 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlue Data Intelligence Layer: Streaming Data and Agents for Multi-source Multi-modal Data-Centric Applications
Apr 16, 2026NL2SQL systems aim to address the growing need for natural language interaction with data. However, real-world information rarely maps to a single SQL query because (1) users express queries iteratively (2) questions often span multiple data sources beyond the closed-world assumption of a single database, and (3) queries frequently rely on commonsense or external knowledge. Consequently, satisfying realistic data needs require integrating heterogeneous sources, modalities, and contextual data. In this paper, we present Blue's Data Intelligence Layer (DIL) designed to support multi-source, multi-modal, and data-centric applications. Blue is a compound AI system that orchestrates agents and data for enterprise settings. DIL serves as the data intelligence layer for agentic data processing, to bridge the semantic gap between user intent and available information by unifying structured enterprise data, world knowledge accessible through LLMs, and personal context obtained through interaction. At the core of DIL is a data registry that stores metadata for diverse data sources and modalities to enable both native and natural language queries. DIL treats LLMs, the Web, and the User as source 'databases', each with their own query interface, elevating them to first-class data sources. DIL relies on data planners to transform user queries into executable query plans. These plans are declarative abstractions that unify relational operators with other operators spanning multiple modalities. DIL planners support decomposition of complex requests into subqueries, retrieval from diverse sources, and finally reasoning and integration to produce final results. We demonstrate DIL through two interactive scenarios in which user queries dynamically trigger multi-source retrieval, cross-modal reasoning, and result synthesis, illustrating how compound AI systems can move beyond single database NL2SQL.
FactLens: Benchmarking Fine-Grained Fact Verification
Nov 08, 2024



Large Language Models (LLMs) have shown impressive capability in language generation and understanding, but their tendency to hallucinate and produce factually incorrect information remains a key limitation. To verify LLM-generated contents and claims from other sources, traditional verification approaches often rely on holistic models that assign a single factuality label to complex claims, potentially obscuring nuanced errors. In this paper, we advocate for a shift toward fine-grained verification, where complex claims are broken down into smaller sub-claims for individual verification, allowing for more precise identification of inaccuracies, improved transparency, and reduced ambiguity in evidence retrieval. However, generating sub-claims poses challenges, such as maintaining context and ensuring semantic equivalence with respect to the original claim. We introduce FactLens, a benchmark for evaluating fine-grained fact verification, with metrics and automated evaluators of sub-claim quality. The benchmark data is manually curated to ensure high-quality ground truth. Our results show alignment between automated FactLens evaluators and human judgments, and we discuss the impact of sub-claim characteristics on the overall verification performance.
A Blueprint Architecture of Compound AI Systems for Enterprise
Jun 02, 2024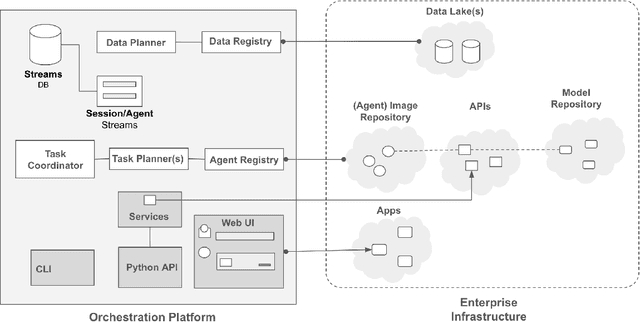
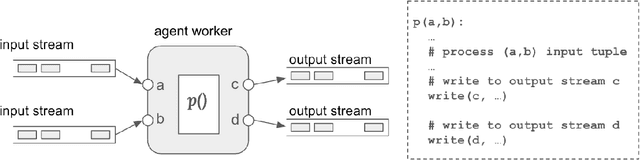
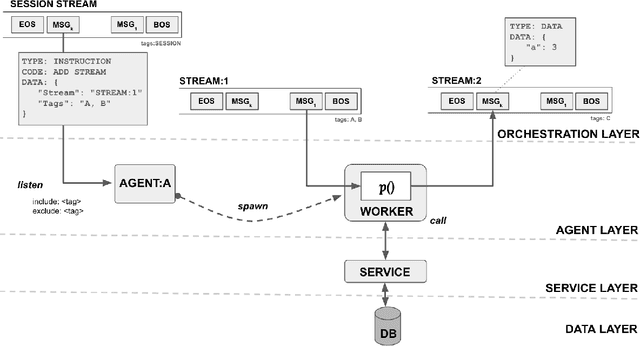
Large Language Models (LLMs) have showcased remarkable capabilities surpassing conventional NLP challenges, creating opportunities for use in production use cases. Towards this goal, there is a notable shift to building compound AI systems, wherein LLMs are integrated into an expansive software infrastructure with many components like models, retrievers, databases and tools. In this paper, we introduce a blueprint architecture for compound AI systems to operate in enterprise settings cost-effectively and feasibly. Our proposed architecture aims for seamless integration with existing compute and data infrastructure, with ``stream'' serving as the key orchestration concept to coordinate data and instructions among agents and other components. Task and data planners, respectively, break down, map, and optimize tasks and data to available agents and data sources defined in respective registries, given production constraints such as accuracy and latency.
MEGAnno+: A Human-LLM Collaborative Annotation System
Feb 28, 2024
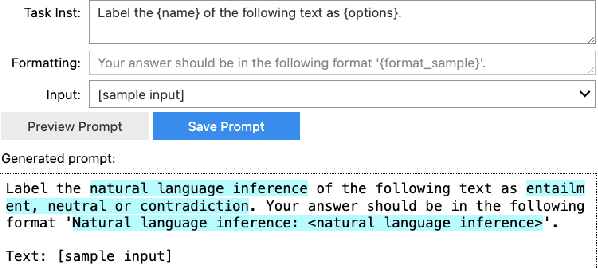

