 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in NLP Fine-tuning Methods
May 25, 2022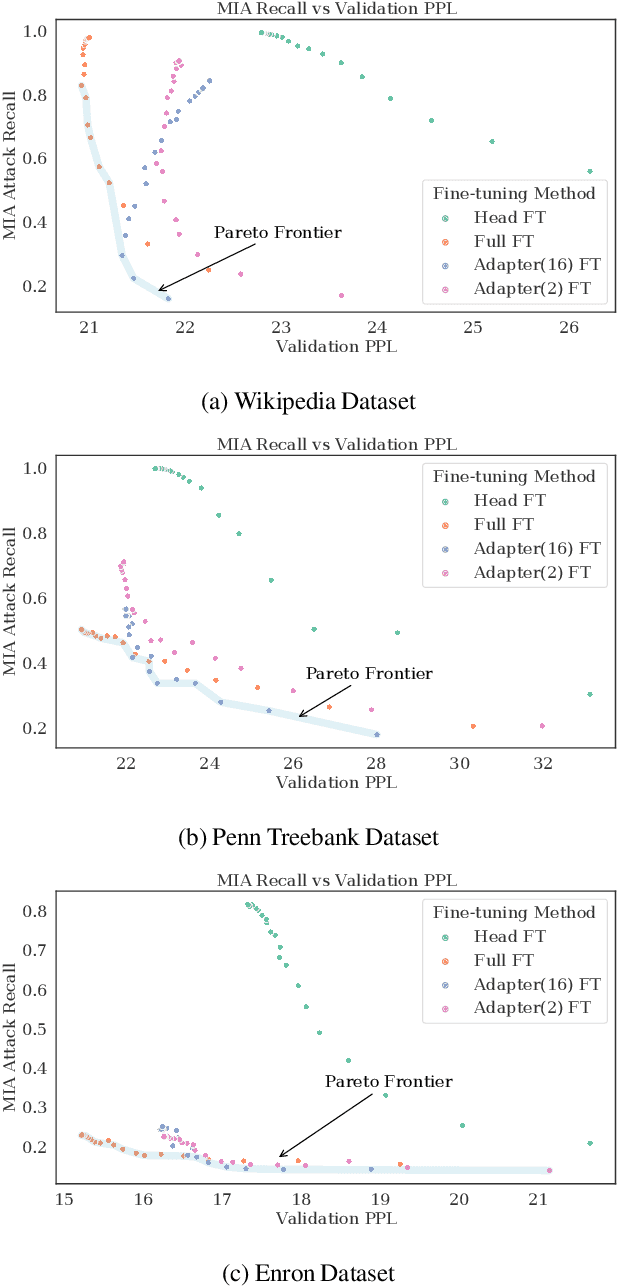
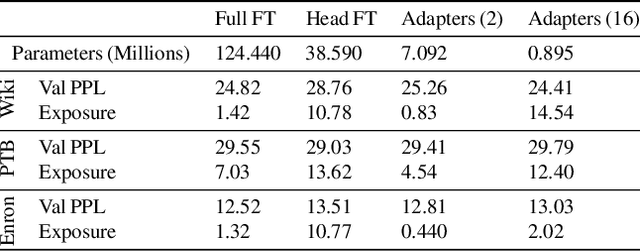
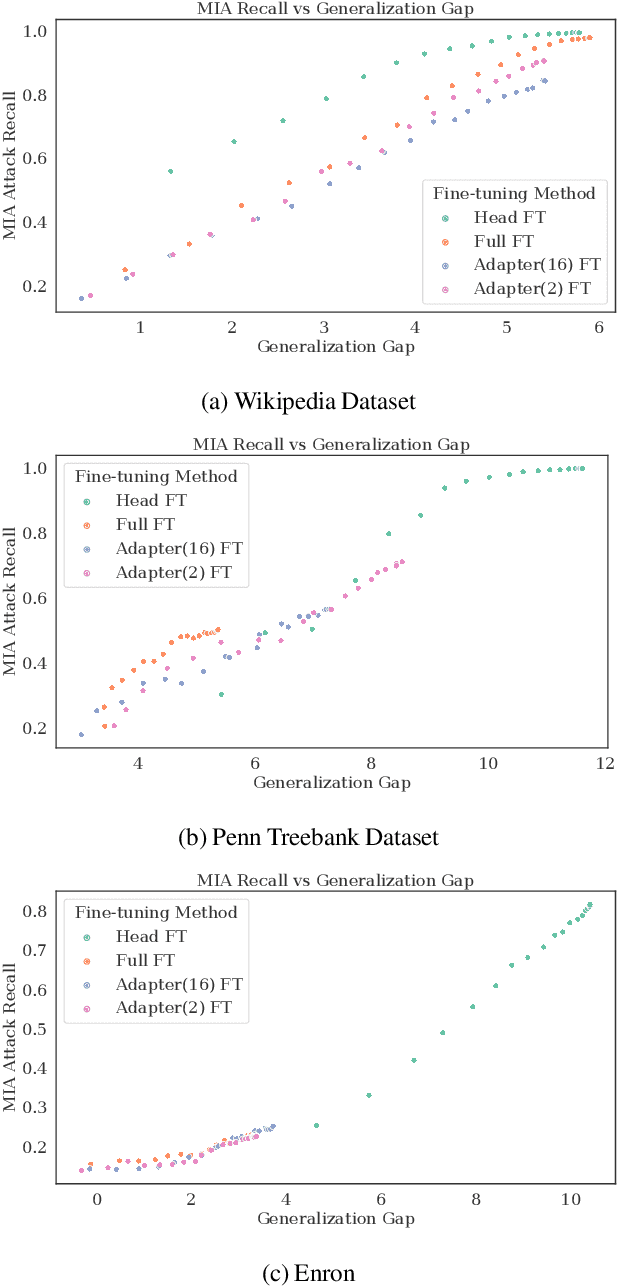

Large language models are shown to present privacy risks through memorization of training data, and several recent works have studied such risks for the pre-training phase. Little attention, however, has been given to the fine-tuning phase and it is not well understood how different fine-tuning methods (such as fine-tuning the full model, the model head, and adapter) compare in terms of memorization risk. This presents increasing concern as the "pre-train and fine-tune" paradigm proliferates. In this paper, we empirically study memorization of fine-tuning methods using membership inference and extraction attacks, and show that their susceptibility to attacks is very different. We observe that fine-tuning the head of the model has the highest susceptibility to attacks, whereas fine-tuning smaller adapters appears to be less vulnerable to known extraction attacks.
Quantifying Privacy Risks of Masked Language Models Using Membership Inference Attacks
Mar 08, 2022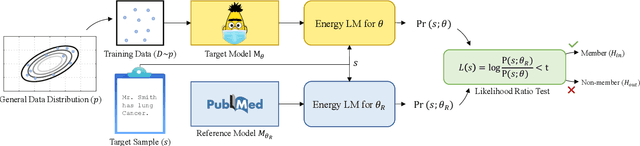


