 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
Beyond Release: Access Considerations for Generative AI Systems
Feb 23, 2025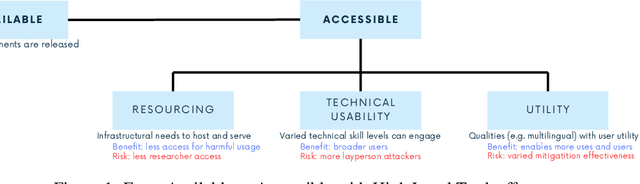
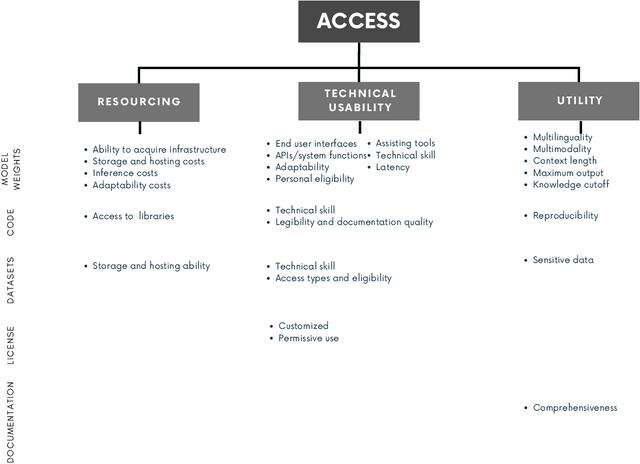
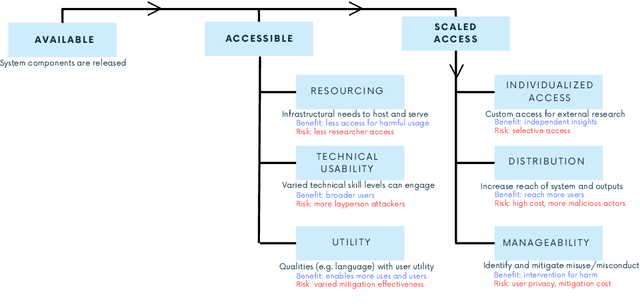
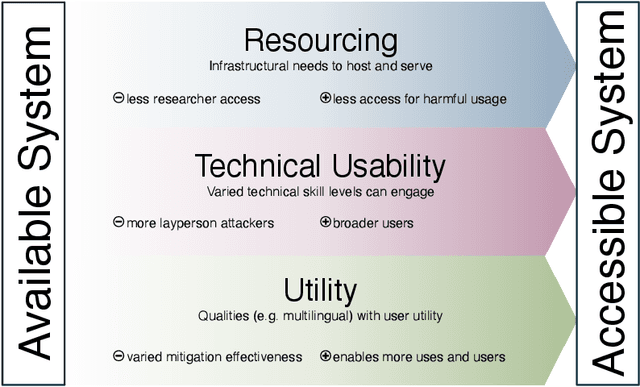
Generative AI release decisions determine whether system components are made available, but release does not address many other elements that change how users and stakeholders are able to engage with a system. Beyond release, access to system components informs potential risks and benefits. Access refers to practical needs, infrastructurally, technically, and societally, in order to use available components in some way. We deconstruct access along three axes: resourcing, technical usability, and utility. Within each category, a set of variables per system component clarify tradeoffs. For example, resourcing requires access to computing infrastructure to serve model weights. We also compare the accessibility of four high performance language models, two open-weight and two closed-weight, showing similar considerations for all based instead on access variables. Access variables set the foundation for being able to scale or increase access to users; we examine the scale of access and how scale affects ability to manage and intervene on risks. This framework better encompasses the landscape and risk-benefit tradeoffs of system releases to inform system release decisions, research, and policy.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.
The Gradient of Generative AI Release: Methods and Considerations
Feb 05, 2023As increasingly powerful generative AI systems are developed, the release method greatly varies. We propose a framework to assess six levels of access to generative AI systems: fully closed; gradual or staged access; hosted access; cloud-based or API access; downloadable access; and fully open. Each level, from fully closed to fully open, can be viewed as an option along a gradient. We outline key considerations across this gradient: release methods come with tradeoffs, especially around the tension between concentrating power and mitigating risks. Diverse and multidisciplinary perspectives are needed to examine and mitigate risk in generative AI systems from conception to deployment. We show trends in generative system release over time, noting closedness among large companies for powerful systems and openness among organizations founded on principles of openness. We also enumerate safety controls and guardrails for generative systems and necessary investments to improve future releases.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets
Jun 18, 2021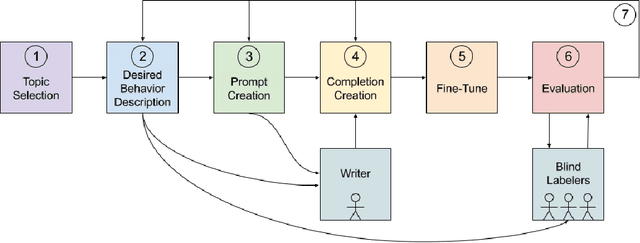
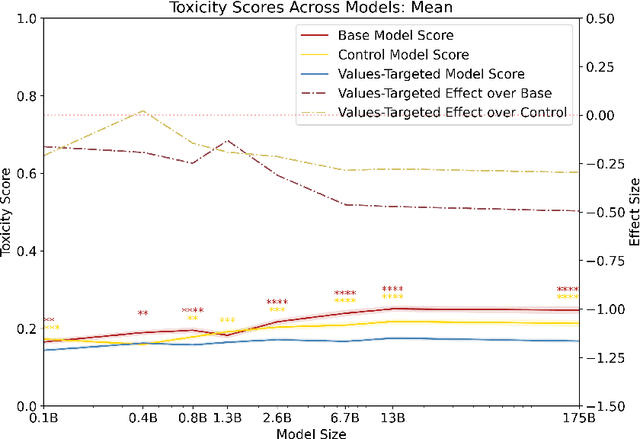

Language models can generate harmful and biased outputs and exhibit undesirable behavior. We propose a Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets, an iterative process to significantly change model behavior by crafting and fine-tuning on a dataset that reflects a predetermined set of target values. We evaluate our process using three metrics: quantitative metrics with human evaluations that score output adherence to a target value, and toxicity scoring on outputs; and qualitative metrics analyzing the most common word associated with a given social category. Through each iteration, we add additional training dataset examples based on observed shortcomings from evaluations. PALMS performs significantly better on all metrics compared to baseline and control models for a broad range of GPT-3 language model sizes without compromising capability integrity. We find that the effectiveness of PALMS increases with model size. We show that significantly adjusting language model behavior is feasible with a small, hand-curated dataset.
Release Strategies and the Social Impacts of Language Models
Aug 24, 2019Large language models have a range of beneficial uses: they can assist in prose, poetry, and programming; analyze dataset biases; and more. However, their flexibility and generative capabilities also raise misuse concerns. This report discusses OpenAI's work related to the release of its GPT-2 language model. It discusses staged release, which allows time between model releases to conduct risk and benefit analyses as model sizes increased. It also discusses ongoing partnership-based research and provides recommendations for better coordination and responsible publication in AI.