021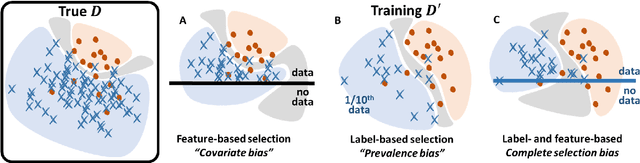
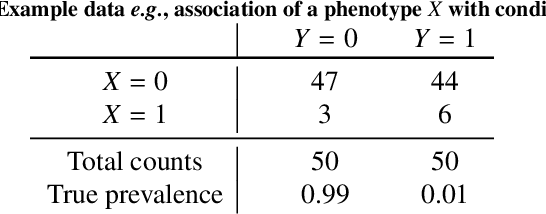

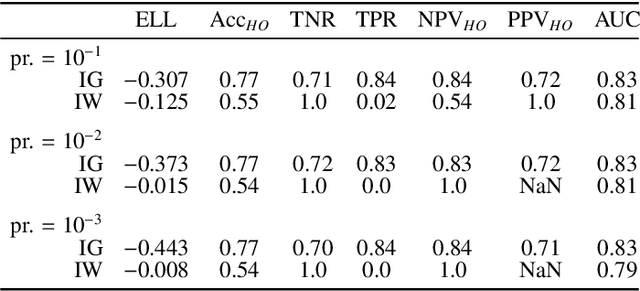
Datasets are rarely a realistic approximation of the target population. Say, prevalence is misrepresented, image quality is above clinical standards, etc. This mismatch is known as sampling bias. Sampling biases are a major hindrance for machine learning models. They cause significant gaps between model performance in the lab and in the real world. Our work is a solution to prevalence bias. Prevalence bias is the discrepancy between the prevalence of a pathology and its sampling rate in the training dataset, introduced upon collecting data or due to the practioner rebalancing the training batches. This paper lays the theoretical and computational framework for training models, and for prediction, in the presence of prevalence bias. Concretely a bias-corrected loss function, as well as bias-corrected predictive rules, are derived under the principles of Bayesian risk minimization. The loss exhibits a direct connection to the information gain. It offers a principled alternative to heuristic training losses and complements test-time procedures based on selecting an operating point from summary curves. It integrates seamlessly in the current paradigm of (deep) learning using stochastic backpropagation and naturally with Bayesian models.
Communicative Reinforcement Learning Agents for Landmark Detection in Brain Images
Sep 27, 2020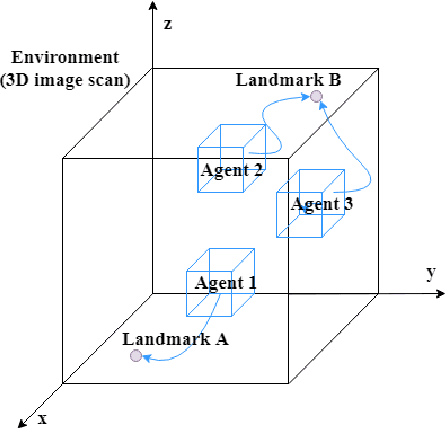
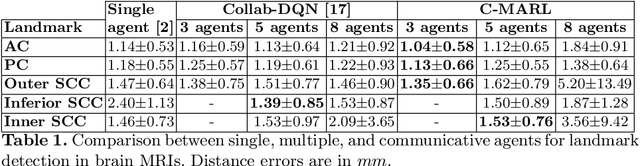
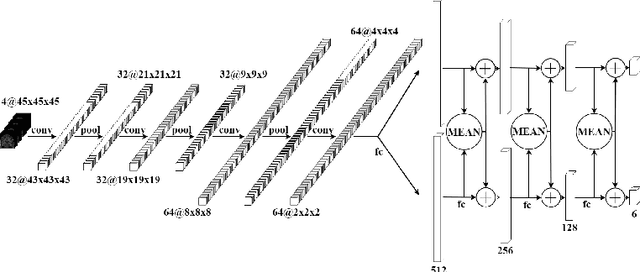
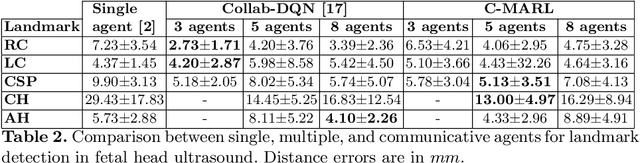
Accurate detection of anatomical landmarks is an essential step in several medical imaging tasks. We propose a novel communicative multi-agent reinforcement learning (C-MARL) system to automatically detect landmarks in 3D brain images. C-MARL enables the agents to learn explicit communication channels, as well as implicit communication signals by sharing certain weights of the architecture among all the agents. The proposed approach is evaluated on two brain imaging datasets from adult magnetic resonance imaging (MRI) and fetal ultrasound scans. Our experiments show that involving multiple cooperating agents by learning their communication with each other outperforms previous approaches using single agents.
