 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentativity Fairness in Clustering
Paper and Code
Oct 11, 2020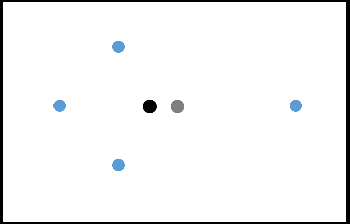
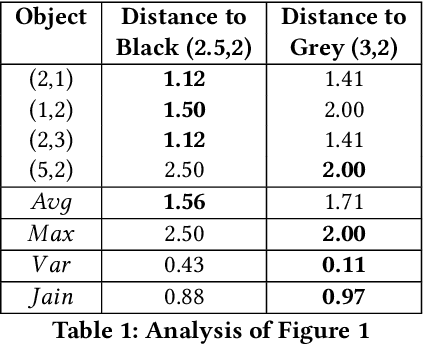
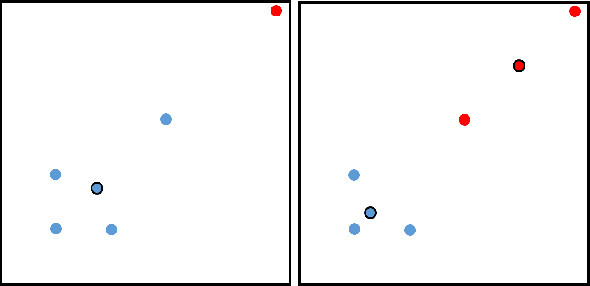

Incorporating fairness constructs into machine learning algorithms is a topic of much societal importance and recent interest. Clustering, a fundamental task in unsupervised learning that manifests across a number of web data scenarios, has also been subject of attention within fair ML research. In this paper, we develop a novel notion of fairness in clustering, called representativity fairness. Representativity fairness is motivated by the need to alleviate disparity across objects' proximity to their assigned cluster representatives, to aid fairer decision making. We illustrate the importance of representativity fairness in real-world decision making scenarios involving clustering and provide ways of quantifying objects' representativity and fairness over it. We develop a new clustering formulation, RFKM, that targets to optimize for representativity fairness along with clustering quality. Inspired by the $K$-Means framework, RFKM incorporates novel loss terms to formulate an objective function. The RFKM objective and optimization approach guides it towards clustering configurations that yield higher representativity fairness. Through an empirical evaluation over a variety of public datasets, we establish the effectiveness of our method. We illustrate that we are able to significantly improve representativity fairness at only marginal impact to clustering quality.