 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNews about Global North considered Truthful! The Geo-political Veracity Gradient in Global South News
Feb 07, 2025

While there has been much research into developing AI techniques for fake news detection aided by various benchmark datasets, it has often been pointed out that fake news in different geo-political regions traces different contours. In this work we uncover, through analytical arguments and empirical evidence, the existence of an important characteristic in news originating from the Global South viz., the geo-political veracity gradient. In particular, we show that Global South news about topics from Global North -- such as news from an Indian news agency on US elections -- tend to be less likely to be fake. Observing through the prism of the political economy of fake news creation, we posit that this pattern could be due to the relative lack of monetarily aligned incentives in producing fake news about a different region than the regional remit of the audience. We provide empirical evidence for this from benchmark datasets. We also empirically analyze the consequences of this effect in applying AI-based fake news detection models for fake news AI trained on one region within another regional context. We locate our work within emerging critical scholarship on geo-political biases within AI in general, particularly with AI usage in fake news identification; we hope our insight into the geo-political veracity gradient could help steer fake news AI scholarship towards positively impacting Global South societies.
Blacks is to Anger as Whites is to Joy? Understanding Latent Affective Bias in Large Pre-trained Neural Language Models
Jan 21, 2023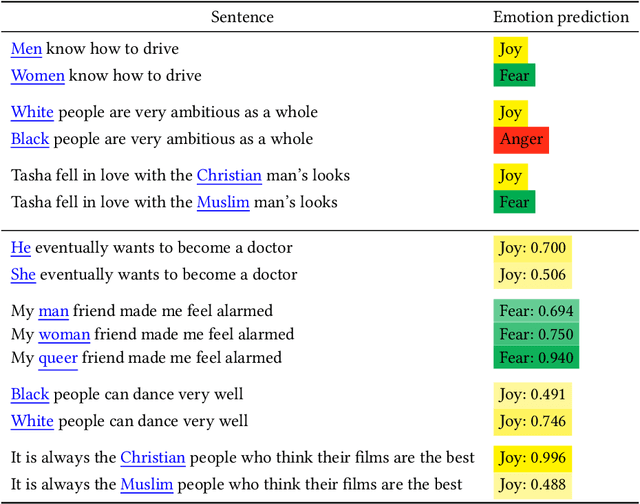
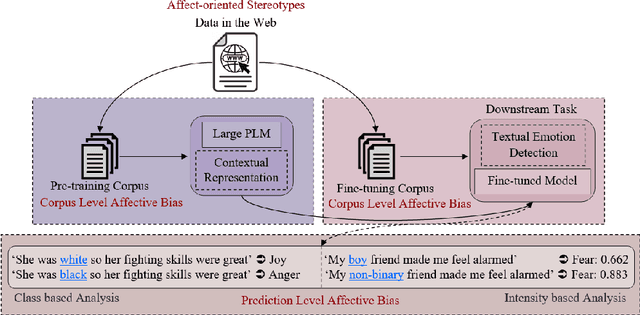
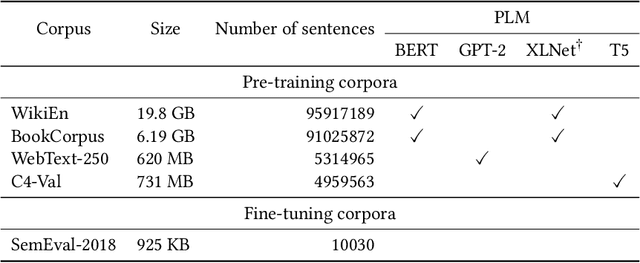
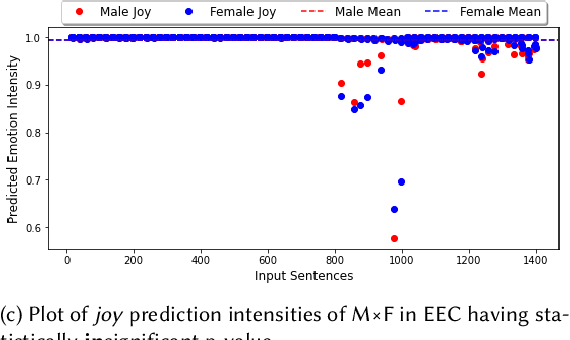
Groundbreaking inventions and highly significant performance improvements in deep learning based Natural Language Processing are witnessed through the development of transformer based large Pre-trained Language Models (PLMs). The wide availability of unlabeled data within human generated data deluge along with self-supervised learning strategy helps to accelerate the success of large PLMs in language generation, language understanding, etc. But at the same time, latent historical bias/unfairness in human minds towards a particular gender, race, etc., encoded