 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking the training data to correct for test set contamination
May 24, 2026The literature on test set contamination largely focuses on detection, but the correction of contaminated test scores is underexplored. Our core proposal is to spike the training data by intentionally contaminating some test examples at known rates. The spiked examples can then be used to calibrate predictors of model memorization which enable principled statistical correction of inflated test scores. To evaluate different correction estimators, we first present a simulation framework based on the Hubble models. Hubble models come in minimal pairs, where the perturbed model was deliberately contaminated with several test sets, while the standard model was not, serving as the counterfactual and correction target. We consider estimators that use information from a memorization predictor, correctness predictor, or both. In simulation, we establish basic statistical intuitions and show that estimators leveraging memorization and correctness information are better than naive estimation which makes no correction at all. We then instantiate several memorization and correctness predictors, and find that simple predictors such as Platt-scaled membership inference metrics provide good signal for correction. Finally, we examine the practical considerations of spiking. Simple memorization predictors need no more than 10 examples for calibration and often transfer from one dataset to another. Taken together, spiking is a promising solution for test set contamination.
Evaluating LLM-Simulated Conversations in Modeling Inconsistent and Uncollaborative Behaviors in Human Social Interaction
Mar 17, 2026Simulating human conversations using large language models (LLMs) has emerged as a scalable methodology for modeling human social interaction. However, simulating human conversations is challenging because they inherently involve inconsistent and uncollaborative behaviors, such as misunderstandings and interruptions. Analysis comparing inconsistent and uncollaborative behaviors in human- and LLM-generated conversations remains limited, although reproducing these behaviors is integral to simulating human-like and complex social interaction. In this work, we introduce CoCoEval, an evaluation framework that analyzes LLM-simulated conversations by detecting 10 types of inconsistent and uncollaborative behaviors at the turn level using an LLM-as-a-Judge. Using CoCoEval, we evaluate GPT-4.1, GPT-5.1, and Claude Opus 4 by comparing the frequencies of detected behaviors in conversations simulated by each model and in human conversations across academic, business, and governmental meetings, as well as debates. Our analysis shows that (1) under vanilla prompting, LLM-simulated conversations exhibit far fewer inconsistent and uncollaborative behaviors than human conversations; (2) prompt engineering does not provide reliable control over these behaviors, as our results show that different prompts lead to their under- or overproduction; and (3) supervised fine-tuning on human conversations can lead LLMs to overproduce a narrow set of behaviors, such as repetition. Our findings highlight the difficulty of simulating human conversations, raising concerns about the use of LLMs as a proxy for human social interaction.
Hubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Interrogating LLM design under a fair learning doctrine