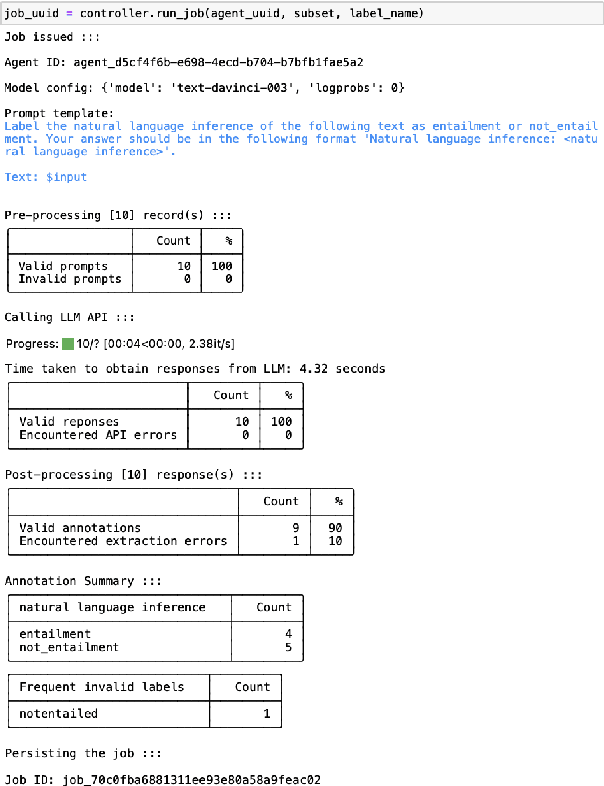
Large language models (LLMs) can label data faster and cheaper than humans for various NLP tasks. Despite their prowess, LLMs may fall short in understanding of complex, sociocultural, or domain-specific context, potentially leading to incorrect annotations. Therefore, we advocate a collaborative approach where humans and LLMs work together to produce reliable and high-quality labels. We present MEGAnno+, a human-LLM collaborative annotation system that offers effective LLM agent and annotation management, convenient and robust LLM annotation, and exploratory verification of LLM labels by humans.
Characterizing Large Language Models as Rationalizers of Knowledge-intensive Tasks
Nov 09, 2023



Large language models (LLMs) are proficient at generating fluent text with minimal task-specific supervision. Yet, their ability to provide well-grounded rationalizations for knowledge-intensive tasks remains under-explored. Such tasks, like commonsense multiple-choice questions, require rationales based on world knowledge to support predictions and refute alternate options. We consider the task of generating knowledge-guided rationalization in natural language by using expert-written examples in a few-shot manner. Surprisingly, crowd-workers preferred knowledge-grounded rationales over crowdsourced rationalizations, citing their factuality, sufficiency, and comprehensive refutations. Although LLMs-generated rationales were preferable, further improvements in conciseness and novelty are required. In another study, we show how rationalization of incorrect model predictions erodes humans' trust in LLM-generated rationales. Motivated by these observations, we create a two-stage pipeline to review task predictions and eliminate potential incorrect decisions before rationalization, enabling trustworthy rationale generation.