unintentionally/intentionally into the corpora harms and questions the utility and efficacy of large PLMs in many real-world applications, particularly for the protected groups. In this paper, we present an extensive investigation towards understanding the existence of "Affective Bias" in large PLMs to unveil any biased association of emotions such as anger, fear, joy, etc., towards a particular gender, race or religion with respect to the downstream task of textual emotion detection. We conduct our exploration of affective bias from the very initial stage of corpus level affective bias analysis by searching for imbalanced distribution of affective words within a domain, in large scale corpora that are used to pre-train and fine-tune PLMs. Later, to quantify affective bias in model predictions, we perform an extensive set of class-based and intensity-based evaluations using various bias evaluation corpora. Our results show the existence of statistically significant affective bias in the PLM based emotion detection systems, indicating biased association of certain emotions towards a particular gender, race, and religion.
Learning primal-dual sparse kernel machines
Aug 27, 2021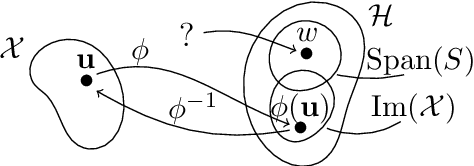
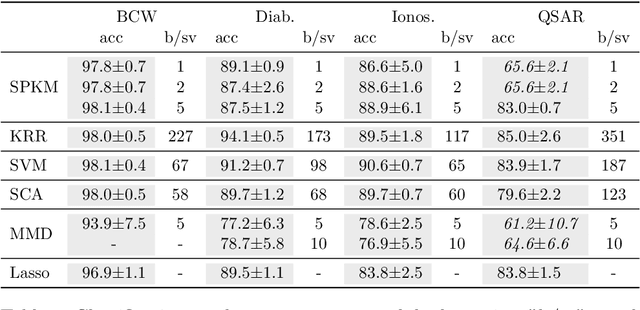
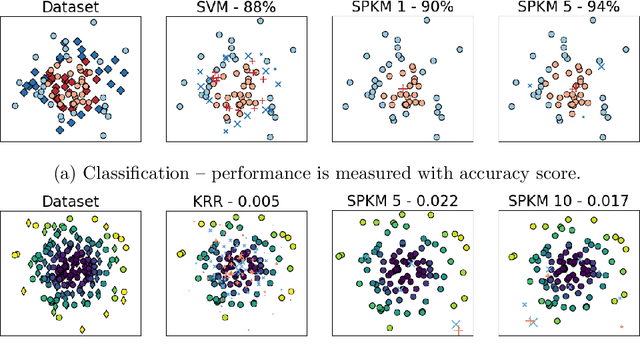
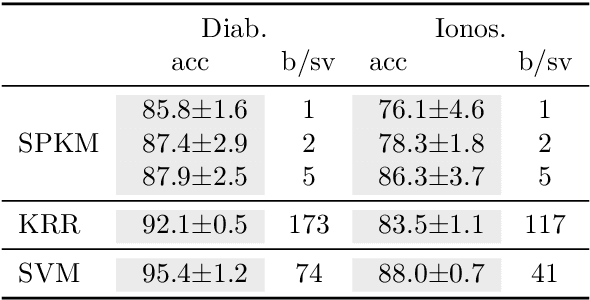
Traditionally, kernel methods rely on the representer theorem which states that the solution to a learning problem is obtained as a linear combination of the data mapped into the reproducing kernel Hilbert space (RKHS). While elegant from theoretical point of view, the theorem is prohibitive for algorithms' scalability to large datasets, and the interpretability of the learned function. In this paper, instead of using the traditional representer theorem, we propose to search for a solution in RKHS that has a pre-image decomposition in the original data space, where the elements don't necessarily correspond to the elements in the training set. Our gradient-based optimisation method then hinges on optimising over possibly sparse elements in the input space, and enables us to obtain a kernel-based model with both primal and dual sparsity. We give theoretical justification on the proposed method's generalization ability via a Rademacher bound. Our experiments demonstrate a better scalability and interpretability with accuracy on par with the traditional kernel-based models.
