 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan a Hallucinating Model help in Reducing Human "Hallucination"?
May 01, 2024The prevalence of unwarranted beliefs, spanning pseudoscience, logical fallacies, and conspiracy theories, presents substantial societal hurdles and the risk of disseminating misinformation. Utilizing established psychometric assessments, this study explores the capabilities of large language models (LLMs) vis-a-vis the average human in detecting prevalent logical pitfalls. We undertake a philosophical inquiry, juxtaposing the rationality of humans against that of LLMs. Furthermore, we propose methodologies for harnessing LLMs to counter misconceptions, drawing upon psychological models of persuasion such as cognitive dissonance theory and elaboration likelihood theory. Through this endeavor, we highlight the potential of LLMs as personalized misinformation debunking agents.
GeneMask: Fast Pretraining of Gene Sequences to Enable Few-Shot Learning
Jul 29, 2023Large-scale language models such as DNABert and LOGO aim to learn optimal gene representations and are trained on the entire Human Reference Genome. However, standard tokenization schemes involve a simple sliding window of tokens like k-mers that do not leverage any gene-based semantics and thus may lead to (trivial) masking of easily predictable sequences and subsequently inefficient Masked Language Modeling (MLM) training. Therefore, we propose a novel masking algorithm, GeneMask, for MLM training of gene sequences, where we randomly identify positions in a gene sequence as mask centers and locally select the span around the mask center with the highest Normalized Pointwise Mutual Information (NPMI) to mask. We observe that in the absence of human-understandable semantics in the genomics domain (in contrast, semantic units like words and phrases are inherently available in NLP), GeneMask-based models substantially outperform the SOTA models (DNABert and LOGO) over four benchmark gene sequence classification datasets in five few-shot settings (10 to 1000-shot). More significantly, the GeneMask-based DNABert model is trained for less than one-tenth of the number of epochs of the original SOTA model. We also observe a strong correlation between top-ranked PMI tokens and conserved DNA sequence motifs, which may indicate the incorporation of latent genomic information. The codes (including trained models) and datasets are made publicly available at https://github.com/roysoumya/GeneMask.
Why are NLP Models Fumbling at Elementary Math? A Survey of Deep Learning based Word Problem Solvers
May 31, 2022
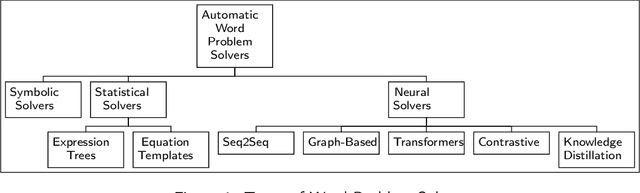

From the latter half of the last decade, there has been a growing interest in developing algorithms for automatically solving mathematical word problems (MWP). It is a challenging and unique task that demands blending surface level text pattern recognition with mathematical reasoning. In spite of extensive research, we are still miles away from building robust representations of elementary math word problems and effective solutions for the general task. In this paper, we critically examine the various models that have been developed for solving word problems, their pros and cons and the challenges ahead. In the last two years, a lot of deep learning models have recorded competing results on benchmark datasets, making a critical and conceptual analysis of literature highly useful at this juncture. We take a step back and analyse why, in spite of this abundance in scholarly interest, the predominantly used experiment and dataset designs continue to be a stumbling block. From the vantage point of having analyzed the literature closely, we also endeavour to provide a road-map for future math word problem research.
FiSH: Fair Spatial Hotspots
Jun 01, 2021

