 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteASR: Efficient Automatic Speech Recognition with Low-Rank Approximation
Feb 27, 2025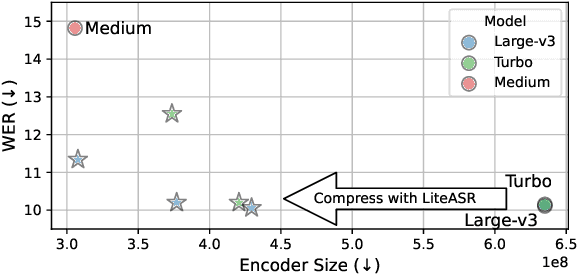
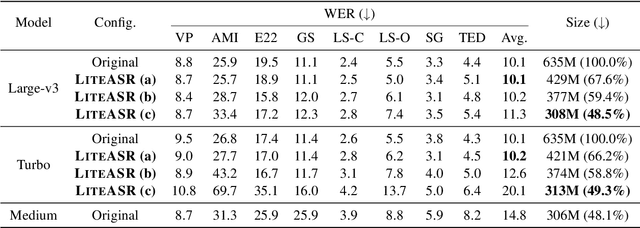
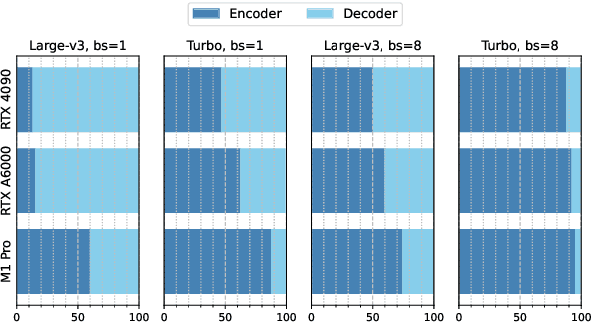
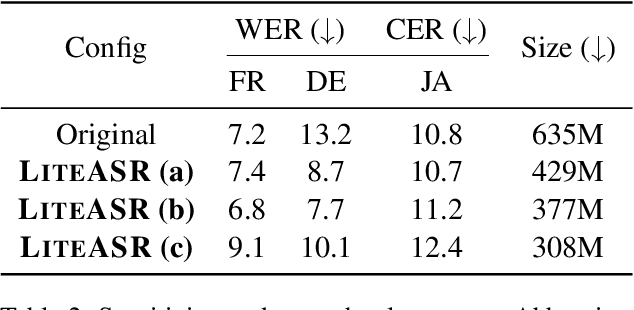
Modern automatic speech recognition (ASR) models, such as OpenAI's Whisper, rely on deep encoder-decoder architectures, and their encoders are a critical bottleneck for efficient deployment due to high computational intensity. We introduce LiteASR, a low-rank compression scheme for ASR encoders that significantly reduces inference costs while maintaining transcription accuracy. Our approach leverages the strong low-rank properties observed in intermediate activations: by applying principal component analysis (PCA) with a small calibration dataset, we approximate linear transformations with a chain of low-rank matrix multiplications, and further optimize self-attention to work in the reduced dimension. Evaluation results show that our method can compress Whisper large-v3's encoder size by over 50%, matching Whisper medium's size with better transcription accuracy, thereby establishing a new Pareto-optimal frontier of efficiency and performance. The code of LiteASR is available at https://github.com/efeslab/LiteASR.
ACID: Abstractive, Content-Based IDs for Document Retrieval with Language Models
Nov 14, 2023



Generative retrieval (Wang et al., 2022; Tay et al., 2022) is a new approach for end-to-end document retrieval that directly generates document identifiers given an input query. Techniques for designing effective, high-quality document IDs remain largely unexplored. We introduce ACID, in which each document's ID is composed of abstractive keyphrases generated by a large language model, rather than an integer ID sequence as done in past work. We compare our method with the current state-of-the-art technique for ID generation, which produces IDs through hierarchical clustering of document embeddings. We also examine simpler methods to generate natural-language document IDs, including the naive approach of using the first k words of each document as its ID or words with high BM25 scores in that document. We show that using ACID improves top-10 and top-20 accuracy by 15.6% and 14.4% (relative) respectively versus the state-of-the-art baseline on the MSMARCO 100k retrieval task, and 4.4% and 4.0% respectively on the Natural Questions 100k retrieval task. Our results demonstrate the effectiveness of human-readable, natural-language IDs in generative retrieval with LMs. The code for reproducing our results and the keyword-augmented datasets will be released on formal publication.
