 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Machine Learning and the Semblance of Trust
Paper and Code
Dec 21, 2021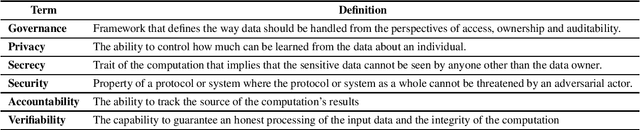
The utilisation of large and diverse datasets for machine learning (ML) at scale is required to promote scientific insight into many meaningful problems. However, due to data governance regulations such as GDPR as well as ethical concerns, the aggregation of personal and sensitive data is problematic, which prompted the development of alternative strategies such as distributed ML (DML). Techniques such as Federated Learning (FL) allow the data owner to maintain data governance and perform model training locally without having to share their data. FL and related techniques are often described as privacy-preserving. We explain why this term is not appropriate and outline the risks associated with over-reliance on protocols that were not designed with formal definitions of privacy in mind. We further provide recommendations and examples on how such algorithms can be augmented to provide guarantees of governance, security, privacy and verifiability for a general ML audience without prior exposure to formal privacy techniques.