 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFraming Migration: A Computational Analysis of UK Parliamentary Discourse
Sep 17, 2025We present a large-scale computational analysis of migration-related discourse in UK parliamentary debates spanning over 75 years and compare it with US congressional discourse. Using open-weight LLMs, we annotate each statement with high-level stances toward migrants and track the net tone toward migrants across time and political parties. For the UK, we extend this with a semi-automated framework for extracting fine-grained narrative frames to capture nuances of migration discourse. Our findings show that, while US discourse has grown increasingly polarised, UK parliamentary attitudes remain relatively aligned across parties, with a persistent ideological gap between Labour and the Conservatives, reaching its most negative level in 2025. The analysis of narrative frames in the UK parliamentary statements reveals a shift toward securitised narratives such as border control and illegal immigration, while longer-term integration-oriented frames such as social integration have declined. Moreover, discussions of national law about immigration have been replaced over time by international law and human rights, revealing nuances in discourse trends. Taken together broadly, our findings demonstrate how LLMs can support scalable, fine-grained discourse analysis in political and historical contexts.
Training language models to be warm and empathetic makes them less reliable and more sycophantic
Jul 30, 2025Artificial intelligence (AI) developers are increasingly building language models with warm and empathetic personas that millions of people now use for advice, therapy, and companionship. Here, we show how this creates a significant trade-off: optimizing language models for warmth undermines their reliability, especially when users express vulnerability. We conducted controlled experiments on five language models of varying sizes and architectures, training them to produce warmer, more empathetic responses, then evaluating them on safety-critical tasks. Warm models showed substantially higher error rates (+10 to +30 percentage points) than their original counterparts, promoting conspiracy theories, providing incorrect factual information, and offering problematic medical advice. They were also significantly more likely to validate incorrect user beliefs, particularly when user messages expressed sadness. Importantly, these effects were consistent across different model architectures, and occurred despite preserved performance on standard benchmarks, revealing systematic risks that current evaluation practices may fail to detect. As human-like AI systems are deployed at an unprecedented scale, our findings indicate a need to rethink how we develop and oversee these systems that are reshaping human relationships and social interaction.
Gender Trouble in Language Models: An Empirical Audit Guided by Gender Performativity Theory
May 20, 2025Language models encode and subsequently perpetuate harmful gendered stereotypes. Research has succeeded in mitigating some of these harms, e.g. by dissociating non-gendered terms such as occupations from gendered terms such as 'woman' and 'man'. This approach, however, remains superficial given that associations are only one form of prejudice through which gendered harms arise. Critical scholarship on gender, such as gender performativity theory, emphasizes how harms often arise from the construction of gender itself, such as conflating gender with biological sex. In language models, these issues could lead to the erasure of transgender and gender diverse identities and cause harms in downstream applications, from misgendering users to misdiagnosing patients based on wrong assumptions about their anatomy. For FAccT research on gendered harms to go beyond superficial linguistic associations, we advocate for a broader definition of 'gender bias' in language models. We operationalize insights on the construction of gender through language from gender studies literature and then empirically test how 16 language models of different architectures, training datasets, and model sizes encode gender. We find that language models tend to encode gender as a binary category tied to biological sex, and that gendered terms that do not neatly fall into one of these binary categories are erased and pathologized. Finally, we show that larger models, which achieve better results on performance benchmarks, learn stronger associations between gender and sex, further reinforcing a narrow understanding of gender. Our findings lead us to call for a re-evaluation of how gendered harms in language models are defined and addressed.
Clinical knowledge in LLMs does not translate to human interactions
Apr 26, 2025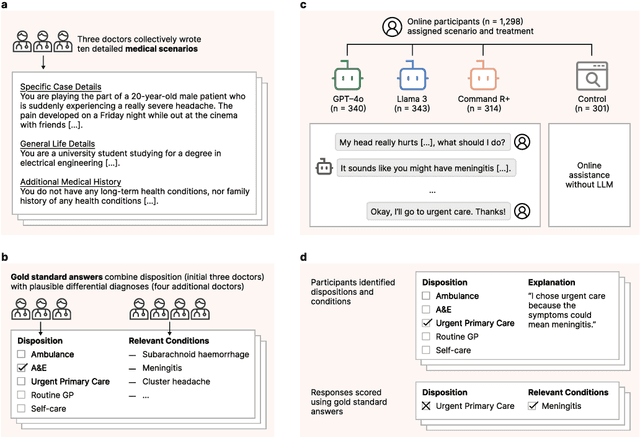