Evaluating Spatial Understanding of Large Language Models
Oct 23, 2023Large language models (LLMs) show remarkable capabilities across a variety of tasks. Despite the models only seeing text in training, several recent studies suggest that LLM representations implicitly capture aspects of the underlying grounded concepts. Here, we explore LLM representations of a particularly salient kind of grounded knowledge -- spatial relationships. We design natural-language navigation tasks and evaluate the ability of LLMs, in particular GPT-3.5-turbo, GPT-4, and Llama2 series models, to represent and reason about spatial structures, and compare these abilities to human performance on the same tasks. These tasks reveal substantial variability in LLM performance across different spatial structures, including square, hexagonal, and triangular grids, rings, and trees. We also discover that, similar to humans, LLMs utilize object names as landmarks for maintaining spatial maps. Finally, in extensive error analysis, we find that LLMs' mistakes reflect both spatial and non-spatial factors. These findings suggest that LLMs appear to capture certain aspects of spatial structure implicitly, but room for improvement remains.
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence
Jun 12, 2023Better understanding of Large Language Models' (LLMs) legal analysis abilities can contribute to improving the efficiency of legal services, governing artificial intelligence, and leveraging LLMs to identify inconsistencies in law. This paper explores LLM capabilities in applying tax law. We choose this area of law because it has a structure that allows us to set up automated validation pipelines across thousands of examples, requires logical reasoning and maths skills, and enables us to test LLM capabilities in a manner relevant to real-world economic lives of citizens and companies. Our experiments demonstrate emerging legal understanding capabilities, with improved performance in each subsequent OpenAI model release. We experiment with retrieving and utilising the relevant legal authority to assess the impact of providing additional legal context to LLMs. Few-shot prompting, presenting examples of question-answer pairs, is also found to significantly enhance the performance of the most advanced model, GPT-4. The findings indicate that LLMs, particularly when combined with prompting enhancements and the correct legal texts, can perform at high levels of accuracy but not yet at expert tax lawyer levels. As LLMs continue to advance, their ability to reason about law autonomously could have significant implications for the legal profession and AI governance.
Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models
May 23, 2023Language models have graduated from being research prototypes to commercialized products offered as web APIs, and recent works have highlighted the multilingual capabilities of these products. The API vendors charge their users based on usage, more specifically on the number of ``tokens'' processed or generated by the underlying language models. What constitutes a token, however, is training data and model dependent with a large variance in the number of tokens required to convey the same information in different languages. In this work, we analyze the effect of this non-uniformity on the fairness of an API's pricing policy across languages. We conduct a systematic analysis of the cost and utility of OpenAI's language model API on multilingual benchmarks in 22 typologically diverse languages. We show evidence that speakers of a large number of the supported languages are overcharged while obtaining poorer results. These speakers tend to also come from regions where the APIs are less affordable to begin with. Through these analyses, we aim to increase transparency around language model APIs' pricing policies and encourage the vendors to make them more equitable.
Evaluating GPT-4 and ChatGPT on Japanese Medical Licensing Examinations
Apr 05, 2023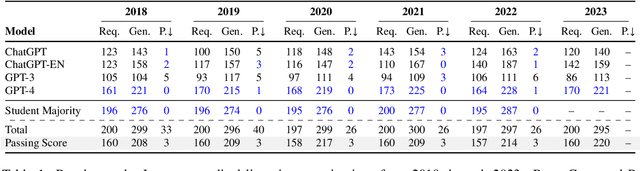
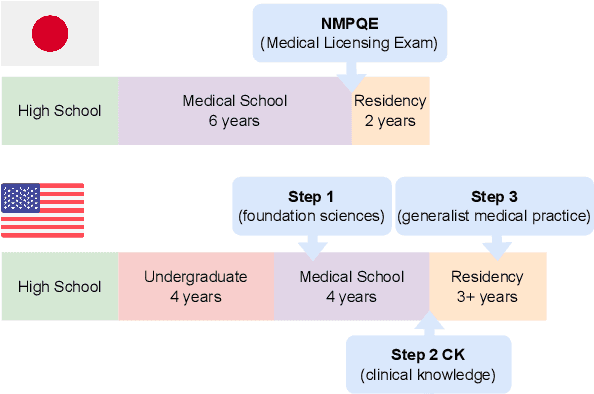
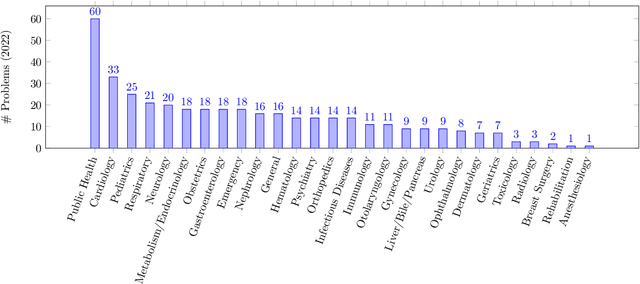
As large language models (LLMs) gain popularity among speakers of diverse languages, we believe that it is crucial to benchmark them to better understand model behaviors, failures, and limitations in languages beyond English. In this work, we evaluate LLM APIs (ChatGPT, GPT-3, and GPT-4) on the Japanese national medical licensing examinations from the past five years, including the current year. Our team comprises native Japanese-speaking NLP researchers and a practicing cardiologist based in Japan. Our experiments show that GPT-4 outperforms ChatGPT and GPT-3 and passes all six years of the exams, highlighting LLMs' potential in a language that is typologically distant from English. However, our evaluation also exposes critical limitations of the current LLM APIs. First, LLMs sometimes select prohibited choices that should be strictly avoided in medical practice in Japan, such as suggesting euthanasia. Further, our analysis shows that the API costs are generally higher and the maximum context size is smaller for Japanese because of the way non-Latin scripts are currently tokenized in the pipeline. We release our benchmark as Igaku QA as well as all model outputs and exam metadata. We hope that our results and benchmark will spur progress on more diverse applications of LLMs. Our benchmark is available at https://github.com/jungokasai/IgakuQA.
