 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Evaluation with Few Labels through Post-hoc Regression
Nov 19, 2024


Continually evaluating large generative models provides a unique challenge. Often, human annotations are necessary to evaluate high-level properties of these models (e.g. in text or images). However, collecting human annotations of samples can be resource intensive, and using other machine learning systems to provide the annotations, or automatic evaluation, can introduce systematic errors into the evaluation. The Prediction Powered Inference (PPI) framework provides a way of leveraging both the statistical power of automatic evaluation and a small pool of labelled data to produce a low-variance, unbiased estimate of the quantity being evaluated for. However, most work on PPI considers a relatively sizable set of labelled samples, which is not always practical to obtain. To this end, we present two new PPI-based techniques that leverage robust regressors to produce even lower variance estimators in the few-label regime.
Out of the Ordinary: Spectrally Adapting Regression for Covariate Shift
Dec 29, 2023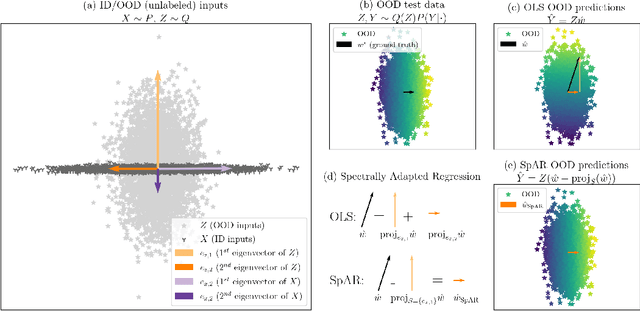
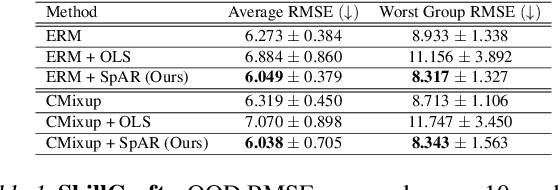
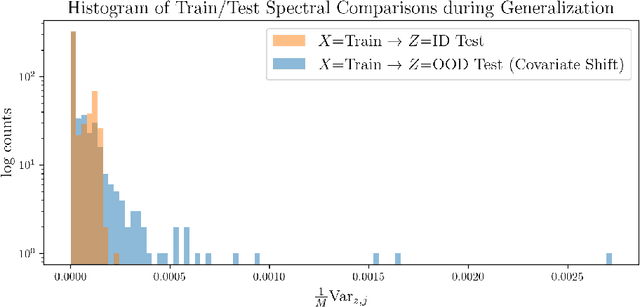

Designing deep neural network classifiers that perform robustly on distributions differing from the available training data is an active area of machine learning research. However, out-of-distribution generalization for regression-the analogous problem for modeling continuous targets-remains relatively unexplored. To tackle this problem, we return to first principles and analyze how the closed-form solution for Ordinary Least Squares (OLS) regression is sensitive to covariate shift. We characterize the out-of-distribution risk of the OLS model in terms of the eigenspectrum decomposition of the source and target data. We then use this insight to propose a method for adapting the weights of the last layer of a pre-trained neural regression model to perform better on input data originating from a different distribution. We demonstrate how this lightweight spectral adaptation procedure can improve out-of-distribution performance for synthetic and real-world datasets.
Fantastic Features and Where to Find Them: Detecting Cognitive Impairment with a Subsequence Classification Guided Approach
Oct 13, 2020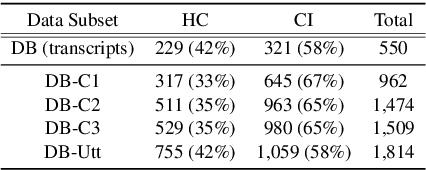

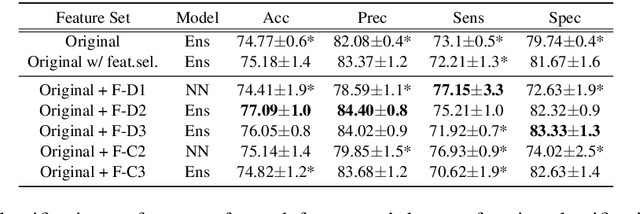

Despite the widely reported success of embedding-based machine learning methods on natural language processing tasks, the use of more easily interpreted engineered features remains common in fields such as cognitive impairment (CI) detection. Manually engineering features from noisy text is time and resource consuming, and can potentially result in features that do not enhance model performance. To combat this, we describe a new approach to feature engineering that leverages sequential machine learning models and domain knowledge to predict which features help enhance performance. We provide a concrete example of this method on a standard data set of CI speech and demonstrate that CI classification accuracy improves by 2.3% over a strong baseline when using features produced by this method. This demonstration provides an ex-ample of how this method can be used to assist classification in fields where interpretability is important, such as health care.
To BERT or Not To BERT: Comparing Speech and Language-based Approaches for Alzheimer's Disease Detection
Jul 26, 2020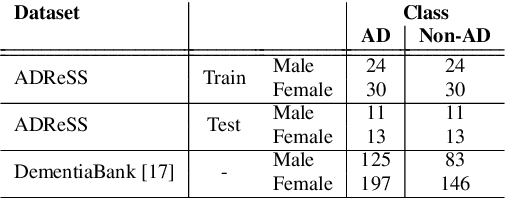


Research related to automatically detecting Alzheimer's disease (AD) is important, given the high prevalence of AD and the high cost of traditional methods. Since AD significantly affects the content and acoustics of spontaneous speech, natural language processing and machine learning provide promising techniques for reliably detecting AD. We compare and contrast the performance of two such approaches for AD detection on the recent ADReSS challenge dataset: 1) using domain knowledge-based hand-crafted features that capture linguistic and acoustic phenomena, and 2) fine-tuning Bidirectional Encoder Representations from Transformer (BERT)-based sequence classification models. We also compare multiple feature-based regression models for a neuropsychological score task in the challenge. We observe that fine-tuned BERT models, given the relative importance of linguistics in cognitive impairment detection, outperform feature-based approaches on the AD detection task.