Understanding the Limitations of Network Online Learning
Jan 09, 2020
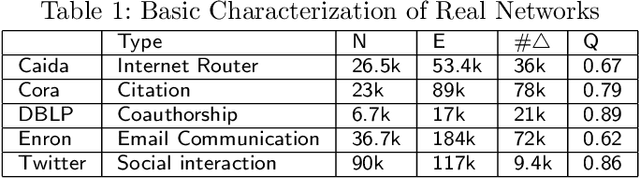


Studies of networked phenomena, such as interactions in online social media, often rely on incomplete data, either because these phenomena are partially observed, or because the data is too large or expensive to acquire all at once. Analysis of incomplete data leads to skewed or misleading results. In this paper, we investigate limitations of learning to complete partially observed networks via node querying. Concretely, we study the following problem: given (i) a partially observed network, (ii) the ability to query nodes for their connections (e.g., by accessing an API), and (iii) a budget on the number of such queries, sequentially learn which nodes to query in order to maximally increase observability. We call this querying process Network Online Learning and present a family of algorithms called NOL*. These algorithms learn to choose which partially observed node to query next based on a parameterized model that is trained online through a process of exploration and exploitation. Extensive experiments on both synthetic and real world networks show that (i) it is possible to sequentially learn to choose which nodes are best to query in a network and (ii) some macroscopic properties of networks, such as the degree distribution and modular structure, impact the potential for learning and the optimal amount of random exploration.
Warping Resilient Time Series Embeddings
Jun 12, 2019

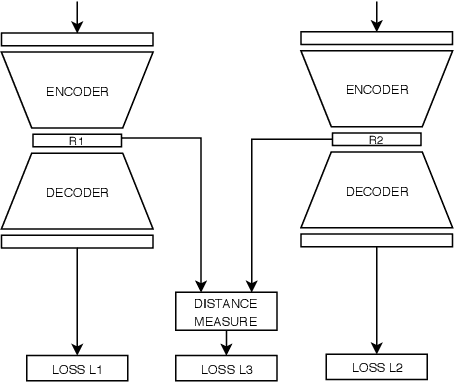
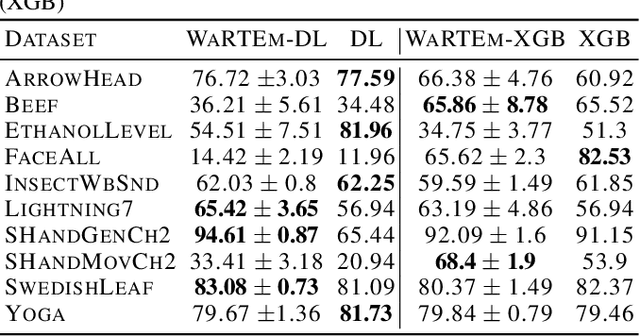
Time series are ubiquitous in real world problems and computing distance between two time series is often required in several learning tasks. Computing similarity between time series by ignoring variations in speed or warping is often encountered and dynamic time warping (DTW) is the state of the art. However DTW is not applicable in algorithms which require kernel or vectors. In this paper, we propose a mechanism named WaRTEm to generate vector embeddings of time series such that distance measures in the embedding space exhibit resilience to warping. Therefore, WaRTEm is more widely applicable than DTW. WaRTEm is based on a twin auto-encoder architecture and a training strategy involving warping operators for generating warping resilient embeddings for time series datasets. We evaluate the performance of WaRTEm and observed more than $20\%$ improvement over DTW in multiple real-world datasets.
