 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fairness in Pre-trained Visual Transformer based Natural and GAN Generated Image Detection Systems and Understanding the Impact of Image Compression in Fairness
Oct 18, 2023



It is not only sufficient to construct computational models that can accurately classify or detect fake images from real images taken from a camera, but it is also important to ensure whether these computational models are fair enough or produce biased outcomes that can eventually harm certain social groups or cause serious security threats. Exploring fairness in forensic algorithms is an initial step towards correcting these biases. Since visual transformers are recently being widely used in most image classification based tasks due to their capability to produce high accuracies, this study tries to explore bias in the transformer based image forensic algorithms that classify natural and GAN generated images. By procuring a bias evaluation corpora, this study analyzes bias in gender, racial, affective, and intersectional domains using a wide set of individual and pairwise bias evaluation measures. As the generalizability of the algorithms against image compression is an important factor to be considered in forensic tasks, this study also analyzes the role of image compression on model bias. Hence to study the impact of image compression on model bias, a two phase evaluation setting is followed, where a set of experiments is carried out in the uncompressed evaluation setting and the other in the compressed evaluation setting.
A Robust Approach Towards Distinguishing Natural and Computer Generated Images using Multi-Colorspace fused and Enriched Vision Transformer
Aug 14, 2023



The works in literature classifying natural and computer generated images are mostly designed as binary tasks either considering natural images versus computer graphics images only or natural images versus GAN generated images only, but not natural images versus both classes of the generated images. Also, even though this forensic classification task of distinguishing natural and computer generated images gets the support of the new convolutional neural networks and transformer based architectures that can give remarkable classification accuracies, they are seen to fail over the images that have undergone some post-processing operations usually performed to deceive the forensic algorithms, such as JPEG compression, gaussian noise, etc. This work proposes a robust approach towards distinguishing natural and computer generated images including both, computer graphics and GAN generated images using a fusion of two vision transformers where each of the transformer networks operates in different color spaces, one in RGB and the other in YCbCr color space. The proposed approach achieves high performance gain when compared to a set of baselines, and also achieves higher robustness and generalizability than the baselines. The features of the proposed model when visualized are seen to obtain higher separability for the classes than the input image features and the baseline features. This work also studies the attention map visualizations of the networks of the fused model and observes that the proposed methodology can capture more image information relevant to the forensic task of classifying natural and generated images.
Distinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021
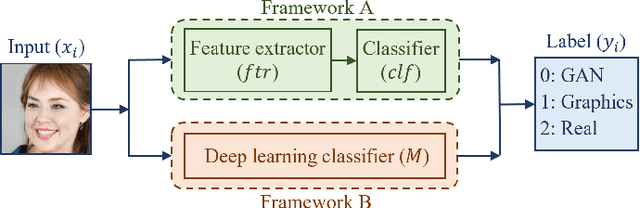
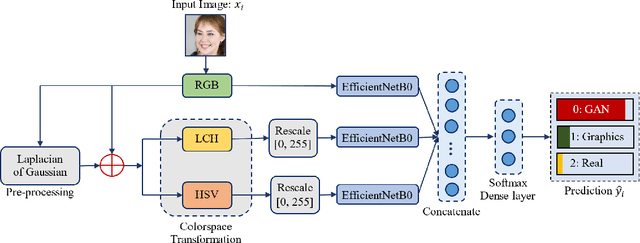
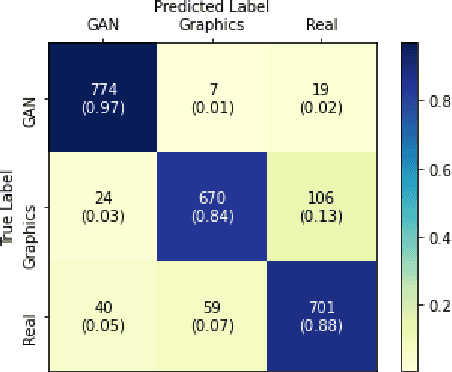
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.