Geometric Deep Learning for Post-Menstrual Age Prediction based on the Neonatal White Matter Cortical Surface
Aug 13, 2020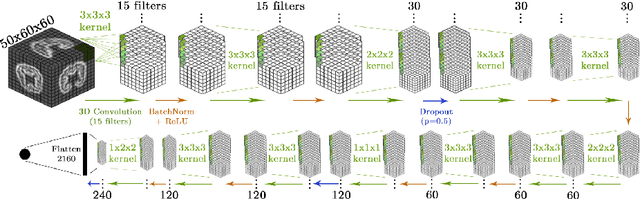
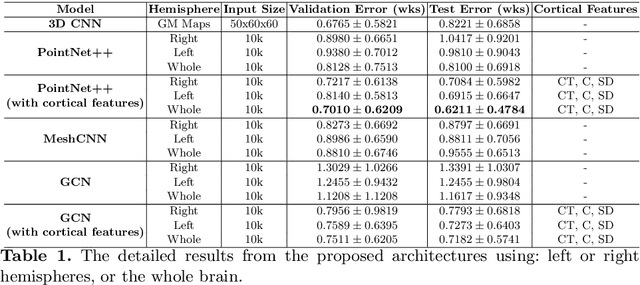

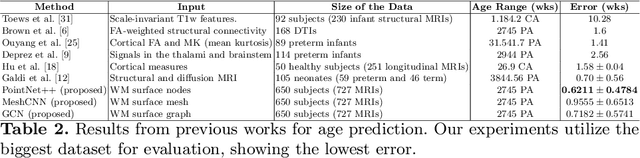
Accurate estimation of the age in neonates is essential for measuring neurodevelopmental, medical, and growth outcomes. In this paper, we propose a novel approach to predict the post-menstrual age (PA) at scan, using techniques from geometric deep learning, based on the neonatal white matter cortical surface. We utilize and compare multiple specialized neural network architectures that predict the age using different geometric representations of the cortical surface; we compare MeshCNN, Pointnet++, GraphCNN, and a volumetric benchmark. The dataset is part of the Developing Human Connectome Project (dHCP), and is a cohort of healthy and premature neonates. We evaluate our approach on 650 subjects (727scans) with PA ranging from 27 to 45 weeks. Our results show accurate prediction of the estimated PA, with mean error less than one week.
Flexible Conditional Image Generation of Missing Data with Learned Mental Maps
Aug 29, 2019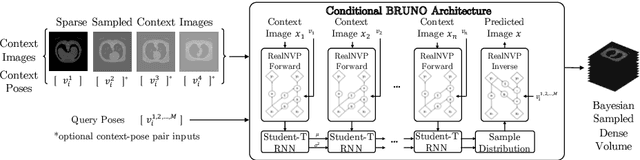
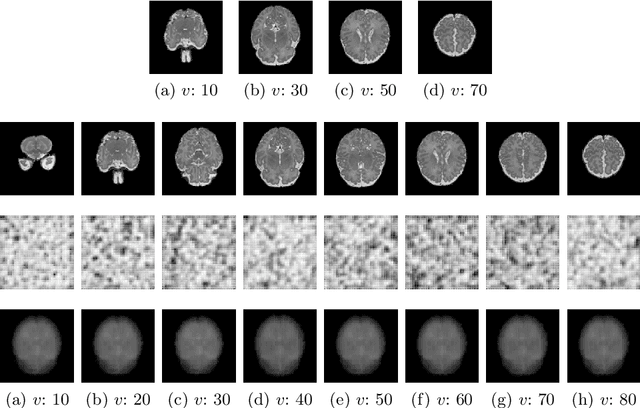
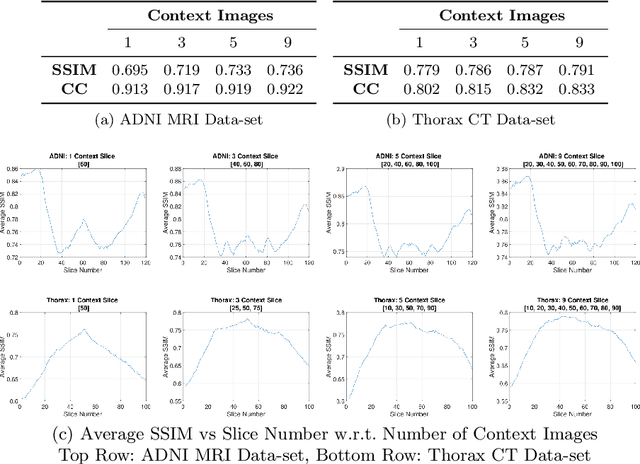
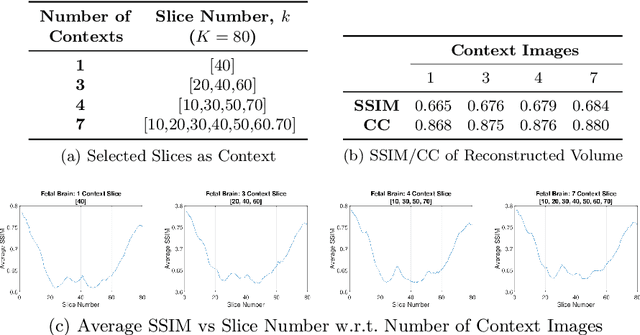
Real-world settings often do not allow acquisition of high-resolution volumetric images for accurate morphological assessment and diagnostic. In clinical practice it is frequently common to acquire only sparse data (e.g. individual slices) for initial diagnostic decision making. Thereby, physicians rely on their prior knowledge (or mental maps) of the human anatomy to extrapolate the underlying 3D information. Accurate mental maps require years of anatomy training, which in the first instance relies on normative learning, i.e. excluding pathology. In this paper, we