 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI and Core Electoral Processes: Mapping the Horizons
Feb 07, 2023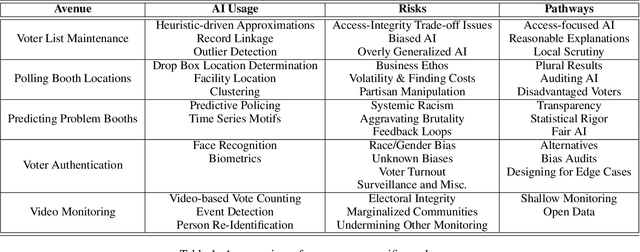



Significant enthusiasm around AI uptake has been witnessed across societies globally. The electoral process -- the time, place and manner of elections within democratic nations -- has been among those very rare sectors in which AI has not penetrated much. Electoral management bodies in many countries have recently started exploring and deliberating over the use of AI in the electoral process. In this paper, we consider five representative avenues within the core electoral process which have potential for AI usage, and map the challenges involved in using AI within them. These five avenues are: voter list maintenance, determining polling booth locations, polling booth protection processes, voter authentication and video monitoring of elections. Within each of these avenues, we lay down the context, illustrate current or potential usage of AI, and discuss extant or potential ramifications of AI usage, and potential directions for mitigating risks while considering AI usage. We believe that the scant current usage of AI within electoral processes provides a very rare opportunity, that of being able to deliberate on the risks and mitigation possibilities, prior to real and widespread AI deployment. This paper is an attempt to map the horizons of risks and opportunities in using AI within the electoral processes and to help shape the debate around the topic.
Cluster-level Group Representativity Fairness in $k$-means Clustering
Dec 29, 2022There has been much interest recently in developing fair clustering algorithms that seek to do justice to the representation of groups defined along sensitive attributes such as race and gender. We observe that clustering algorithms could generate clusters such that different groups are disadvantaged within different clusters. We develop a clustering algorithm, building upon the centroid clustering paradigm pioneered by classical algorithms such as $k$-means, where we focus on mitigating the unfairness experienced by the most-disadvantaged group within each cluster. Our method uses an iterative optimisation paradigm whereby an initial cluster assignment is modified by reassigning objects to clusters such that the worst-off sensitive group within each cluster is benefitted. We demonstrate the effectiveness of our method through extensive empirical evaluations over a novel evaluation metric on real-world datasets. Specifically, we show that our method is effective in enhancing cluster-level group representativity fairness significantly at low impact on cluster coherence.
Exploring Rawlsian Fairness for K-Means Clustering
May 04, 2022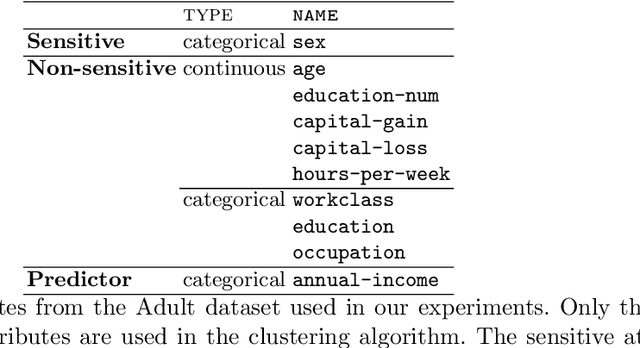
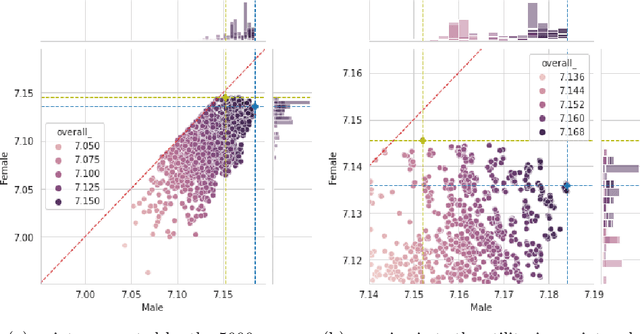
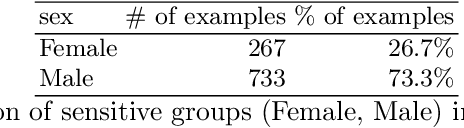
We conduct an exploratory study that looks at incorporating John Rawls' ideas on fairness into existing unsupervised machine learning algorithms. Our focus is on the task of clustering, specifically the k-means clustering algorithm. To the best of our knowledge, this is the first work that uses Rawlsian ideas in clustering. Towards this, we attempt to develop a postprocessing technique i.e., one that operates on the cluster assignment generated by the standard k-means clustering algorithm. Our technique perturbs this assignment over a number of iterations to make it fairer according to Rawls' difference principle while minimally affecting the overall utility. As the first step, we consider two simple perturbation operators -- $\mathbf{R_1}$ and $\mathbf{R_2}$ -- that reassign examples in a given cluster assignment to new clusters; $\mathbf{R_1}$ assigning a single example to a new cluster, and $\mathbf{R_2}$ a pair of examples to new clusters. Our experiments on a sample of the Adult dataset demonstrate that both operators make meaningful perturbations in the cluster assignment towards incorporating Rawls' difference principle, with $\mathbf{R_2}$ being more efficient than $\mathbf{R_1}$ in terms of the number of iterations. However, we observe that there is still a need to design operators that make significantly better perturbations. Nevertheless, both operators provide good baselines for designing and comparing any future operator, and we hope our findings would aid future work in this direction.