 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Limitations of Network Online Learning
Jan 09, 2020
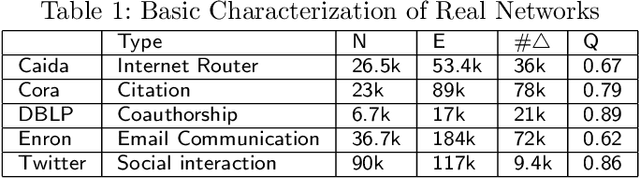


Studies of networked phenomena, such as interactions in online social media, often rely on incomplete data, either because these phenomena are partially observed, or because the data is too large or expensive to acquire all at once. Analysis of incomplete data leads to skewed or misleading results. In this paper, we investigate limitations of learning to complete partially observed networks via node querying. Concretely, we study the following problem: given (i) a partially observed network, (ii) the ability to query nodes for their connections (e.g., by accessing an API), and (iii) a budget on the number of such queries, sequentially learn which nodes to query in order to maximally increase observability. We call this querying process Network Online Learning and present a family of algorithms called NOL*. These algorithms learn to choose which partially observed node to query next based on a parameterized model that is trained online through a process of exploration and exploitation. Extensive experiments on both synthetic and real world networks show that (i) it is possible to sequentially learn to choose which nodes are best to query in a network and (ii) some macroscopic properties of networks, such as the degree distribution and modular structure, impact the potential for learning and the optimal amount of random exploration.