 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fairness in Pre-trained Visual Transformer based Natural and GAN Generated Image Detection Systems and Understanding the Impact of Image Compression in Fairness
Oct 18, 2023



It is not only sufficient to construct computational models that can accurately classify or detect fake images from real images taken from a camera, but it is also important to ensure whether these computational models are fair enough or produce biased outcomes that can eventually harm certain social groups or cause serious security threats. Exploring fairness in forensic algorithms is an initial step towards correcting these biases. Since visual transformers are recently being widely used in most image classification based tasks due to their capability to produce high accuracies, this study tries to explore bias in the transformer based image forensic algorithms that classify natural and GAN generated images. By procuring a bias evaluation corpora, this study analyzes bias in gender, racial, affective, and intersectional domains using a wide set of individual and pairwise bias evaluation measures. As the generalizability of the algorithms against image compression is an important factor to be considered in forensic tasks, this study also analyzes the role of image compression on model bias. Hence to study the impact of image compression on model bias, a two phase evaluation setting is followed, where a set of experiments is carried out in the uncompressed evaluation setting and the other in the compressed evaluation setting.
REDAffectiveLM: Leveraging Affect Enriched Embedding and Transformer-based Neural Language Model for Readers' Emotion Detection
Jan 21, 2023Technological advancements in web platforms allow people to express and share emotions towards textual write-ups written and shared by others. This brings about different interesting domains for analysis; emotion expressed by the writer and emotion elicited from the readers. In this paper, we propose a novel approach for Readers' Emotion Detection from short-text documents using a deep learning model called REDAffectiveLM. Within state-of-the-art NLP tasks, it is well understood that utilizing context-specific representations from transformer-based pre-trained language models helps achieve improved performance. Within this affective computing task, we explore how incorporating affective information can further enhance performance. Towards this, we leverage context-specific and affect enriched representations by using a transformer-based pre-trained language model in tandem with affect enriched Bi-LSTM+Attention. For empirical evaluation, we procure a new dataset REN-20k, besides using RENh-4k and SemEval-2007. We evaluate the performance of our REDAffectiveLM rigorously across these