 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURFSUP: Learning Fluid Simulation for Novel Surfaces
Apr 13, 2023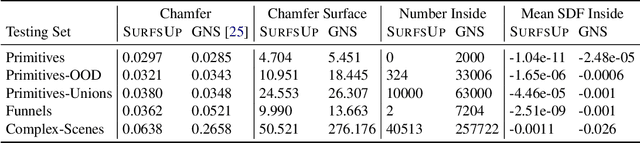
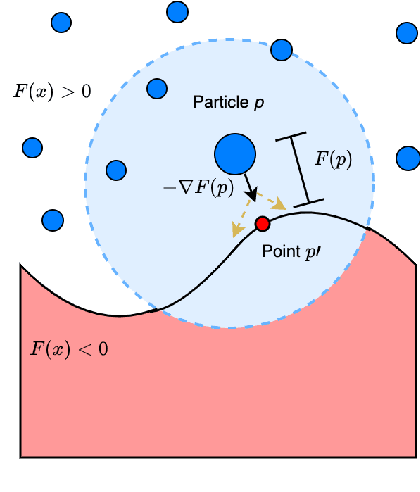
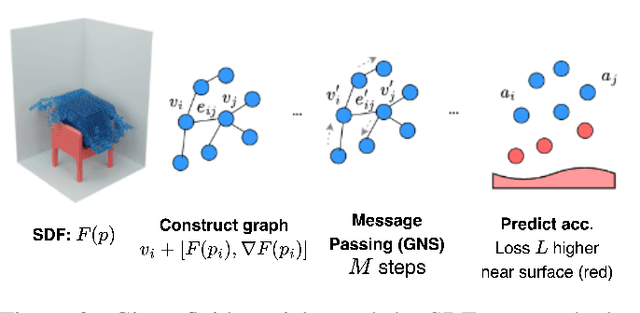

Modeling the mechanics of fluid in complex scenes is vital to applications in design, graphics, and robotics. Learning-based methods provide fast and differentiable fluid simulators, however most prior work is unable to accurately model how fluids interact with genuinely novel surfaces not seen during training. We introduce SURFSUP, a framework that represents objects implicitly using signed distance functions (SDFs), rather than an explicit representation of meshes or particles. This continuous representation of geometry enables more accurate simulation of fluid-object interactions over long time periods while simultaneously making computation more efficient. Moreover, SURFSUP trained on simple shape primitives generalizes considerably out-of-distribution, even to complex real-world scenes and objects. Finally, we show we can invert our model to design simple objects to manipulate fluid flow.
Point and Ask: Incorporating Pointing into Visual Question Answering
Nov 27, 2020
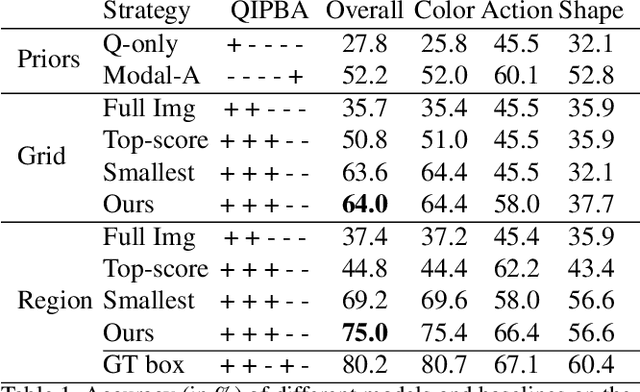


Visual Question Answering (VQA) has become one of the key benchmarks of visual recognition progress. Multiple VQA extensions have been explored to better simulate real-world settings: different question formulations, changing training and test distributions, conversational consistency in dialogues, and explanation-based answering. In this work, we further expand this space by considering visual questions that include a spatial point of reference. Pointing is a nearly universal gesture among humans, and real-world VQA is likely to involve a gesture towards the target region. Concretely, we (1) introduce and motivate point-input questions as an extension of VQA, (2) define three novel classes of questions within this space, and (3) for each class, introduce both a benchmark dataset and a series of baseline models to handle its unique challenges. There are two key distinctions from prior work. First, we explicitly design the benchmarks to require the point input, i.e., we ensure that the visual question cannot be answered accurately without the spatial reference. Second, we explicitly explore the more realistic point spatial input rather than the standard but unnatural bounding box input. Through our exploration we uncover and address several visual recognition challenges, including the ability to infer human intent, reason both locally and globally about the image, and effectively combine visual, language and spatial inputs. Code is available at: https://github.com/princetonvisualai/pointingqa .