 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2D: Detector-to-Differentiable Critic for Improved Numeracy in Text-to-Image Generation
Oct 22, 2025
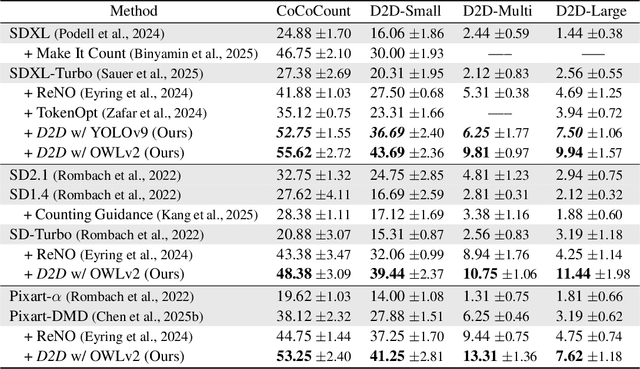
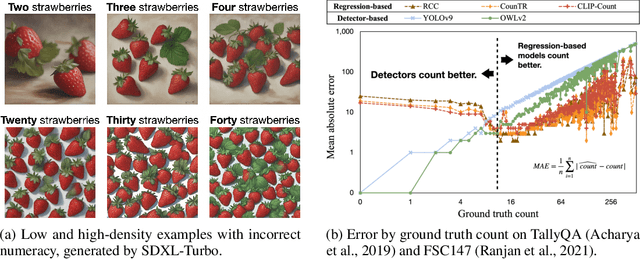
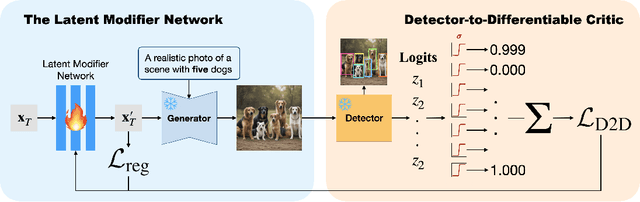
Text-to-image (T2I) diffusion models have achieved strong performance in semantic alignment, yet they still struggle with generating the correct number of objects specified in prompts. Existing approaches typically incorporate auxiliary counting networks as external critics to enhance numeracy. However, since these critics must provide gradient guidance during generation, they are restricted to regression-based models that are inherently differentiable, thus excluding detector-based models with superior counting ability, whose count-via-enumeration nature is non-differentiable. To overcome this limitation, we propose Detector-to-Differentiable (D2D), a novel framework that transforms non-differentiable detection models into differentiable critics, thereby leveraging their superior counting ability to guide numeracy generation. Specifically, we design custom activation functions to convert detector logits into soft binary indicators, which are then used to optimize the noise prior at inference time with pre-trained T2I models. Our extensive experiments on SDXL-Turbo, SD-Turbo, and Pixart-DMD across four benchmarks of varying complexity (low-density, high-density, and multi-object scenarios) demonstrate consistent and substantial improvements in object counting accuracy (e.g., boosting up to 13.7% on D2D-Small, a 400-prompt, low-density benchmark), with minimal degradation in overall image quality and computational overhead.
Efficient, Self-Supervised Human Pose Estimation with Inductive Prior Tuning
Nov 06, 2023The goal of 2D human pose estimation (HPE) is to localize anatomical landmarks, given an image of a person in a pose. SOTA techniques make use of thousands of labeled figures (finetuning transformers or training deep CNNs), acquired using labor-intensive crowdsourcing. On the other hand, self-supervised methods re-frame the HPE task as a reconstruction problem, enabling them to leverage the vast amount of unlabeled visual data, though at the present cost of accuracy. In this work, we explore ways to improve self-supervised HPE. We (1) analyze the relationship between reconstruction quality and pose estimation accuracy, (2) develop a model pipeline that outperforms the baseline which inspired our work, using less than one-third the amount of training data, and (3) offer a new metric suitable for self-supervised settings that measures the consistency of predicted body part length proportions. We show that a combination of well-engineered reconstruction losses and inductive priors can help coordinate pose learning alongside reconstruction in a self-supervised paradigm.
Point and Ask: Incorporating Pointing into Visual Question Answering
Nov 27, 2020
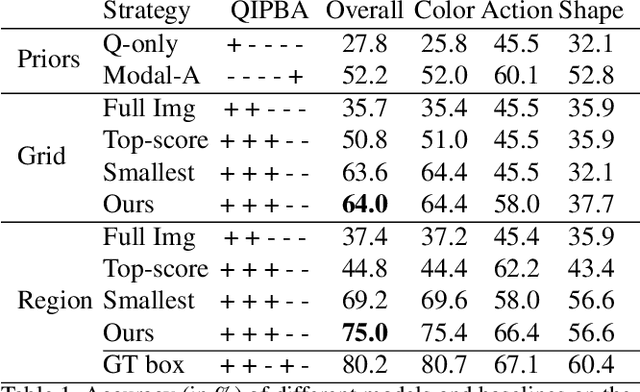


Visual Question Answering (VQA) has become one of the key benchmarks of visual recognition progress. Multiple VQA extensions have been explored to better simulate real-world settings: different question formulations, changing training and test distributions, conversational consistency in dialogues, and explanation-based answering. In this work, we further expand this space by considering visual questions that include a spatial point of reference. Pointing is a nearly universal gesture among humans, and real-world VQA is likely to involve a gesture towards the target region. Concretely, we (1) introduce and motivate point-input questions as an extension of VQA, (2) define three novel classes of questions within this space, and (3) for each class, introduce both a benchmark dataset and a series of baseline models to handle its unique challenges. There are two key distinctions from prior work. First, we explicitly design the benchmarks to require the point input, i.e., we ensure that the visual question cannot be answered accurately without the spatial reference. Second, we explicitly explore the more realistic point spatial input rather than the standard but unnatural bounding box input. Through our exploration we uncover and address several visual recognition challenges, including the ability to infer human intent, reason both locally and globally about the image, and effectively combine visual, language and spatial inputs. Code is available at: https://github.com/princetonvisualai/pointingqa .