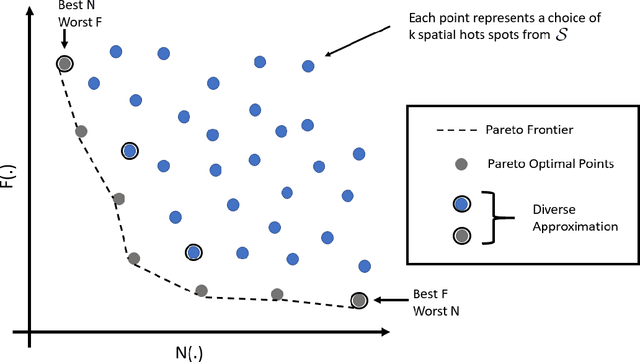
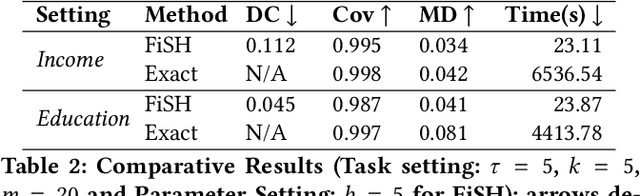
Pervasiveness of tracking devices and enhanced availability of spatially located data has deepened interest in using them for various policy interventions, through computational data analysis tasks such as spatial hot spot detection. In this paper, we consider, for the first time to our best knowledge, fairness in detecting spatial hot spots. We motivate the need for ensuring fairness through statistical parity over the collective population covered across chosen hot spots. We then characterize the task of identifying a diverse set of solutions in the noteworthiness-fairness trade-off spectrum, to empower the user to choose a trade-off justified by the policy domain. Being a novel task formulation, we also develop a suite of evaluation metrics for fair hot spots, motivated by the need to evaluate pertinent aspects of the task. We illustrate the computational infeasibility of identifying fair hot spots using naive and/or direct approaches and devise a method, codenamed {\it FiSH}, for efficiently identifying high-quality, fair and diverse sets of spatial hot spots. FiSH traverses the tree-structured search space using heuristics that guide it towards identifying effective and fair sets of spatial hot spots. Through an extensive empirical analysis over a real-world dataset from the domain of human development, we illustrate that FiSH generates high-quality solutions at fast response times.
Fairness in Clustering with Multiple Sensitive Attributes
Oct 11, 2019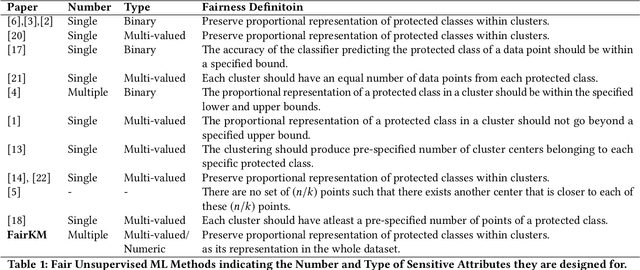
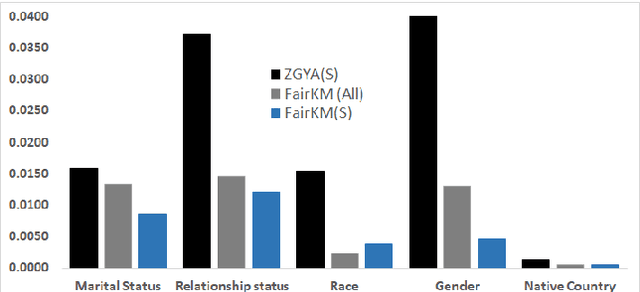

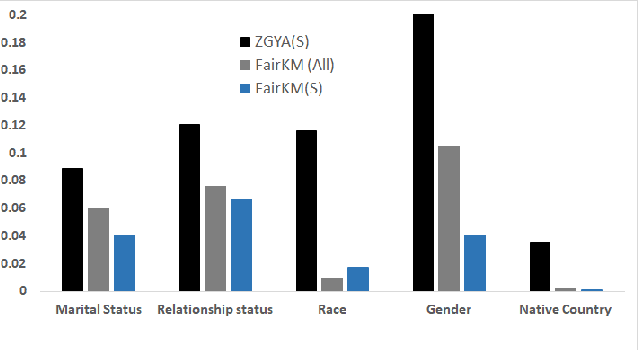
A clustering may be considered as fair on pre-specified sensitive attributes if the proportions of sensitive attribute groups in each cluster reflect that in the dataset. In this paper, we consider the task of fair clustering for scenarios involving multiple multi-valued or numeric sensitive attributes. We propose a fair clustering method, FairKM (Fair K-Means), that is inspired by the popular K-Means clustering formulation. We outline a computational notion of fairness which is used along with a cluster coherence objective, to yield the FairKM clustering method. We empirically evaluate our approach, wherein we quantify both the quality and fairness of clusters, over real-world datasets. Our experimental evaluation illustrates that the clusters generated by FairKM fare significantly better on both clustering quality and fair representation of sensitive attribute groups compared to the clusters from a state-of-the-art baseline fair clustering method.