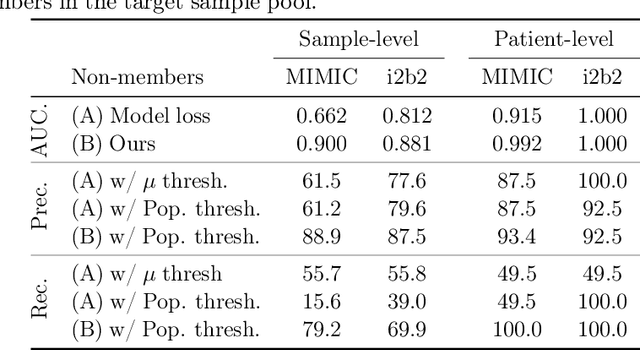
The wide adoption and application of Masked language models~(MLMs) on sensitive data (from legal to medical) necessitates a thorough quantitative investigation into their privacy vulnerabilities -- to what extent do MLMs leak information about their training data? Prior attempts at measuring leakage of MLMs via membership inference attacks have been inconclusive, implying the potential robustness of MLMs to privacy attacks. In this work, we posit that prior attempts were inconclusive because they based their attack solely on the MLM's model score. We devise a stronger membership inference attack based on likelihood ratio hypothesis testing that involves an additional reference MLM to more accurately quantify the privacy risks of memorization in MLMs. We show that masked language models are extremely susceptible to likelihood ratio membership inference attacks: Our empirical results, on models trained on medical notes, show that our attack improves the AUC of prior membership inference attacks from 0.66 to an alarmingly high 0.90 level, with a significant improvement in the low-error region: at 1% false positive rate, our attack is 51X more powerful than prior work.
