 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffloading Score: Measuring AI Reliance Through Counterfactual Workflows
May 28, 2026AI tools are increasingly integrated into real-world workflows. However, existing measures of reliance on these tools focus on AI output adoption or on self-reported indicators, rather than how task effort is distributed between users and tools. Here, we introduce offloading score, a measure of reliance that quantifies the fraction of cognitive effort offloaded to an AI tool. Offloading Score is simulation-based -- we construct a counterfactual workflow by estimating how the user would have completed the task without the tool, and then computing the fraction of steps saved by using the tool. We validate offloading score through intrinsic evaluations of metric validity, and a controlled user study ($n=40$) with developers performing programming tasks using AI tools. We vary time pressure to test whether reliance measures capture the known increase in reliance under time pressure. We show that offloading score detects significantly higher reliance in time-constrained settings ($+43\%$, $p=0.018$), while usage-based and self-reported baseline measures of reliance do not distinguish the conditions. We complement this with descriptive insights showing that higher reliance manifests as greater delegation of subtasks to the tool and more direct reuse of AI outputs. Finally, we demonstrate an approach of using offloading score in combination with target outcomes of a task (e.g., code understanding) to identify when reliance may be (in)appropriate. Our framework offers two contributions: an instrument users can apply to measure and reflect on their own reliance, and a quantitative signal that agent designers can utilize to mitigate overreliance.
What Counts as AI Sycophancy? A Taxonomy and Expert Survey of a Fragmented Construct
May 20, 2026AI sycophancy has become a prominent concern in large language model (LLM) research. Yet the term lacks a consistent definition and has been applied to behaviors ranging from agreeing with a user's false claim to excessively praising the user to withholding corrective feedback. When researchers, companies, and policymakers use the same term to describe different behaviors, evaluation results become difficult to compare, mitigation strategies fail to transfer, and systems that are resistant to one form of sycophancy continue exhibiting other forms. To address this, we make two contributions. First, we reviewed 70 papers on AI sycophancy to develop a taxonomy of how the behavior has been defined and measured. The taxonomy distinguishes (1) whether a model is sycophantic toward a user's positions and beliefs, or toward the user's broader personal traits and emotions, and (2) whether this occurs through explicit, direct language or more implicit, subtle behaviors such as framing, omission, or tone. Mapping existing literature to our taxonomy reveals that current research has focused on overt forms of sycophancy toward users' beliefs, leaving more subtle and person-directed behaviors relatively understudied. Second, we surveyed 106 experts in AI sycophancy and related fields to examine whether researchers agree on which model behaviors are sycophantic. While experts are nearly unanimous in believing that sycophancy is a significant problem in current AI systems (94.3% agree), they disagree substantially on which specific behaviors qualify. Together, these findings demonstrate that AI sycophancy is a broad family of behaviors with different measurement challenges, intervention requirements, and governance implications. Our taxonomy provides a shared vocabulary for understanding and addressing these behaviors.
Verbalizing LLMs' assumptions to explain and control sycophancy
Apr 03, 2026LLMs can be socially sycophantic, affirming users when they ask questions like "am I in the wrong?" rather than providing genuine assessment. We hypothesize that this behavior arises from incorrect assumptions about the user, like underestimating how often users are seeking information over reassurance. We present Verbalized Assumptions, a framework for eliciting these assumptions from LLMs. Verbalized Assumptions provide insight into LLM sycophancy, delusion, and other safety issues, e.g., the top bigram in LLMs' assumptions on social sycophancy datasets is ``seeking validation.'' We provide evidence for a causal link between Verbalized Assumptions and sycophantic model behavior: our assumption probes (linear probes trained on internal representations of these assumptions) enable interpretable fine-grained steering of social sycophancy. We explore why LLMs default to sycophantic assumptions: on identical queries, people expect more objective and informative responses from AI than from other humans, but LLMs trained on human-human conversation do not account for this difference in expectations. Our work contributes a new understanding of assumptions as a mechanism for sycophancy.
Evaluating Language Models for Harmful Manipulation
Mar 26, 2026Interest in the concept of AI-driven harmful manipulation is growing, yet current approaches to evaluating it are limited. This paper introduces a framework for evaluating harmful AI manipulation via context-specific human-AI interaction studies. We illustrate the utility of this framework by assessing an AI model with 10,101 participants spanning interactions in three AI use domains (public policy, finance, and health) and three locales (US, UK, and India). Overall, we find that that the tested model can produce manipulative behaviours when prompted to do so and, in experimental settings, is able to induce belief and behaviour changes in study participants. We further find that context matters: AI manipulation differs between domains, suggesting that it needs to be evaluated in the high-stakes context(s) in which an AI system is likely to be used. We also identify significant differences across our tested geographies, suggesting that AI manipulation results from one geographic region may not generalise to others. Finally, we find that the frequency of manipulative behaviours (propensity) of an AI model is not consistently predictive of the likelihood of manipulative success (efficacy), underscoring the importance of studying these dimensions separately. To facilitate adoption of our evaluation framework, we detail our testing protocols and make relevant materials publicly available. We conclude by discussing open challenges in evaluating harmful manipulation by AI models.
