 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFantastic Features and Where to Find Them: Detecting Cognitive Impairment with a Subsequence Classification Guided Approach
Paper and Code
Oct 13, 2020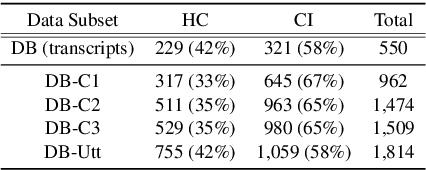

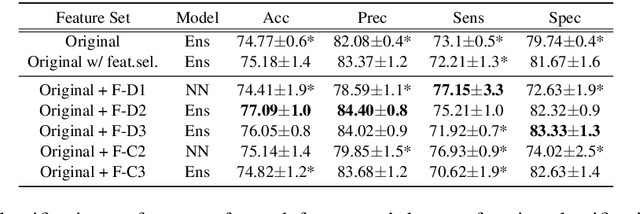

Despite the widely reported success of embedding-based machine learning methods on natural language processing tasks, the use of more easily interpreted engineered features remains common in fields such as cognitive impairment (CI) detection. Manually engineering features from noisy text is time and resource consuming, and can potentially result in features that do not enhance model performance. To combat this, we describe a new approach to feature engineering that leverages sequential machine learning models and domain knowledge to predict which features help enhance performance. We provide a concrete example of this method on a standard data set of CI speech and demonstrate that CI classification accuracy improves by 2.3% over a strong baseline when using features produced by this method. This demonstration provides an ex-ample of how this method can be used to assist classification in fields where interpretability is important, such as health care.