Feb 22, 2025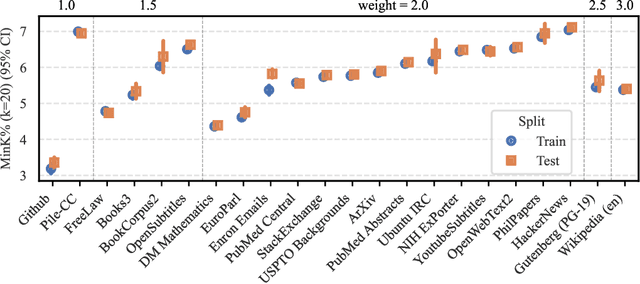
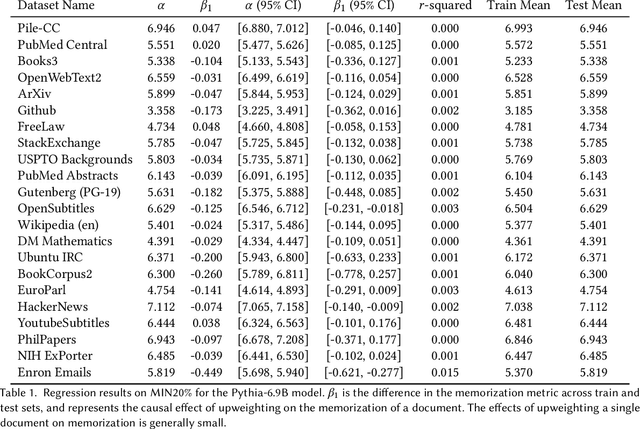
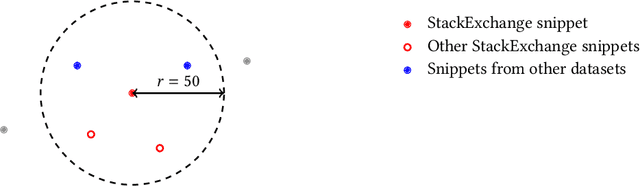
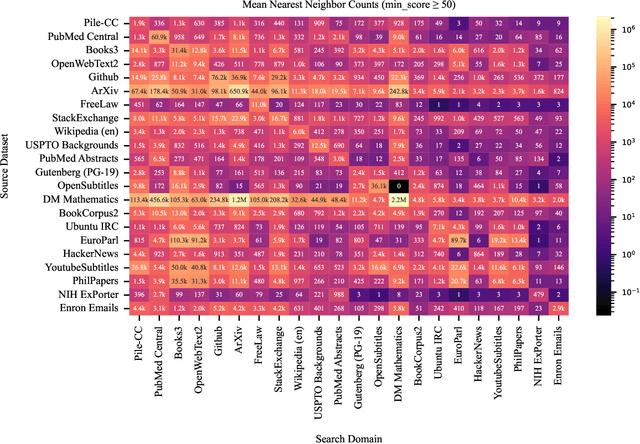
The current discourse on large language models (LLMs) and copyright largely takes a "behavioral" perspective, focusing on model outputs and evaluating whether they are substantially similar to training data. However, substantial similarity is difficult to define algorithmically and a narrow focus on model outputs is insufficient to address all copyright risks. In this interdisciplinary work, we take a complementary "structural" perspective and shift our focus to how LLMs are trained. We operationalize a notion of "fair learning" by measuring whether any training decision substantially affected the model's memorization. As a case study, we deconstruct Pythia, an open-source LLM, and demonstrate the use of causal and correlational analyses to make factual determinations about Pythia's training decisions. By proposing a legal standard for fair learning and connecting memorization analyses to this standard, we identify how judges may advance the goals of copyright law through adjudication. Finally, we discuss how a fair learning standard might evolve to enhance its clarity by becoming more rule-like and incorporating external technical guidelines.
Verify with Caution: The Pitfalls of Relying on Imperfect Factuality Metrics
Jan 24, 2025



Improvements in large language models have led to increasing optimism that they can serve as reliable evaluators of natural language generation outputs. In this paper, we challenge this optimism by thoroughly re-evaluating five state-of-the-art factuality metrics on a collection of 11 datasets for summarization, retrieval-augmented generation, and question answering. We find that these evaluators are inconsistent with each other and often misestimate system-level performance, both of which can lead to a variety of pitfalls. We further show that these metrics exhibit biases against highly paraphrased outputs and outputs that draw upon faraway parts of the source documents. We urge users of these factuality metrics to proceed with caution and manually validate the reliability of these metrics in their domain of interest before proceeding.
Analysis of Plan-based Retrieval for Grounded Text Generation
Aug 20, 2024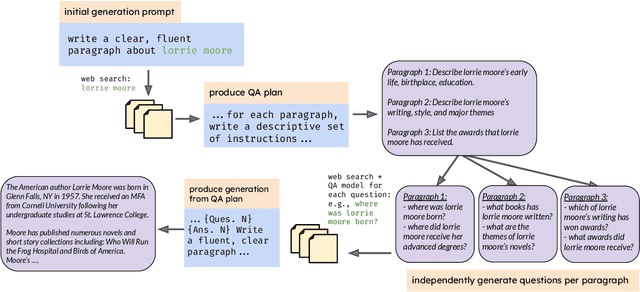
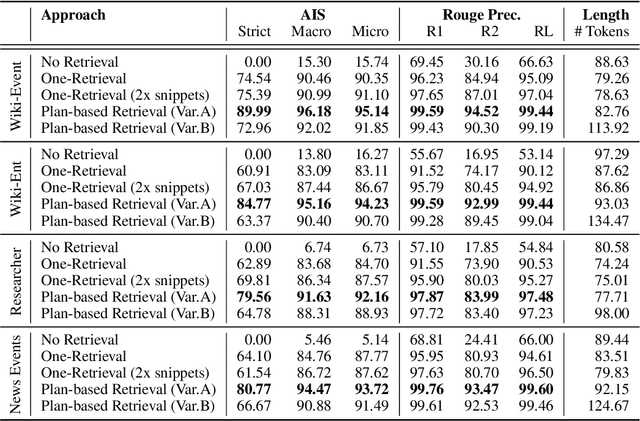

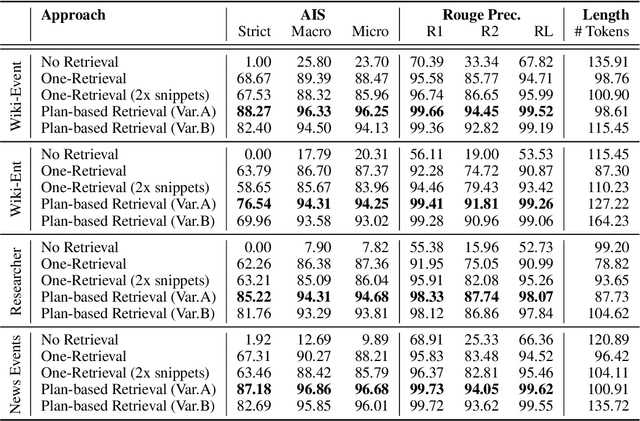
In text generation, hallucinations refer to the generation of seemingly coherent text that contradicts established knowledge. One compelling hypothesis is that hallucinations occur when a language model is given a generation task outside its parametric knowledge (due to rarity, recency, domain, etc.). A common strategy to address this limitation is to infuse the language models with retrieval mechanisms, providing the model with relevant knowledge for the task. In this paper, we leverage the planning capabilities of instruction-tuned LLMs and analyze how planning can be used to guide retrieval to further reduce the frequency of hallucinations. We empirically evaluate several variations of our proposed approach on long-form text generation tasks. By improving the coverage of relevant facts, plan-guided retrieval and generation can produce more informative responses while providing a higher rate of attribution to source documents.