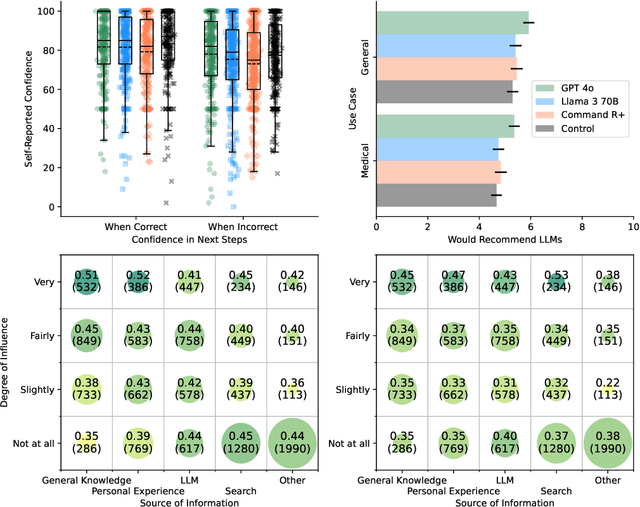
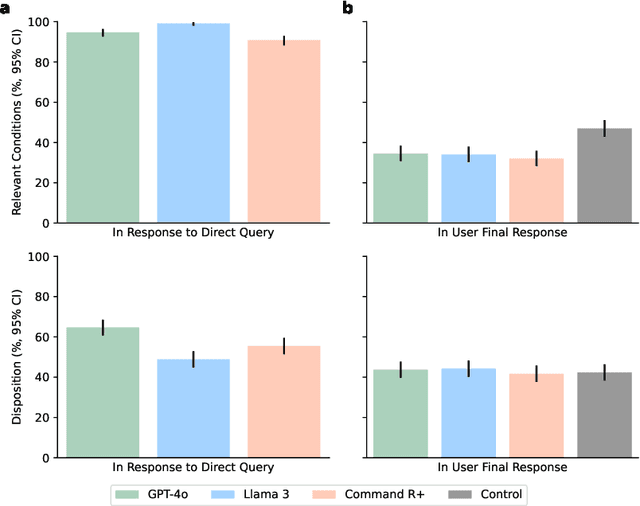
Global healthcare providers are exploring use of large language models (LLMs) to provide medical advice to the public. LLMs now achieve nearly perfect scores on medical licensing exams, but this does not necessarily translate to accurate performance in real-world settings. We tested if LLMs can assist members of the public in identifying underlying conditions and choosing a course of action (disposition) in ten medical scenarios in a controlled study with 1,298 participants. Participants were randomly assigned to receive assistance from an LLM (GPT-4o, Llama 3, Command R+) or a source of their choice (control). Tested alone, LLMs complete the scenarios accurately, correctly identifying conditions in 94.9% of cases and disposition in 56.3% on average. However, participants using the same LLMs identified relevant conditions in less than 34.5% of cases and disposition in less than 44.2%, both no better than the control group. We identify user interactions as a challenge to the deployment of LLMs for medical advice. Standard benchmarks for medical knowledge and simulated patient interactions do not predict the failures we find with human participants. Moving forward, we recommend systematic human user testing to evaluate interactive capabilities prior to public deployments in healthcare.
Characterizing and modeling harms from interactions with design patterns in AI interfaces
Apr 17, 2024The proliferation of applications using artificial intelligence (AI) systems has led to a growing number of users interacting with these systems through sophisticated interfaces. Human-computer interaction research has long shown that interfaces shape both user behavior and user perception of technical capabilities and risks. Yet, practitioners and researchers evaluating the social and ethical risks of AI systems tend to overlook the impact of anthropomorphic, deceptive, and immersive interfaces on human-AI interactions. Here, we argue that design features of interfaces with adaptive AI systems can have cascading impacts, driven by feedback loops, which extend beyond those previously considered. We first conduct a scoping review of AI interface designs and their negative impact to extract salient themes of potentially harmful design patterns in AI interfaces. Then, we propose Design-Enhanced Control of AI systems (DECAI), a conceptual model to structure and facilitate impact assessments of AI interface designs. DECAI draws on principles from control systems theory -- a theory for the analysis and design of dynamic physical systems -- to dissect the role of the interface in human-AI systems. Through two case studies on recommendation systems and conversational language model systems, we show how DECAI can be used to evaluate AI interface designs.
Into the crossfire: evaluating the use of a language model to crowdsource gun violence reports
Jan 16, 2024



Gun violence is a pressing and growing human rights issue that affects nearly every dimension of the social fabric, from healthcare and education to psychology and the economy. Reliable data on firearm events is paramount to developing more effective public policy and emergency responses. However, the lack of comprehensive databases and the risks of in-person surveys prevent human rights organizations from collecting needed data in most countries. Here, we partner with a Brazilian human rights organization to conduct a systematic evaluation of language models to assist with monitoring real-world firearm events from social media data. We propose a fine-tuned BERT-based model trained on Twitter (now X) texts to distinguish gun violence reports from ordinary Portuguese texts. Our model achieves a high AUC score of 0.97. We then incorporate our model into a web application and test it in a live intervention. We study and interview Brazilian analysts who continuously fact-check social media texts to identify new gun violence events. Qualitative assessments show that our solution helped all analysts use their time more efficiently and expanded their search capacities. Quantitative assessments show that the use of our model was associated with more analysts' interactions with online users reporting gun violence. Taken together, our findings suggest that modern Natural Language Processing techniques can help support the work of human rights organizations.
A Linear Reconstruction Approach for Attribute Inference Attacks against Synthetic Data
Jan 24, 2023



Personal data collected at scale from surveys or digital devices offers important insights for statistical analysis and scientific research. Safely sharing such data while protecting privacy is however challenging. Anonymization allows data to be shared while minimizing privacy risks, but traditional anonymization techniques have been repeatedly shown to provide limited protection against re-identification attacks in practice. Among modern anonymization techniques, synthetic data generation (SDG) has emerged as a potential solution to find a good tradeoff between privacy and statistical utility. Synthetic data is typically generated using algorithms that learn the statistical distribution of the original records, to then generate "artificial" records that are structurally and statistically similar to the original ones. Yet, the fact that synthetic records are "artificial" does not, per se, guarantee that privacy is protected. In this work, we systematically evaluate the tradeoffs between protecting privacy and preserving statistical utility for a wide range of synthetic data generation algorithms. Modeling privacy as protection against attribute inference attacks (AIAs), we extend and adapt linear reconstruction attacks, which have not been previously studied in the context of synthetic data. While prior work suggests that AIAs may be effective only on few outlier records, we show they can be very effective even on randomly selected records. We evaluate attacks on synthetic datasets ranging from 10^3 to 10^6 records, showing that even for the same generative model, the attack effectiveness can drastically increase when a larger number of synthetic records is generated. Overall, our findings prove that synthetic data is subject to privacy-utility tradeoffs just like other anonymization techniques: when good utility is preserved, attribute inference can be a risk for many data subjects.