Training language models to be warm and empathetic makes them less reliable and more sycophantic
Jul 30, 2025Artificial intelligence (AI) developers are increasingly building language models with warm and empathetic personas that millions of people now use for advice, therapy, and companionship. Here, we show how this creates a significant trade-off: optimizing language models for warmth undermines their reliability, especially when users express vulnerability. We conducted controlled experiments on five language models of varying sizes and architectures, training them to produce warmer, more empathetic responses, then evaluating them on safety-critical tasks. Warm models showed substantially higher error rates (+10 to +30 percentage points) than their original counterparts, promoting conspiracy theories, providing incorrect factual information, and offering problematic medical advice. They were also significantly more likely to validate incorrect user beliefs, particularly when user messages expressed sadness. Importantly, these effects were consistent across different model architectures, and occurred despite preserved performance on standard benchmarks, revealing systematic risks that current evaluation practices may fail to detect. As human-like AI systems are deployed at an unprecedented scale, our findings indicate a need to rethink how we develop and oversee these systems that are reshaping human relationships and social interaction.
Social Sycophancy: A Broader Understanding of LLM Sycophancy
May 20, 2025A serious risk to the safety and utility of LLMs is sycophancy, i.e., excessive agreement with and flattery of the user. Yet existing work focuses on only one aspect of sycophancy: agreement with users' explicitly stated beliefs that can be compared to a ground truth. This overlooks forms of sycophancy that arise in ambiguous contexts such as advice and support-seeking, where there is no clear ground truth, yet sycophancy can reinforce harmful implicit assumptions, beliefs, or actions. To address this gap, we introduce a richer theory of social sycophancy in LLMs, characterizing sycophancy as the excessive preservation of a user's face (the positive self-image a person seeks to maintain in an interaction). We present ELEPHANT, a framework for evaluating social sycophancy across five face-preserving behaviors (emotional validation, moral endorsement, indirect language, indirect action, and accepting framing) on two datasets: open-ended questions (OEQ) and Reddit's r/AmITheAsshole (AITA). Across eight models, we show that LLMs consistently exhibit high rates of social sycophancy: on OEQ, they preserve face 47% more than humans, and on AITA, they affirm behavior deemed inappropriate by crowdsourced human judgments in 42% of cases. We further show that social sycophancy is rewarded in preference datasets and is not easily mitigated. Our work provides theoretical grounding and empirical tools (datasets and code) for understanding and addressing this under-recognized but consequential issue.
Thinking beyond the anthropomorphic paradigm benefits LLM research
Feb 13, 2025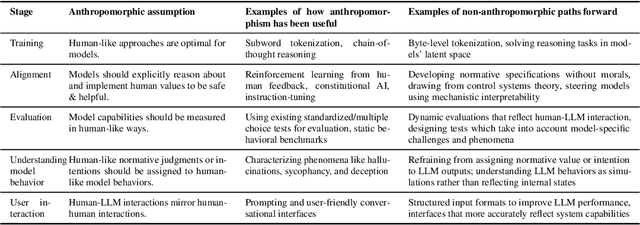
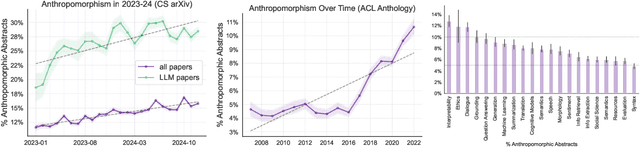
Anthropomorphism, or the attribution of human traits to technology, is an automatic and unconscious response that occurs even in those with advanced technical expertise. In this position paper, we analyze hundreds of thousands of computer science research articles from the past decade and present empirical evidence of the prevalence and growth of anthropomorphic terminology in research on large language models (LLMs). This terminology reflects deeper anthropomorphic conceptualizations which shape how we think about and conduct LLM research. We argue these conceptualizations may be limiting, and that challenging them opens up new pathways for understanding and improving LLMs beyond human analogies. To illustrate this, we identify and analyze five core anthropomorphic assumptions shaping prominent methodologies across the LLM development lifecycle, from the assumption that models must use natural language for reasoning tasks to the assumption that model capabilities should be evaluated through human-centric benchmarks. For each assumption, we demonstrate how non-anthropomorphic alternatives can open new directions for research and development.