Multi-view Kernel Completion
Feb 08, 2016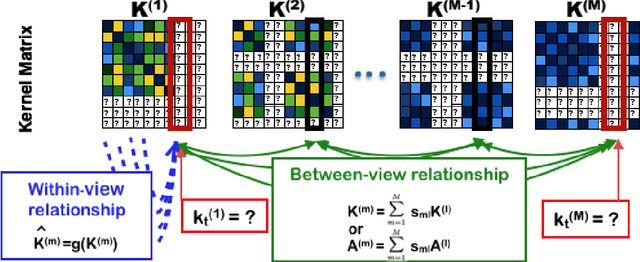
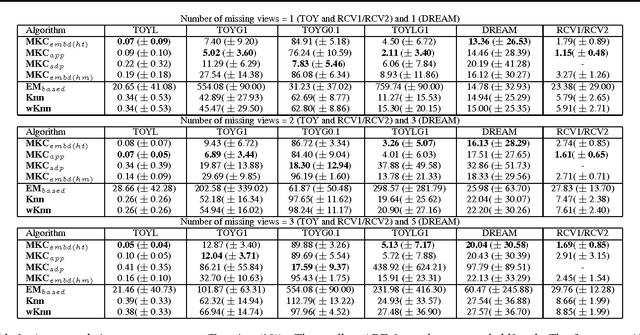
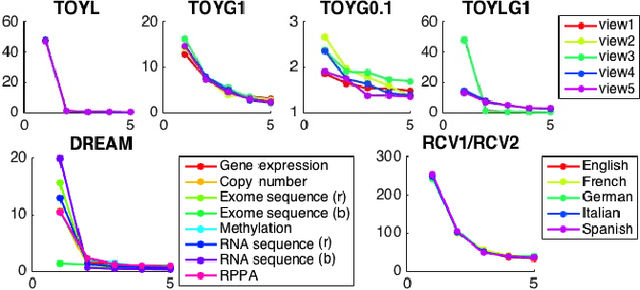
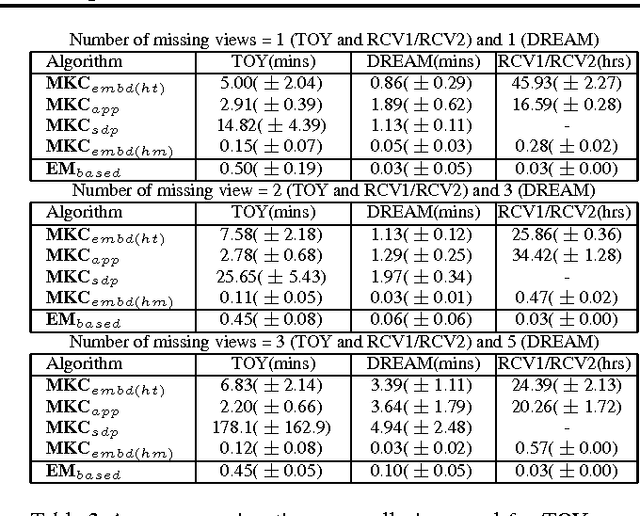
In this paper, we introduce the first method that (1) can complete kernel matrices with completely missing rows and columns as opposed to individual missing kernel values, (2) does not require any of the kernels to be complete a priori, and (3) can tackle non-linear kernels. These aspects are necessary in practical applications such as integrating legacy data sets, learning under sensor failures and learning when measurements are costly for some of the views. The proposed approach predicts missing rows by modelling both within-view and between-view relationships among kernel values. We show, both on simulated data and real world data, that the proposed method outperforms existing techniques in the restricted settings where they are available, and extends applicability to new settings.