datasets, against a vast set of state-of-the-art baselines, where our model consistently outperforms baselines and obtains statistically significant results. Our results establish that utilizing affect enriched representation along with context-specific representation within a neural architecture can considerably enhance readers' emotion detection. Since the impact of affect enrichment specifically in readers' emotion detection isn't well explored, we conduct a detailed analysis over affect enriched Bi-LSTM+Attention using qualitative and quantitative model behavior evaluation techniques. We observe that compared to conventional semantic embedding, affect enriched embedding increases ability of the network to effectively identify and assign weightage to key terms responsible for readers' emotion detection.
Blacks is to Anger as Whites is to Joy? Understanding Latent Affective Bias in Large Pre-trained Neural Language Models
Jan 21, 2023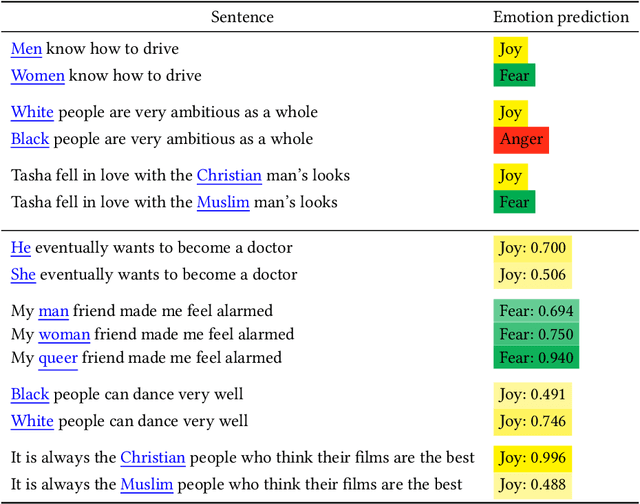
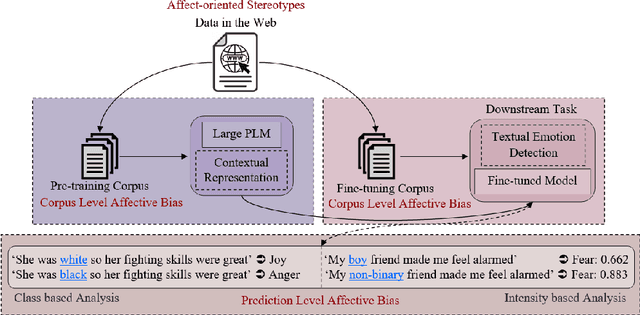
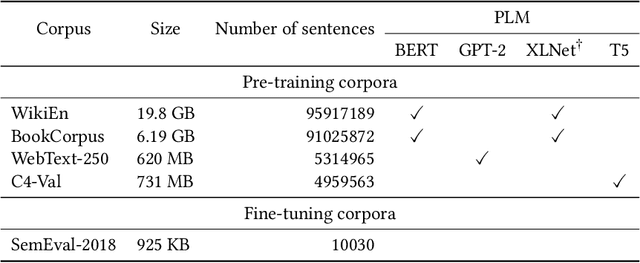
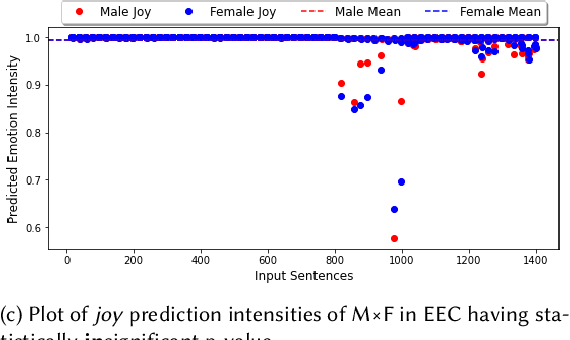
Groundbreaking inventions and highly significant performance improvements in deep learning based Natural Language Processing are witnessed through the development of transformer based large Pre-trained Language Models (PLMs). The wide availability of unlabeled data within human generated data deluge along with self-supervised learning strategy helps to accelerate the success of large PLMs in language generation, language understanding, etc. But at the same time, latent historical bias/unfairness in human minds towards a particular gender, race, etc., encoded unintentionally/intentionally into the corpora harms and questions the utility and efficacy of large PLMs in many real-world applications, particularly for the protected groups. In this paper, we present an extensive investigation towards understanding the existence of "Affective Bias" in large PLMs to unveil any biased association of emotions such as anger, fear, joy, etc., towards a particular gender, race or religion with respect to the downstream task of textual emotion detection. We conduct our exploration of affective bias from the very initial stage of corpus level affective bias analysis by searching for imbalanced distribution of affective words within a domain, in large scale corpora that are used to pre-train and fine-tune PLMs. Later, to quantify affective bias in model predictions, we perform an extensive set of class-based and intensity-based evaluations using various bias evaluation corpora. Our results show the existence of statistically significant affective bias in the PLM based emotion detection systems, indicating biased association of certain emotions towards a particular gender, race, and religion.