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering
Mar 28, 2023Despite thousands of researchers, engineers, and artists actively working on improving text-to-image generation models, systems often fail to produce images that accurately align with the text inputs. We introduce TIFA (Text-to-Image Faithfulness evaluation with question Answering), an automatic evaluation metric that measures the faithfulness of a generated image to its text input via visual question answering (VQA). Specifically, given a text input, we automatically generate several question-answer pairs using a language model. We calculate image faithfulness by checking whether existing VQA models can answer these questions using the generated image. TIFA is a reference-free metric that allows for fine-grained and interpretable evaluations of generated images. TIFA also has better correlations with human judgments than existing metrics. Based on this approach, we introduce TIFA v1.0, a benchmark consisting of 4K diverse text inputs and 25K questions across 12 categories (object, counting, etc.). We present a comprehensive evaluation of existing text-to-image models using TIFA v1.0 and highlight the limitations and challenges of current models. For instance, we find that current text-to-image models, despite doing well on color and material, still struggle in counting, spatial relations, and composing multiple objects. We hope our benchmark will help carefully measure the research progress in text-to-image synthesis and provide valuable insights for further research.
Batch Prompting: Efficient Inference with Large Language Model APIs
Jan 19, 2023Performing inference on hundreds of thousands of samples with large language models (LLMs) can be computationally and financially costly. We propose batch prompting, a simple alternative prompting approach that enables the LLM to run inference in batches, instead of one sample at a time. Our method reduces both token and time costs while retaining downstream performance. We theoretically demonstrate that under a few-shot in-context learning setting, the inference costs decrease almost inverse linearly with the number of samples in each batch. We extensively validate the effectiveness of batch prompting on ten datasets across commonsense QA, arithmetic reasoning, and NLI/NLU: batch prompting significantly~(up to $5\times$ with six samples in batch) reduces the LLM (Codex) inference token and time costs while achieving better or comparable performance. Our analysis shows that the number of samples in each batch and the complexity of tasks affect its performance. Further, batch prompting can be applied across different LLMs and reasoning methods.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Jan 11, 2023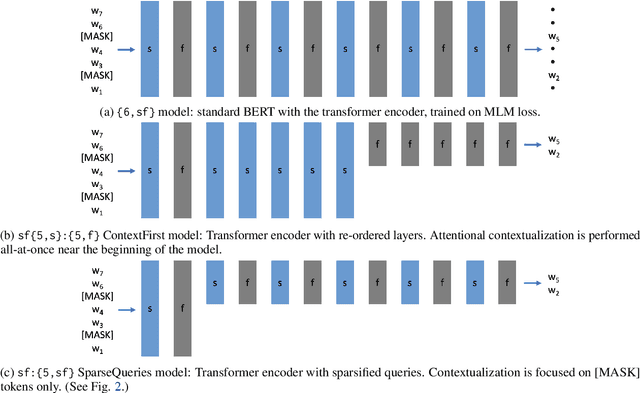

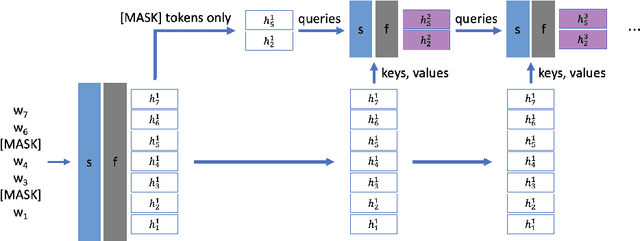
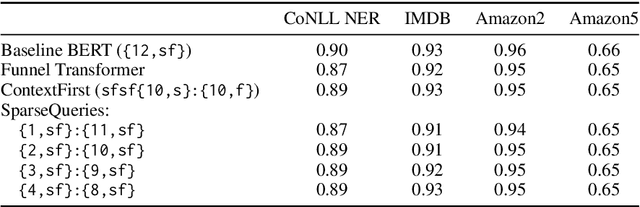
Large-scale language model pretraining is a very successful form of self-supervised learning in natural language processing, but it is increasingly expensive to perform as the models and pretraining corpora have become larger over time. We propose NarrowBERT, a modified transformer encoder that increases the throughput for masked language model pretraining by more than $2\times$. NarrowBERT sparsifies the transformer model such that the self-attention queries and feedforward layers only operate on the masked tokens of each sentence during pretraining, rather than all of the tokens as with the usual transformer encoder. We also show that NarrowBERT increases the throughput at inference time by as much as $3.5\times$ with minimal (or no) performance degradation on sentence encoding tasks like MNLI. Finally, we examine the performance of NarrowBERT on the IMDB and Amazon reviews classification and CoNLL NER tasks and show that it is also comparable to standard BERT performance.
