 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond static AI evaluations: advancing human interaction evaluations for LLM harms and risks
Paper and Code
May 17, 2024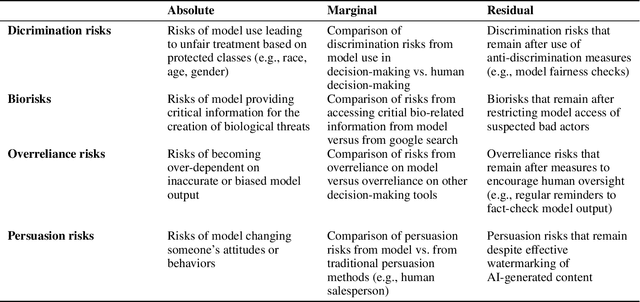
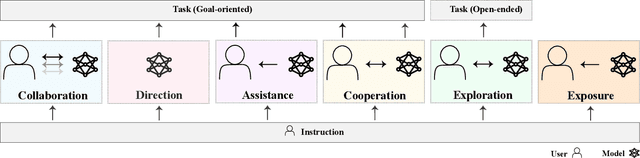
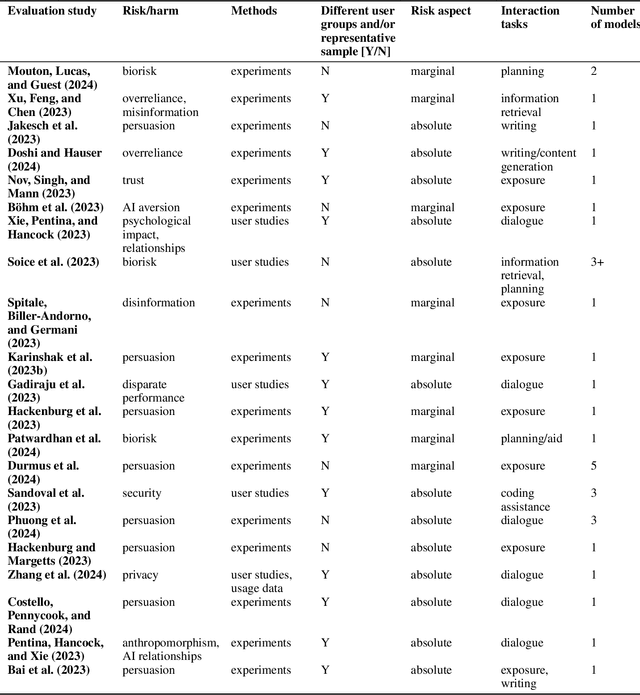
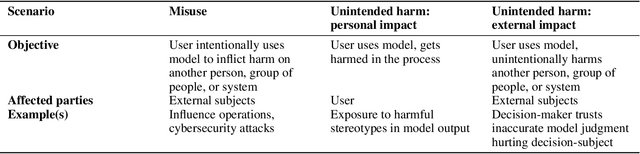
Model evaluations are central to understanding the safety, risks, and societal impacts of AI systems. While most real-world AI applications involve human-AI interaction, most current evaluations (e.g., common benchmarks) of AI models do not. Instead, they incorporate human factors in limited ways, assessing the safety of models in isolation, thereby falling short of capturing the complexity of human-model interactions. In this paper, we discuss and operationalize a definition of an emerging category of evaluations -- "human interaction evaluations" (HIEs) -- which focus on the assessment of human-model interactions or the process and the outcomes of humans using models. First, we argue that HIEs can be used to increase the validity of safety evaluations, assess direct human impact and interaction-specific harms, and guide future assessments of models' societal impact. Second, we propose a safety-focused HIE design framework -- containing a human-LLM interaction taxonomy -- with three stages: (1) identifying the risk or harm area, (2) characterizing the use context, and (3) choosing the evaluation parameters. Third, we apply our framework to two potential evaluations for overreliance and persuasion risks. Finally, we conclude with tangible recommendations for addressing concerns over costs, replicability, and unrepresentativeness of HIEs.