 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterrogating LLM design under a fair learning doctrine
Feb 22, 2025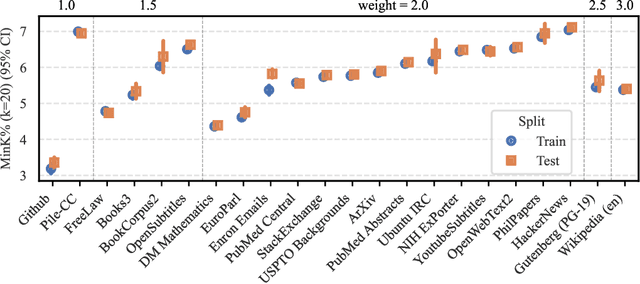
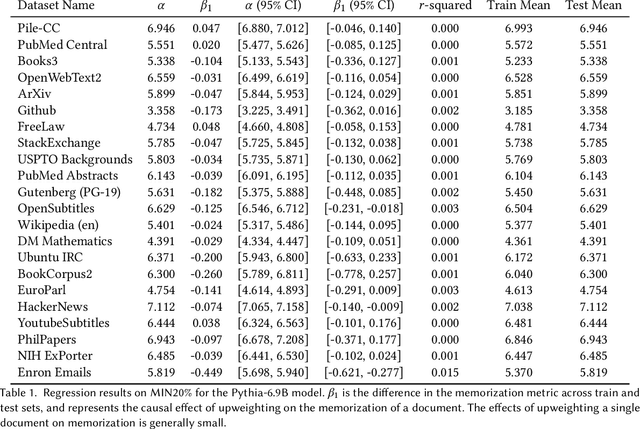
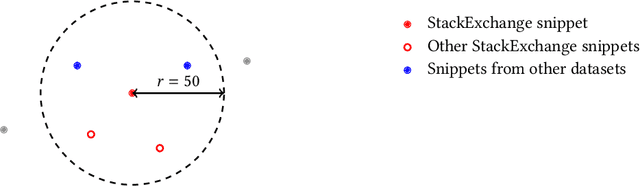
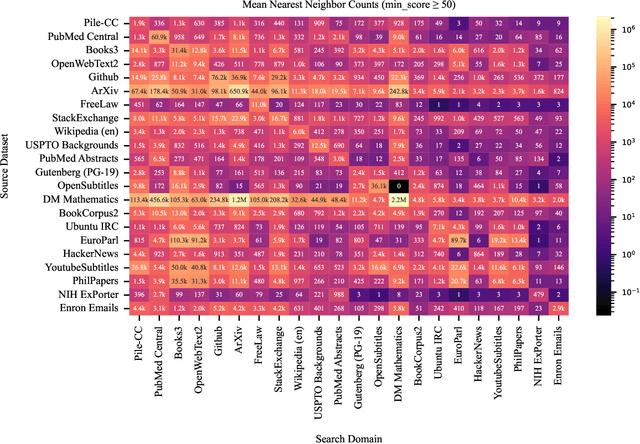
The current discourse on large language models (LLMs) and copyright largely takes a "behavioral" perspective, focusing on model outputs and evaluating whether they are substantially similar to training data. However, substantial similarity is difficult to define algorithmically and a narrow focus on model outputs is insufficient to address all copyright risks. In this interdisciplinary work, we take a complementary "structural" perspective and shift our focus to how LLMs are trained. We operationalize a notion of "fair learning" by measuring whether any training decision substantially affected the model's memorization. As a case study, we deconstruct Pythia, an open-source LLM, and demonstrate the use of causal and correlational analyses to make factual determinations about Pythia's training decisions. By proposing a legal standard for fair learning and connecting memorization analyses to this standard, we identify how judges may advance the goals of copyright law through adjudication. Finally, we discuss how a fair learning standard might evolve to enhance its clarity by becoming more rule-like and incorporating external technical guidelines.
LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models
Aug 20, 2023
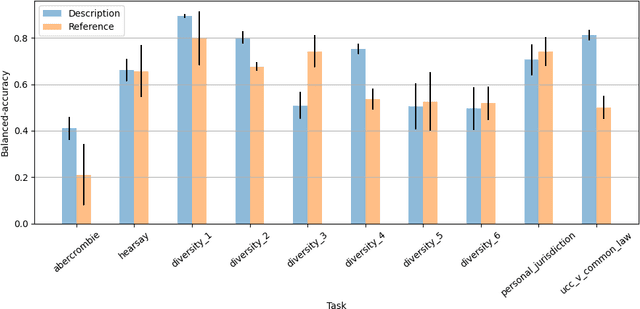
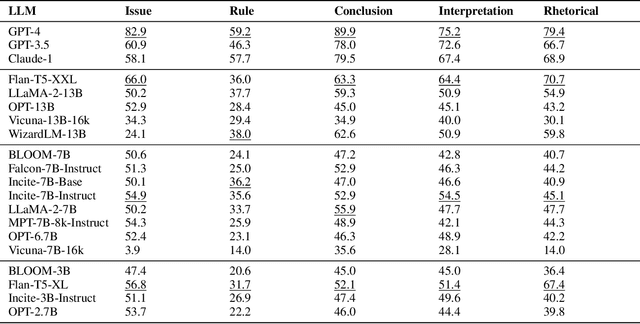
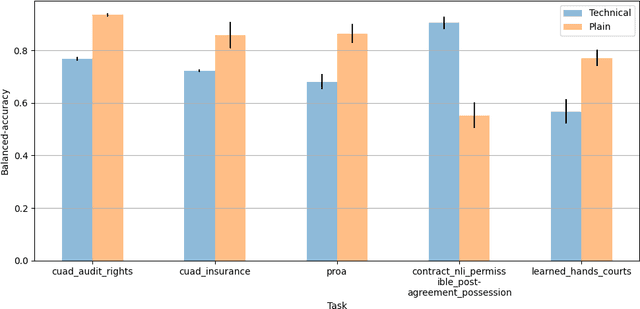
The advent of large language models (LLMs) and their adoption by the legal community has given rise to the question: what types of legal reasoning can LLMs perform? To enable greater study of this question, we present LegalBench: a collaboratively constructed legal reasoning benchmark consisting of 162 tasks covering six different types of legal reasoning. LegalBench was built through an interdisciplinary process, in which we collected tasks designed and hand-crafted by legal professionals. Because these subject matter experts took a leading role in construction, tasks either measure legal reasoning capabilities that are practically useful, or measure reasoning skills that lawyers find interesting. To enable cross-disciplinary conversations about LLMs in the law, we additionally show how popular legal frameworks for describing legal reasoning -- which distinguish between its many forms -- correspond to LegalBench tasks, thus giving lawyers and LLM developers a common vocabulary. This paper describes LegalBench, presents an empirical evaluation of 20 open-source and commercial LLMs, and illustrates the types of research explorations LegalBench enables.
Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence
Jun 12, 2023Better understanding of Large Language Models' (LLMs) legal analysis abilities can contribute to improving the efficiency of legal services, governing artificial intelligence, and leveraging LLMs to identify inconsistencies in law. This paper explores LLM capabilities in applying tax law. We choose this area of law because it has a structure that allows us to set up automated validation pipelines across thousands of examples, requires logical reasoning and maths skills, and enables us to test LLM capabilities in a manner relevant to real-world economic lives of citizens and companies. Our experiments demonstrate emerging legal understanding capabilities, with improved performance in each subsequent OpenAI model release. We experiment with retrieving and utilising the relevant legal authority to assess the impact of providing additional legal context to LLMs. Few-shot prompting, presenting examples of question-answer pairs, is also found to significantly enhance the performance of the most advanced model, GPT-4. The findings indicate that LLMs, particularly when combined with prompting enhancements and the correct legal texts, can perform at high levels of accuracy but not yet at expert tax lawyer levels. As LLMs continue to advance, their ability to reason about law autonomously could have significant implications for the legal profession and AI governance.