One Embedder, Any Task: Instruction-Finetuned Text Embeddings
Dec 20, 2022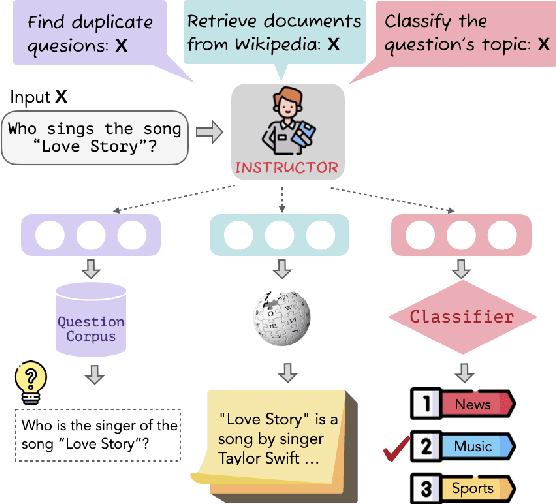
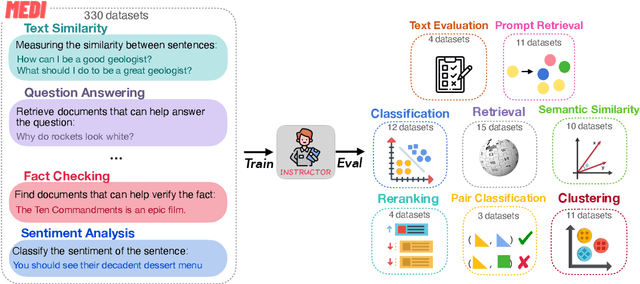
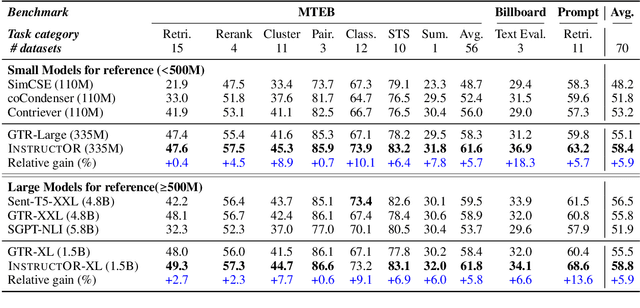
We introduce INSTRUCTOR, a new method for computing text embeddings given task instructions: every text input is embedded together with instructions explaining the use case (e.g., task and domain descriptions). Unlike encoders from prior work that are more specialized, INSTRUCTOR is a single embedder that can generate text embeddings tailored to different downstream tasks and domains, without any further training. We first annotate instructions for 330 diverse tasks and train INSTRUCTOR on this multitask mixture with a contrastive loss. We evaluate INSTRUCTOR on 70 embedding evaluation tasks (66 of which are unseen during training), ranging from classification and information retrieval to semantic textual similarity and text generation evaluation. INSTRUCTOR, while having an order of magnitude fewer parameters than the previous best model, achieves state-of-the-art performance, with an average improvement of 3.4% compared to the previous best results on the 70 diverse datasets. Our analysis suggests that INSTRUCTOR is robust to changes in instructions, and that instruction finetuning mitigates the challenge of training a single model on diverse datasets. Our model, code, and data are available at https://instructor-embedding.github.io.