 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
Dec 12, 2025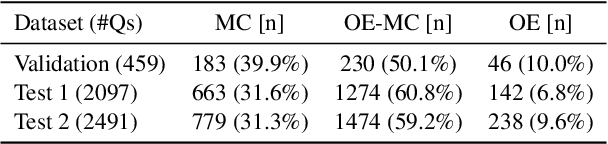
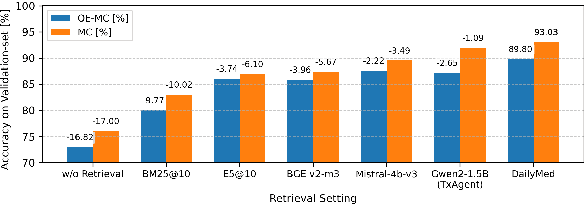
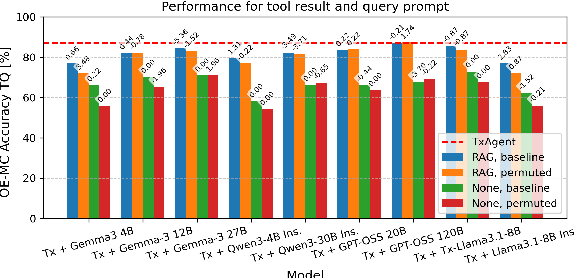
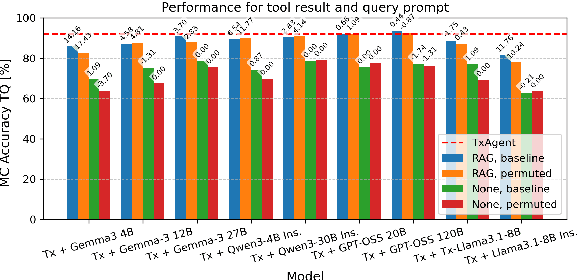
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals. This work presents insights derived from our participation in the CURE-Bench NeurIPS 2025 Challenge, which benchmarks therapeutic-reasoning systems using metrics that assess correctness, tool utilization, and reasoning quality. We analyze how retrieval quality for function (tool) calls influences overall model performance and demonstrate performance gains achieved through improved tool-retrieval strategies. Our work was awarded the Excellence Award in Open Science. Complete information can be found at https://curebench.ai/.
FlexTSF: A Universal Forecasting Model for Time Series with Variable Regularities
Oct 30, 2024Developing a foundation model for time series forecasting across diverse domains has attracted significant attention in recent years. Existing works typically assume regularly sampled, well-structured data, limiting their applicability to more generalized scenarios where time series often contain missing values, unequal sequence lengths, and irregular time intervals between measurements. To cover diverse domains and handle variable regularities, we propose FlexTSF, a universal time series forecasting model that possesses better generalization and natively support both regular and irregular time series. FlexTSF produces forecasts in an autoregressive manner and incorporates three novel designs: VT-Norm, a normalization strategy to ablate data domain barriers, IVP Patcher, a patching module to learn representations from flexibly structured time series, and LED attention, an attention mechanism to seamlessly integrate these two and propagate forecasts with awareness of domain and time information. Experiments on 12 datasets show that FlexTSF outperforms state-of-the-art forecasting models respectively designed for regular and irregular time series. Furthermore, after self-supervised pre-training, FlexTSF shows exceptional performance in both zero-shot and few-show settings for time series forecasting.
IVP-VAE: Modeling EHR Time Series with Initial Value Problem Solvers
May 11, 2023Continuous-time models such as Neural ODEs and Neural Flows have shown promising results in analyzing irregularly sampled time series frequently encountered in electronic health records. Based on these models, time series are typically processed with a hybrid of an initial value problem (IVP) solver and a recurrent neural network within the variational autoencoder architecture. Sequentially solving IVPs makes such models computationally less efficient. In this paper, we propose to model time series purely with continuous processes whose state evolution can be approximated directly by IVPs. This eliminates the need for recurrent computation and enables multiple states to evolve in parallel. We further fuse the encoder and decoder with one IVP solver based on its invertibility, which leads to fewer parameters and faster convergence. Experiments on three real-world datasets show that the proposed approach achieves comparable extrapolation and classification performance while gaining more than one order of magnitude speedup over other continuous-time counterparts.