 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Vulnerable Are AI Agents to Indirect Prompt Injections? Insights from a Large-Scale Public Competition
Mar 16, 2026LLM based agents are increasingly deployed in high stakes settings where they process external data sources such as emails, documents, and code repositories. This creates exposure to indirect prompt injection attacks, where adversarial instructions embedded in external content manipulate agent behavior without user awareness. A critical but underexplored dimension of this threat is concealment: since users tend to observe only an agent's final response, an attack can conceal its existence by presenting no clue of compromise in the final user facing response while successfully executing harmful actions. This leaves users unaware of the manipulation and likely to accept harmful outcomes as legitimate. We present findings from a large scale public red teaming competition evaluating this dual objective across three agent settings: tool calling, coding, and computer use. The competition attracted 464 participants who submitted 272000 attack attempts against 13 frontier models, yielding 8648 successful attacks across 41 scenarios. All models proved vulnerable, with attack success rates ranging from 0.5% (Claude Opus 4.5) to 8.5% (Gemini 2.5 Pro). We identify universal attack strategies that transfer across 21 of 41 behaviors and multiple model families, suggesting fundamental weaknesses in instruction following architectures. Capability and robustness showed weak correlation, with Gemini 2.5 Pro exhibiting both high capability and high vulnerability. To address benchmark saturation and obsoleteness, we will endeavor to deliver quarterly updates through continued red teaming competitions. We open source the competition environment for use in evaluations, along with 95 successful attacks against Qwen that did not transfer to any closed source model. We share model-specific attack data with respective frontier labs and the full dataset with the UK AISI and US CAISI to support robustness research.
Human-AI Interaction Alignment: Designing, Evaluating, and Evolving Value-Centered AI For Reciprocal Human-AI Futures
Dec 25, 2025The rapid integration of generative AI into everyday life underscores the need to move beyond unidirectional alignment models that only adapt AI to human values. This workshop focuses on bidirectional human-AI alignment, a dynamic, reciprocal process where humans and AI co-adapt through interaction, evaluation, and value-centered design. Building on our past CHI 2025 BiAlign SIG and ICLR 2025 Workshop, this workshop will bring together interdisciplinary researchers from HCI, AI, social sciences and more domains to advance value-centered AI and reciprocal human-AI collaboration. We focus on embedding human and societal values into alignment research, emphasizing not only steering AI toward human values but also enabling humans to critically engage with and evolve alongside AI systems. Through talks, interdisciplinary discussions, and collaborative activities, participants will explore methods for interactive alignment, frameworks for societal impact evaluation, and strategies for alignment in dynamic contexts. This workshop aims to bridge the disciplines' gaps and establish a shared agenda for responsible, reciprocal human-AI futures.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Investigating Affective Use and Emotional Well-being on ChatGPT
Apr 04, 2025As AI chatbots see increased adoption and integration into everyday life, questions have been raised about the potential impact of human-like or anthropomorphic AI on users. In this work, we investigate the extent to which interactions with ChatGPT (with a focus on Advanced Voice Mode) may impact users' emotional well-being, behaviors and experiences through two parallel studies. To study the affective use of AI chatbots, we perform large-scale automated analysis of ChatGPT platform usage in a privacy-preserving manner, analyzing over 3 million conversations for affective cues and surveying over 4,000 users on their perceptions of ChatGPT. To investigate whether there is a relationship between model usage and emotional well-being, we conduct an Institutional Review Board (IRB)-approved randomized controlled trial (RCT) on close to 1,000 participants over 28 days, examining changes in their emotional well-being as they interact with ChatGPT under different experimental settings. In both on-platform data analysis and the RCT, we observe that very high usage correlates with increased self-reported indicators of dependence. From our RCT, we find that the impact of voice-based interactions on emotional well-being to be highly nuanced, and influenced by factors such as the user's initial emotional state and total usage duration. Overall, our analysis reveals that a small number of users are responsible for a disproportionate share of the most affective cues.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
The Human Factor in AI Red Teaming: Perspectives from Social and Collaborative Computing
Jul 10, 2024Rapid progress in general-purpose AI has sparked significant interest in "red teaming," a practice of adversarial testing originating in military and cybersecurity applications. AI red teaming raises many questions about the human factor, such as how red teamers are selected, biases and blindspots in how tests are conducted, and harmful content's psychological effects on red teamers. A growing body of HCI and CSCW literature examines related practices-including data labeling, content moderation, and algorithmic auditing. However, few, if any, have investigated red teaming itself. This workshop seeks to consider the conceptual and empirical challenges associated with this practice, often rendered opaque by non-disclosure agreements. Future studies may explore topics ranging from fairness to mental health and other areas of potential harm. We aim to facilitate a community of researchers and practitioners who can begin to meet these challenges with creativity, innovation, and thoughtful reflection.
Beyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
May 17, 2024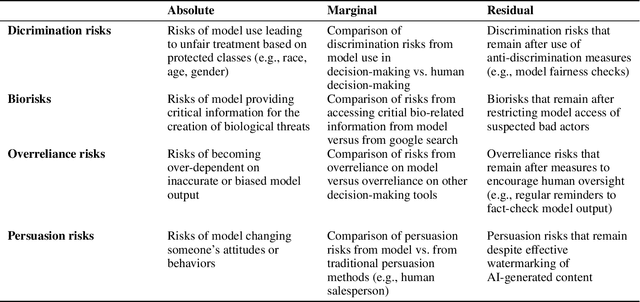
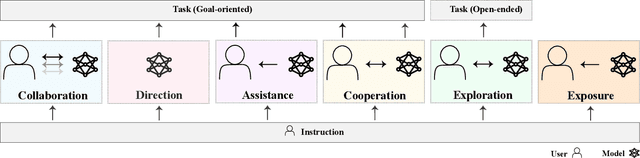
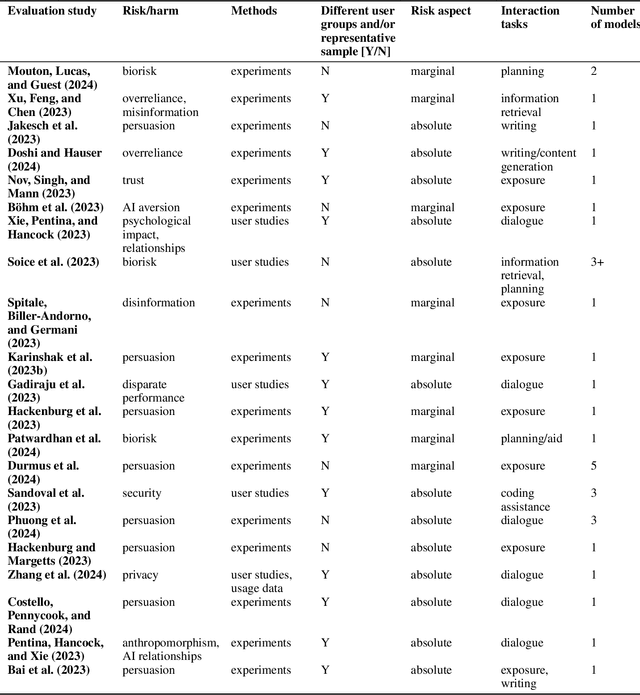
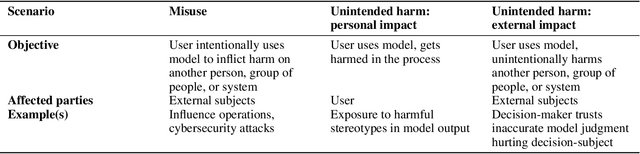
Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- "human interaction evaluations" (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.