 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Text Representations for Online Misinformation
Dec 13, 2024Mis- and disinformation, commonly collectively called fake news, continue to menace society. Perhaps, the impact of this age-old problem is presently most plain in politics and healthcare. However, fake news is affecting an increasing number of domains. It takes many different forms and continues to shapeshift as technology advances. Though it arguably most widely spreads in textual form, e.g., through social media posts and blog articles. Thus, it is imperative to thwart the spread of textual misinformation, which necessitates its initial detection. This thesis contributes to the creation of representations that are useful for detecting misinformation. Firstly, it develops a novel method for extracting textual features from news articles for misinformation detection. These features harness the disparity between the thematic coherence of authentic and false news stories. In other words, the composition of themes discussed in both groups significantly differs as the story progresses. Secondly, it demonstrates the effectiveness of topic features for fake news detection, using classification and clustering. Clustering is particularly useful because it alleviates the need for a labelled dataset, which can be labour-intensive and time-consuming to amass. More generally, it contributes towards a better understanding of misinformation and ways of detecting it using Machine Learning and Natural Language Processing.
Classifying Cyber-Risky Clinical Notes by Employing Natural Language Processing
Mar 24, 2022


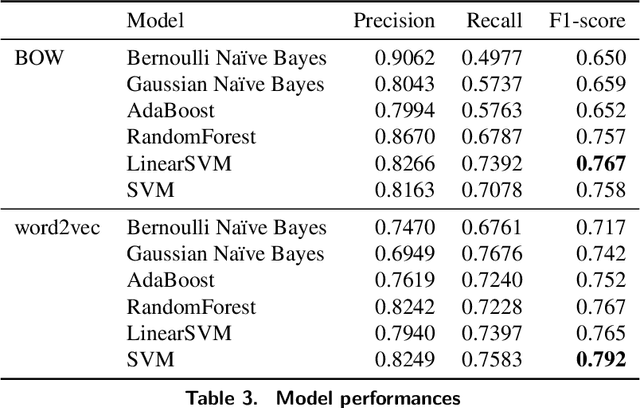
Clinical notes, which can be embedded into electronic medical records, document patient care delivery and summarize interactions between healthcare providers and patients. These clinical notes directly inform patient care and can also indirectly inform research and quality/safety metrics, among other indirect metrics. Recently, some states within the United States of America require patients to have open access to their clinical notes to improve the exchange of patient information for patient care. Thus, developing methods to assess the cyber risks of clinical notes before sharing and exchanging data is critical. While existing natural language processing techniques are geared to de-identify clinical notes, to the best of our knowledge, few have focused on classifying sensitive-information risk, which is a fundamental step toward developing effective, widespread protection of patient health information. To bridge this gap, this research investigates methods for identifying security/privacy risks within clinical notes. The classification either can be used upstream to identify areas within notes that likely contain sensitive information or downstream to improve the identification of clinical notes that have not been entirely de-identified. We develop several models using unigram and word2vec features with different classifiers to categorize sentence risk. Experiments on i2b2 de-identification dataset show that the SVM classifier using word2vec features obtained a maximum F1-score of 0.792. Future research involves articulation and differentiation of risk in terms of different global regulatory requirements.
Exploring Thematic Coherence in Fake News
Dec 17, 2020
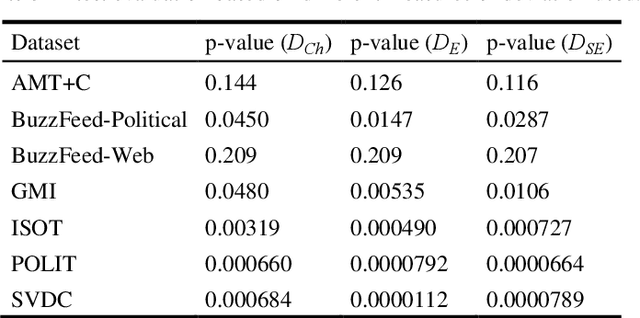
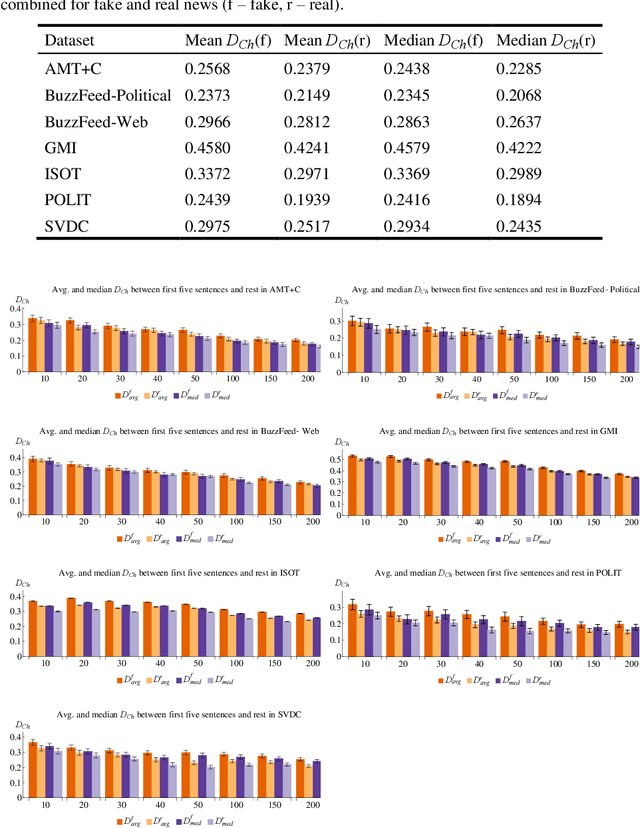
The spread of fake news remains a serious global issue; understanding and curtailing it is paramount. One way of differentiating between deceptive and truthful stories is by analyzing their coherence. This study explores the use of topic models to analyze the coherence of cross-domain news shared online. Experimental results on seven cross-domain datasets demonstrate that fake news shows a greater thematic deviation between its opening sentences and its remainder.