 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEVR-POC: Reasoning-Intensive Visual Question Answering in Partially Observable Environments
Mar 05, 2024The integration of learning and reasoning is high on the research agenda in AI. Nevertheless, there is only a little attention to use existing background knowledge for reasoning about partially observed scenes to answer questions about the scene. Yet, we as humans use such knowledge frequently to infer plausible answers to visual questions (by eliminating all inconsistent ones). Such knowledge often comes in the form of constraints about objects and it tends to be highly domain or environment-specific. We contribute a novel benchmark called CLEVR-POC for reasoning-intensive visual question answering (VQA) in partially observable environments under constraints. In CLEVR-POC, knowledge in the form of logical constraints needs to be leveraged to generate plausible answers to questions about a hidden object in a given partial scene. For instance, if one has the knowledge that all cups are colored either red, green or blue and that there is only one green cup, it becomes possible to deduce the color of an occluded cup as either red or blue, provided that all other cups, including the green one, are observed. Through experiments, we observe that the low performance of pre-trained vision language models like CLIP (~ 22%) and a large language model (LLM) like GPT-4 (~ 46%) on CLEVR-POC ascertains the necessity for frameworks that can handle reasoning-intensive tasks where environment-specific background knowledge is available and crucial. Furthermore, our demonstration illustrates that a neuro-symbolic model, which integrates an LLM like GPT-4 with a visual perception network and a formal logical reasoner, exhibits exceptional performance on CLEVR-POC.
REDAffectiveLM: Leveraging Affect Enriched Embedding and Transformer-based Neural Language Model for Readers' Emotion Detection
Jan 21, 2023Technological advancements in web platforms allow people to express and share emotions towards textual write-ups written and shared by others. This brings about different interesting domains for analysis; emotion expressed by the writer and emotion elicited from the readers. In this paper, we propose a novel approach for Readers' Emotion Detection from short-text documents using a deep learning model called REDAffectiveLM. Within state-of-the-art NLP tasks, it is well understood that utilizing context-specific representations from transformer-based pre-trained language models helps achieve improved performance. Within this affective computing task, we explore how incorporating affective information can further enhance performance. Towards this, we leverage context-specific and affect enriched representations by using a transformer-based pre-trained language model in tandem with affect enriched Bi-LSTM+Attention. For empirical evaluation, we procure a new dataset REN-20k, besides using RENh-4k and SemEval-2007. We evaluate the performance of our REDAffectiveLM rigorously across these datasets, against a vast set of state-of-the-art baselines, where our model consistently outperforms baselines and obtains statistically significant results. Our results establish that utilizing affect enriched representation along with context-specific representation within a neural architecture can considerably enhance readers' emotion detection. Since the impact of affect enrichment specifically in readers' emotion detection isn't well explored, we conduct a detailed analysis over affect enriched Bi-LSTM+Attention using qualitative and quantitative model behavior evaluation techniques. We observe that compared to conventional semantic embedding, affect enriched embedding increases ability of the network to effectively identify and assign weightage to key terms responsible for readers' emotion detection.
CLEVR-Math: A Dataset for Compositional Language, Visual and Mathematical Reasoning
Aug 10, 2022


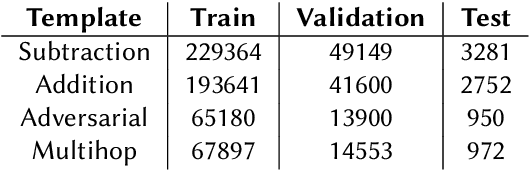
We introduce CLEVR-Math, a multi-modal math word problems dataset consisting of simple math word problems involving addition/subtraction, represented partly by a textual description and partly by an image illustrating the scenario. The text describes actions performed on the scene that is depicted in the image. Since the question posed may not be about the scene in the image, but about the state of the scene before or after the actions are applied, the solver envision or imagine the state changes due to these actions. Solving these word problems requires a combination of language, visual and mathematical reasoning. We apply state-of-the-art neural and neuro-symbolic models for visual question answering on CLEVR-Math and empirically evaluate their performances. Our results show how neither method generalise to chains of operations. We discuss the limitations of the two in addressing the task of multi-modal word problem solving.
Why are NLP Models Fumbling at Elementary Math? A Survey of Deep Learning based Word Problem Solvers
May 31, 2022
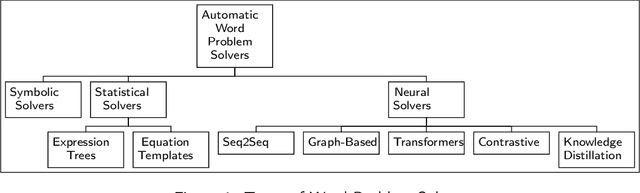

