 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinguishing Natural and Computer-Generated Images using Multi-Colorspace fused EfficientNet
Oct 18, 2021
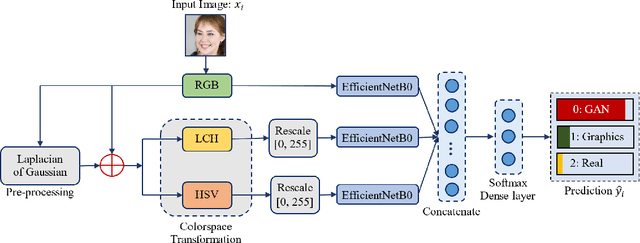
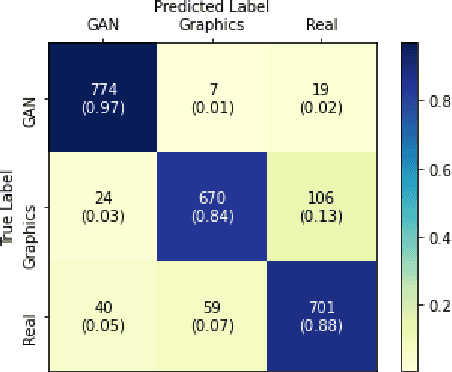
The problem of distinguishing natural images from photo-realistic computer-generated ones either addresses natural images versus computer graphics or natural images versus GAN images, at a time. But in a real-world image forensic scenario, it is highly essential to consider all categories of image generation, since in most cases image generation is unknown. We, for the first time, to our best knowledge, approach the problem of distinguishing natural images from photo-realistic computer-generated images as a three-class classification task classifying natural, computer graphics, and GAN images. For the task, we propose a Multi-Colorspace fused EfficientNet model by parallelly fusing three EfficientNet networks that follow transfer learning methodology where each network operates in different colorspaces, RGB, LCH, and HSV, chosen after analyzing the efficacy of various colorspace transformations in this image forensics problem. Our model outperforms the baselines in terms of accuracy, robustness towards post-processing, and generalizability towards other datasets. We conduct psychophysics experiments to understand how accurately humans can distinguish natural, computer graphics, and GAN images where we could observe that humans find difficulty in classifying these images, particularly the computer-generated images, indicating the necessity of computational algorithms for the task. We also analyze the behavior of our model through visual explanations to understand salient regions that contribute to the model's decision making and compare with manual explanations provided by human participants in the form of region markings, where we could observe similarities in both the explanations indicating the powerful nature of our model to take the decisions meaningfully.
On the Coherence of Fake News Articles
Jun 26, 2019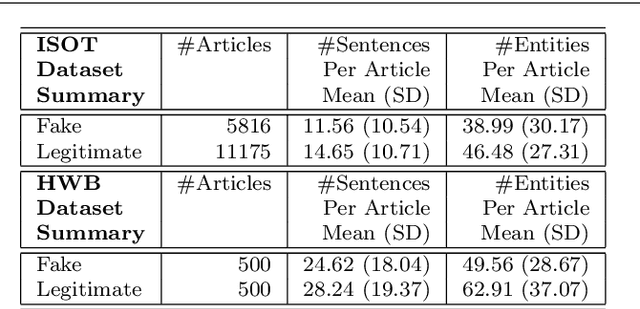
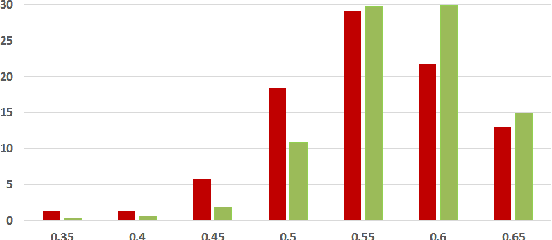
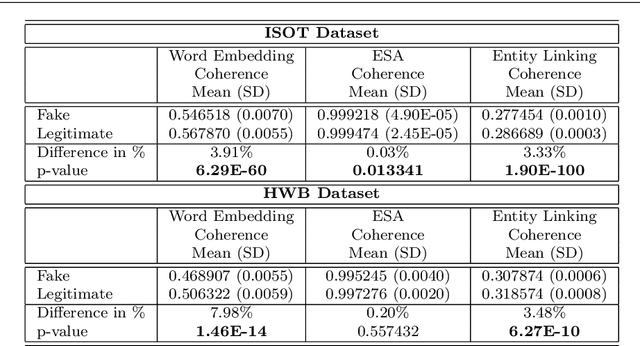
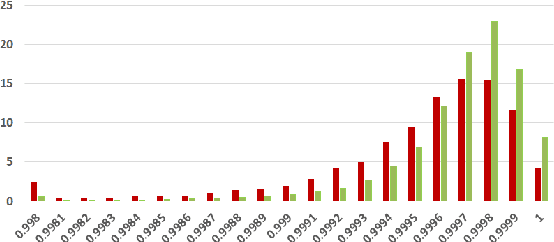
The generation and spread of fake news within new and online media sources is emerging as a phenomenon of high societal significance. Combating them using data-driven analytics has been attracting much recent scholarly interest. In this study, we analyze the textual coherence of fake news articles vis-a-vis legitimate ones. We develop three computational formulations of textual coherence drawing upon the state-of-the-art methods in natural language processing and data science. Two real-world datasets from widely different domains which have fake/legitimate article labellings are then analyzed with respect to textual coherence. We observe apparent differences in textual coherence across fake and legitimate news articles, with fake news articles consistently scoring lower on coherence as compared to legitimate news ones. While the relative coherence shortfall of fake news articles as compared to legitimate ones form the main observation from our study, we analyze several aspects of the differences and outline potential avenues of further inquiry.