 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Enhanced Understanding of Bias in Pre-trained Neural Language Models: A Survey with Special Emphasis on Affective Bias
Paper and Code
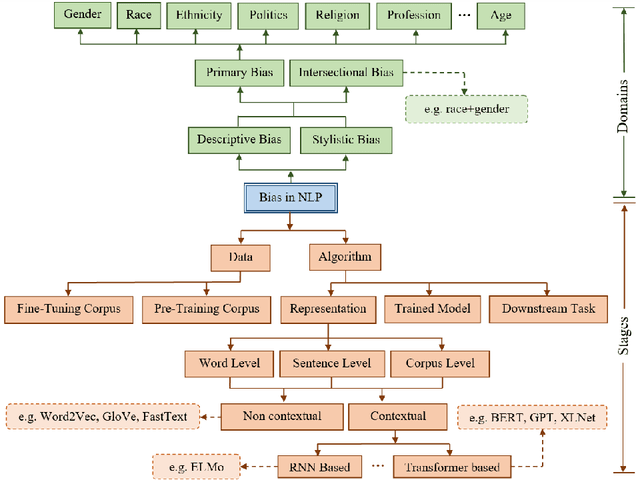
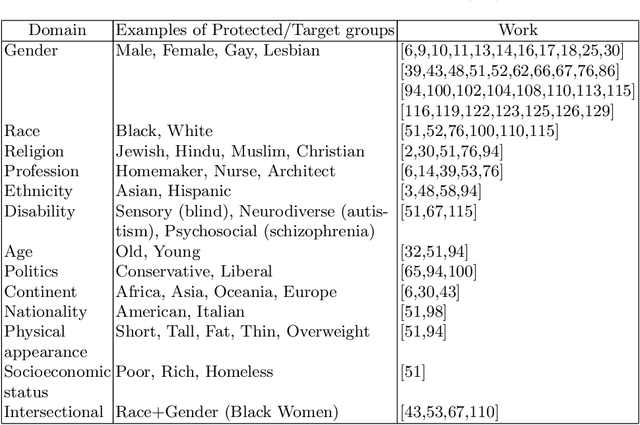
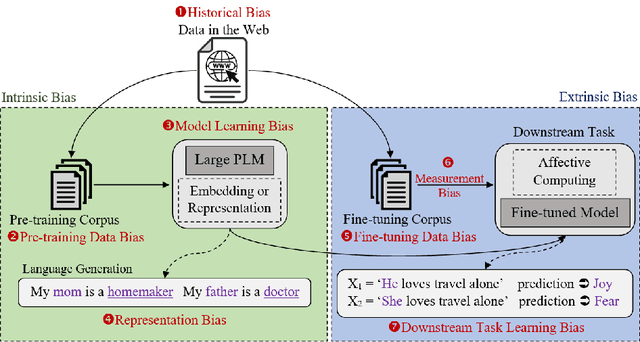
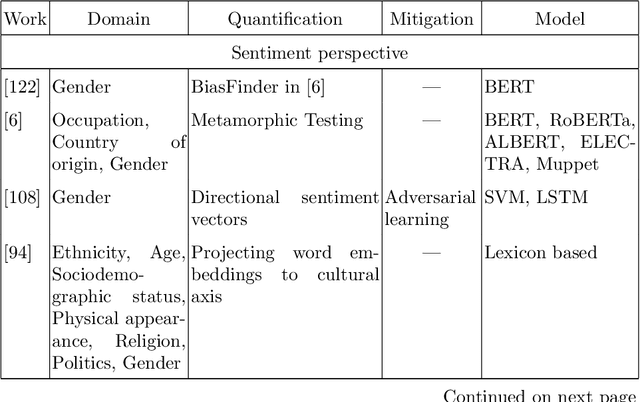
The remarkable progress in Natural Language Processing (NLP) brought about by deep learning, particularly with the recent advent of large pre-trained neural language models, is brought into scrutiny as several studies began to discuss and report potential biases in NLP applications. Bias in NLP is found to originate from latent historical biases encoded by humans into textual data which gets perpetuated or even amplified by NLP algorithm. We present a survey to comprehend bias in large pre-trained language models, analyze the stages at which they occur in these models, and various ways in which these biases could be quantified and mitigated. Considering wide applicability of textual affective computing based downstream tasks in real-world systems such as business, healthcare, education, etc., we give a special emphasis on investigating bias in the context of affect (emotion) i.e., Affective Bias, in large pre-trained language models. We present a summary of various bias evaluation corpora that help to aid future research and discuss challenges in the research on bias in pre-trained language models. We believe that our attempt to draw a comprehensive view of bias in pre-trained language models, and especially the exploration of affective bias will be highly beneficial to researchers interested in this evolving field.