DP-SGD vs PATE: Which Has Less Disparate Impact on Model Accuracy?
Jun 22, 2021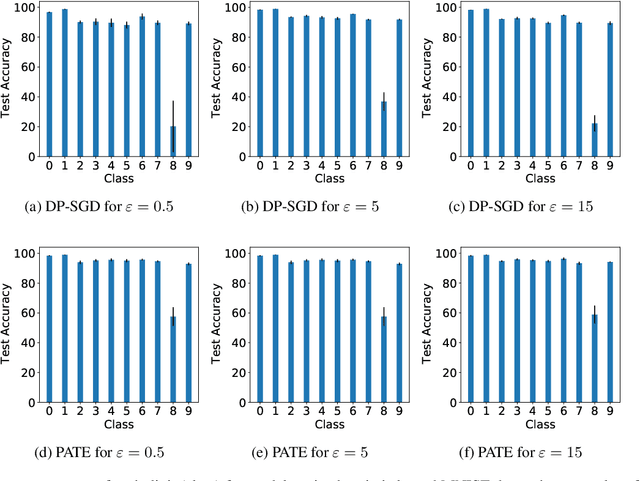
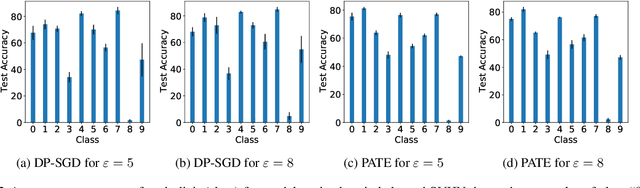
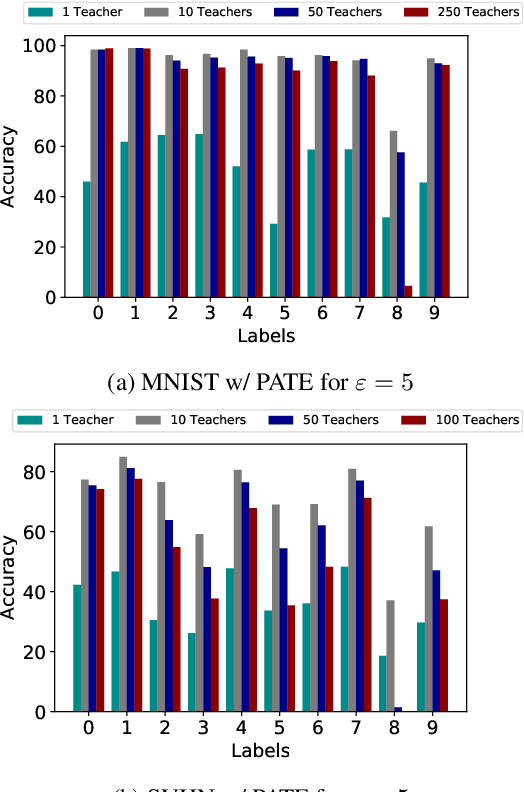
Recent advances in differentially private deep learning have demonstrated that application of differential privacy, specifically the DP-SGD algorithm, has a disparate impact on different sub-groups in the population, which leads to a significantly high drop-in model utility for sub-populations that are under-represented (minorities), compared to well-represented ones. In this work, we aim to compare PATE, another mechanism for training deep learning models using differential privacy, with DP-SGD in terms of fairness. We show that PATE does have a disparate impact too, however, it is much less severe than DP-SGD. We draw insights from this observation on what might be promising directions in achieving better fairness-privacy trade-offs.