leverage Bayesian Deep Learning and environment mapping to generate full volumetric anatomy representations from none to a small, sparse set of slices. We evaluate proof of concept implementations based on Generative Query Networks (GQN) and Conditional BRUNO using abdominal CT and brain MRI as well as in a clinical application involving sparse, motion-corrupted MR acquisition for fetal imaging. Our approach allows to reconstruct 3D volumes from 1 to 4 tomographic slices, with a SSIM of 0.7+ and cross-correlation of 0.8+ compared to the 3D ground truth.
Multiple Landmark Detection using Multi-Agent Reinforcement Learning
Jul 22, 2019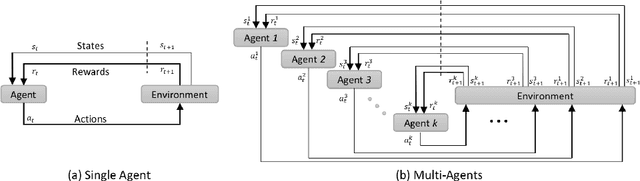

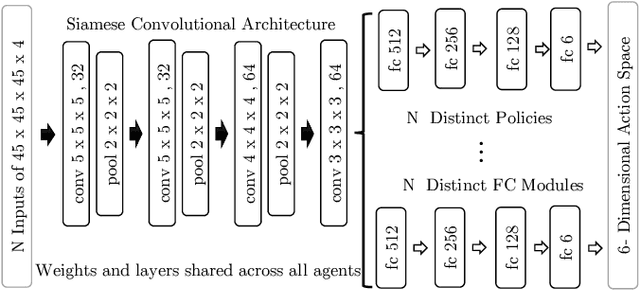

The detection of anatomical landmarks is a vital step for medical image analysis and applications for diagnosis, interpretation and guidance. Manual annotation of landmarks is a tedious process that requires domain-specific expertise and introduces inter-observer variability. This paper proposes a new detection approach for multiple landmarks based on multi-agent reinforcement learning. Our hypothesis is that the position of all anatomical landmarks is interdependent and non-random within the human anatomy, thus finding one landmark can help to deduce the location of others. Using a Deep Q-Network (DQN) architecture we construct an environment and agent with implicit inter-communication such that we can accommodate K agents acting and learning simultaneously, while they attempt to detect K different landmarks. During training the agents collaborate by sharing their accumulated knowledge for a collective gain. We compare our approach with state-of-the-art architectures and achieve significantly better accuracy by reducing the detection error by 50%, while requiring fewer computational resources and time to train compared to the naive approach of training K agents separately.