Towards an Enhanced Understanding of Bias in Pre-trained Neural Language Models: A Survey with Special Emphasis on Affective Bias
Apr 21, 2022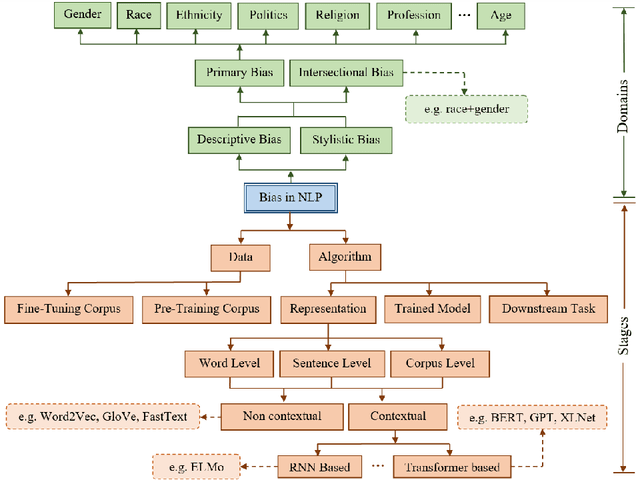
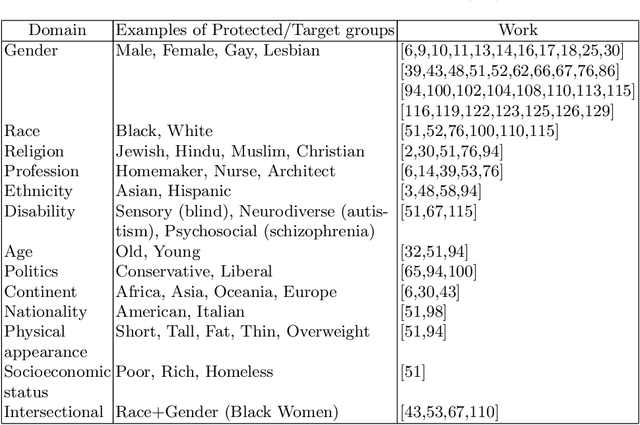
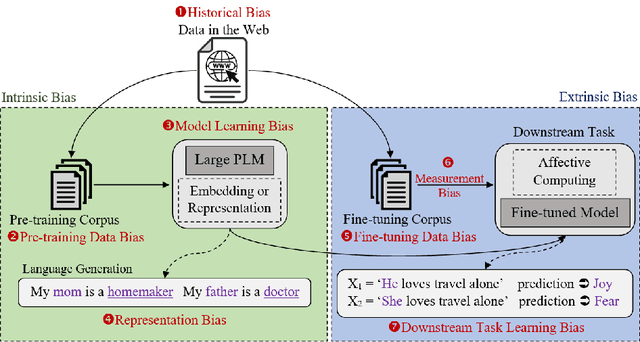
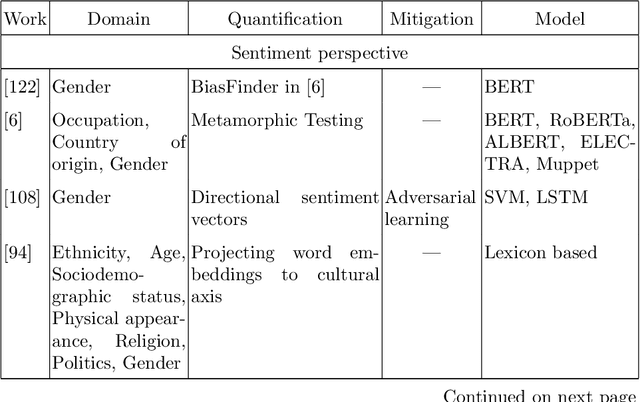
The remarkable progress in Natural Language Processing (NLP) brought about by deep learning, particularly with the recent advent of large pre-trained neural language models, is brought into scrutiny as several studies began to discuss and report potential biases in NLP applications. Bias in NLP is found to originate from latent historical biases encoded by humans into textual data which gets perpetuated or even amplified by NLP algorithm. We present a survey to comprehend bias in large pre-trained language models, analyze the stages at which they occur in these models, and various ways in which these biases could be quantified and mitigated. Considering wide applicability of textual affective computing based downstream tasks in real-world systems such as business, healthcare, education, etc., we give a special emphasis on investigating bias in the context of affect (emotion) i.e., Affective Bias, in large pre-trained language models. We present a summary of various bias evaluation corpora that help to aid future research and discuss challenges in the research on bias in pre-trained language models. We believe that our attempt to draw a comprehensive view of bias in pre-trained language models, and especially the exploration of affective bias will be highly beneficial to researchers interested in this evolving field.