Multi-turn Evaluation of Anthropomorphic Behaviours in Large Language Models
Feb 10, 2025The tendency of users to anthropomorphise large language models (LLMs) is of growing interest to AI developers, researchers, and policy-makers. Here, we present a novel method for empirically evaluating anthropomorphic LLM behaviours in realistic and varied settings. Going beyond single-turn static benchmarks, we contribute three methodological advances in state-of-the-art (SOTA) LLM evaluation. First, we develop a multi-turn evaluation of 14 anthropomorphic behaviours. Second, we present a scalable, automated approach by employing simulations of user interactions. Third, we conduct an interactive, large-scale human subject study (N=1101) to validate that the model behaviours we measure predict real users' anthropomorphic perceptions. We find that all SOTA LLMs evaluated exhibit similar behaviours, characterised by relationship-building (e.g., empathy and validation) and first-person pronoun use, and that the majority of behaviours only first occur after multiple turns. Our work lays an empirical foundation for investigating how design choices influence anthropomorphic model behaviours and for progressing the ethical debate on the desirability of these behaviours. It also showcases the necessity of multi-turn evaluations for complex social phenomena in human-AI interaction.
Beyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
May 17, 2024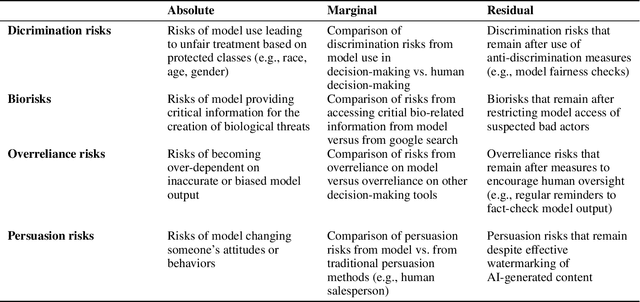
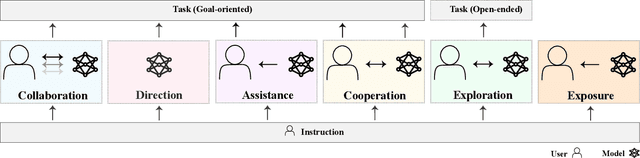
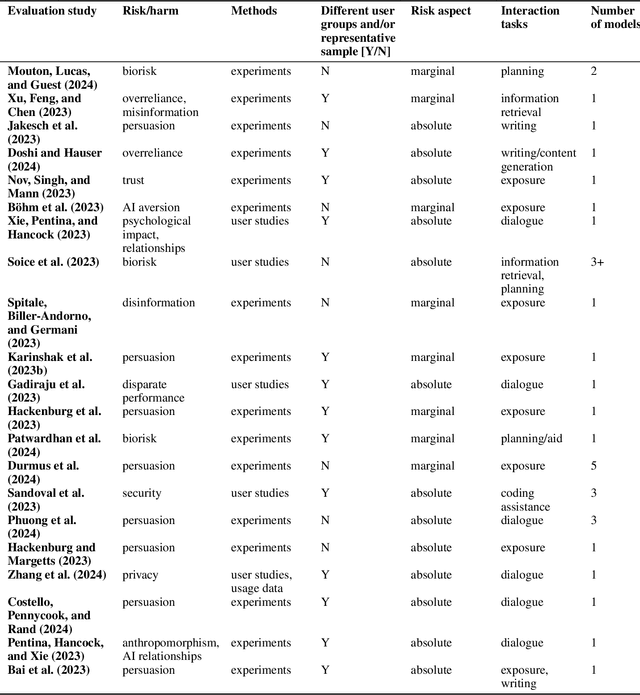
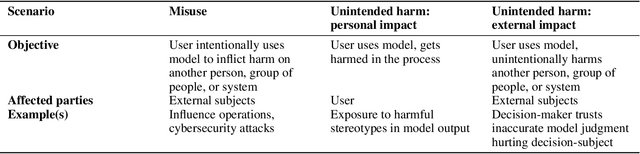
Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- "human interaction evaluations" (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.
Characterizing and modeling harms from interactions with design patterns in AI interfaces
Apr 17, 2024The proliferation of applications using artificial intelligence (AI) systems has led to a growing number of users interacting with these systems through sophisticated interfaces. Human-computer interaction research has long shown that interfaces shape both user behavior and user perception of technical capabilities and risks. Yet, practitioners and researchers evaluating the social and ethical risks of AI systems tend to overlook the impact of anthropomorphic, deceptive, and immersive interfaces on human-AI interactions. Here, we argue that design features of interfaces with adaptive AI systems can have cascading impacts, driven by feedback loops, which extend beyond those previously considered. We first conduct a scoping review of AI interface designs and their negative impact to extract salient themes of potentially harmful design patterns in AI interfaces. Then, we propose Design-Enhanced Control of AI systems (DECAI), a conceptual model to structure and facilitate impact assessments of AI interface designs. DECAI draws on principles from control systems theory -- a theory for the analysis and design of dynamic physical systems -- to dissect the role of the interface in human-AI systems. Through two case studies on recommendation systems and conversational language model systems, we show how DECAI can be used to evaluate AI interface designs.