From the latter half of the last decade, there has been a growing interest in developing algorithms for automatically solving mathematical word problems (MWP). It is a challenging and unique task that demands blending surface level text pattern recognition with mathematical reasoning. In spite of extensive research, we are still miles away from building robust representations of elementary math word problems and effective solutions for the general task. In this paper, we critically examine the various models that have been developed for solving word problems, their pros and cons and the challenges ahead. In the last two years, a lot of deep learning models have recorded competing results on benchmark datasets, making a critical and conceptual analysis of literature highly useful at this juncture. We take a step back and analyse why, in spite of this abundance in scholarly interest, the predominantly used experiment and dataset designs continue to be a stumbling block. From the vantage point of having analyzed the literature closely, we also endeavour to provide a road-map for future math word problem research.
Representativity Fairness in Clustering
Oct 11, 2020
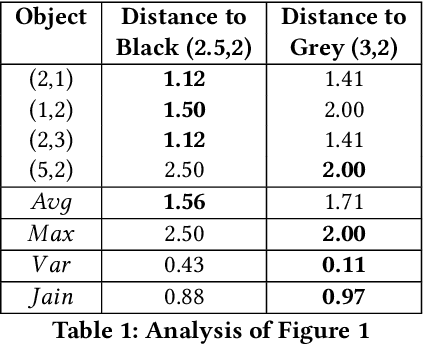
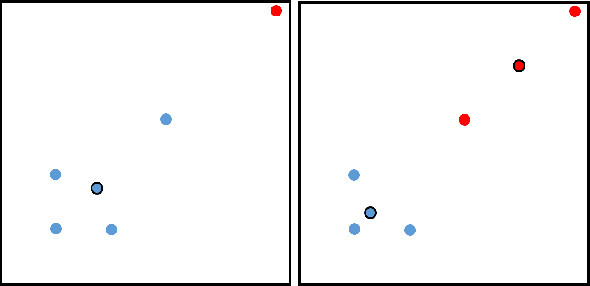

Incorporating fairness constructs into machine learning algorithms is a topic of much societal importance and recent interest. Clustering, a fundamental task in unsupervised learning that manifests across a number of web data scenarios, has also been subject of attention within fair ML research. In this paper, we develop a novel notion of fairness in clustering, called representativity fairness. Representativity fairness is motivated by the need to alleviate disparity across objects' proximity to their assigned cluster representatives, to aid fairer decision making. We illustrate the importance of representativity fairness in real-world decision making scenarios involving clustering and provide ways of quantifying objects' representativity and fairness over it. We develop a new clustering formulation, RFKM, that targets to optimize for representativity fairness along with clustering quality. Inspired by the $K$-Means framework, RFKM incorporates novel loss terms to formulate an objective function. The RFKM objective and optimization approach guides it towards clustering configurations that yield higher representativity fairness. Through an empirical evaluation over a variety of public datasets, we establish the effectiveness of our method. We illustrate that we are able to significantly improve representativity fairness at only marginal impact to clustering quality.
Fair Outlier Detection
May 20, 2020

An outlier detection method may be considered fair over specified sensitive attributes if the results of outlier detection are not skewed towards particular groups defined on such sensitive attributes. In this task, we consider, for the first time to our best knowledge, the task of fair outlier detection. In this work, we consider the task of fair outlier detection over multiple multi-valued sensitive attributes (e.g., gender, race, religion, nationality, marital status etc.). We propose a fair outlier detection method, FairLOF, that is inspired by the popular LOF formulation for neighborhood-based outlier detection. We outline ways in which unfairness could be induced within LOF and develop three heuristic principles to enhance fairness, which form the basis of the FairLOF method. Being a novel task, we develop an evaluation framework for fair outlier detection, and use that to benchmark FairLOF on quality and fairness of results. Through an extensive empirical evaluation over real-world datasets, we illustrate that FairLOF is able to achieve significant improvements in fairness at sometimes marginal degradations on result quality as measured against the fairness-agnostic LOF method.
Fairness in Clustering with Multiple Sensitive Attributes
Oct 11, 2019
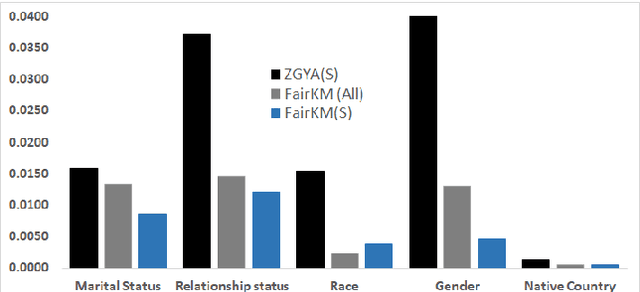

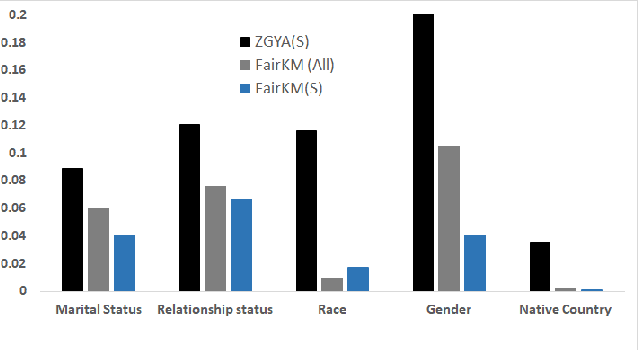
A clustering may be considered as fair on pre-specified sensitive attributes if the proportions of sensitive attribute groups in each cluster reflect that in the dataset. In this paper, we consider the task of fair clustering for scenarios involving multiple multi-valued or numeric sensitive attributes. We propose a fair clustering method, FairKM (Fair K-Means), that is inspired by the popular K-Means clustering formulation. We outline a computational notion of fairness which is used along with a cluster coherence objective, to yield the FairKM clustering method. We empirically evaluate our approach, wherein we quantify both the quality and fairness of clusters, over real-world datasets. Our experimental evaluation illustrates that the clusters generated by FairKM fare significantly better on both clustering quality and fair representation of sensitive attribute groups compared to the clusters from a state-of-the-art baseline fair clustering method.