 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePluralistic Alignment Over Time
Nov 16, 2024

If an AI system makes decisions over time, how should we evaluate how aligned it is with a group of stakeholders (who may have conflicting values and preferences)? In this position paper, we advocate for consideration of temporal aspects including stakeholders' changing levels of satisfaction and their possibly temporally extended preferences. We suggest how a recent approach to evaluating fairness over time could be applied to a new form of pluralistic alignment: temporal pluralism, where the AI system reflects different stakeholders' values at different times.
Being Considerate as a Pathway Towards Pluralistic Alignment for Agentic AI
Nov 15, 2024Pluralistic alignment is concerned with ensuring that an AI system's objectives and behaviors are in harmony with the diversity of human values and perspectives. In this paper we study the notion of pluralistic alignment in the context of agentic AI, and in particular in the context of an agent that is trying to learn a policy in a manner that is mindful of the values and perspective of others in the environment. To this end, we show how being considerate of the future wellbeing and agency of other (human) agents can promote a form of pluralistic alignment.
Policy Aggregation
Nov 06, 2024We consider the challenge of AI value alignment with multiple individuals that have different reward functions and optimal policies in an underlying Markov decision process. We formalize this problem as one of policy aggregation, where the goal is to identify a desirable collective policy. We argue that an approach informed by social choice theory is especially suitable. Our key insight is that social choice methods can be reinterpreted by identifying ordinal preferences with volumes of subsets of the state-action occupancy polytope. Building on this insight, we demonstrate that a variety of methods--including approval voting, Borda count, the proportional veto core, and quantile fairness--can be practically applied to policy aggregation.
Jump Starting Bandits with LLM-Generated Prior Knowledge
Jun 27, 2024



We present substantial evidence demonstrating the benefits of integrating Large Language Models (LLMs) with a Contextual Multi-Armed Bandit framework. Contextual bandits have been widely used in recommendation systems to generate personalized suggestions based on user-specific contexts. We show that LLMs, pre-trained on extensive corpora rich in human knowledge and preferences, can simulate human behaviours well enough to jump-start contextual multi-armed bandits to reduce online learning regret. We propose an initialization algorithm for contextual bandits by prompting LLMs to produce a pre-training dataset of approximate human preferences for the bandit. This significantly reduces online learning regret and data-gathering costs for training such models. Our approach is validated empirically through two sets of experiments with different bandit setups: one which utilizes LLMs to serve as an oracle and a real-world experiment utilizing data from a conjoint survey experiment.
Remembering to Be Fair: On Non-Markovian Fairness in Sequential DecisionMaking
Dec 08, 2023


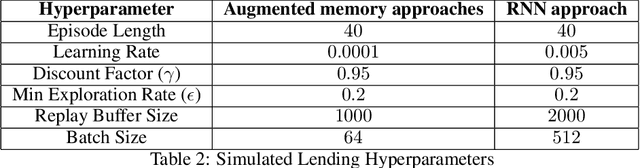
Fair decision making has largely been studied with respect to a single decision. In this paper we investigate the notion of fairness in the context of sequential decision making where multiple stakeholders can be affected by the outcomes of decisions, and where decision making may be informed by additional constraints and criteria beyond the requirement of fairness. In this setting, we observe that fairness often depends on the history of the sequential decision-making process and not just on the current state. To advance our understanding of this class of fairness problems, we define the notion of non-Markovian fairness in the context of sequential decision making. We identify properties of non-Markovian fairness, including notions of long-term, anytime, periodic, and bounded fairness. We further explore the interplay between non-Markovian fairness and memory, and how this can support construction of fair policies in sequential decision-making settings.