SCENE: Self-Labeled Counterfactuals for Extrapolating to Negative Examples
May 13, 2023Detecting negatives (such as non-entailment relationships, unanswerable questions, and false claims) is an important and challenging aspect of many natural language understanding tasks. Though manually collecting challenging negative examples can help models detect them, it is both costly and domain-specific. In this work, we propose Self-labeled Counterfactuals for Extrapolating to Negative Examples (SCENE), an automatic method for synthesizing training data that greatly improves models' ability to detect challenging negative examples. In contrast with standard data augmentation, which synthesizes new examples for existing labels, SCENE can synthesize negative examples zero-shot from only positive ones. Given a positive example, SCENE perturbs it with a mask infilling model, then determines whether the resulting example is negative based on a self-training heuristic. With access to only answerable training examples, SCENE can close 69.6% of the performance gap on SQuAD 2.0, a dataset where half of the evaluation examples are unanswerable, compared to a model trained on SQuAD 2.0. Our method also extends to boolean question answering and recognizing textual entailment, and improves generalization from SQuAD to ACE-whQA, an out-of-domain extractive QA benchmark.
Benchmarking Long-tail Generalization with Likelihood Splits
Oct 13, 2022

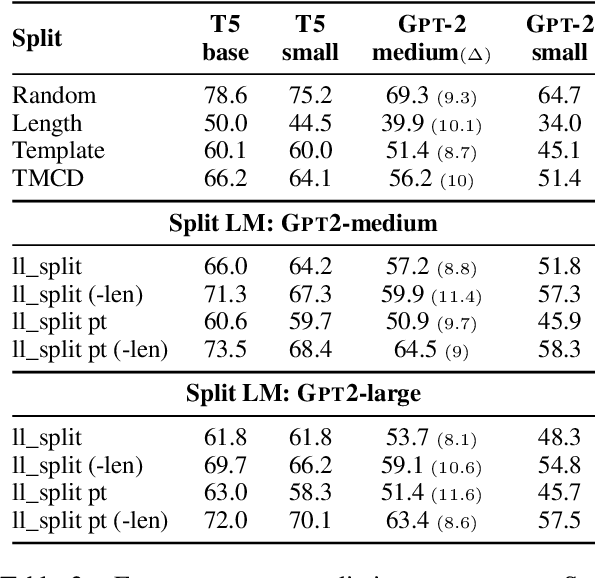
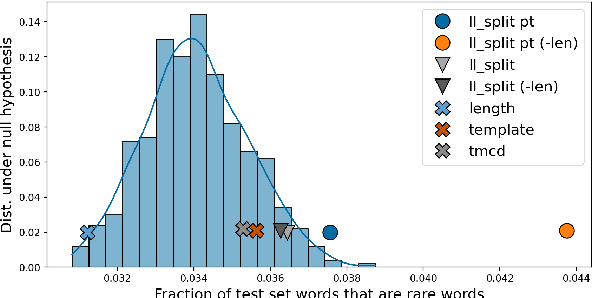
In order to reliably process natural language, NLP systems must generalize to the long tail of rare utterances. We propose a method to create challenging benchmarks that require generalizing to the tail of the distribution by re-splitting existing datasets. We create 'Likelihood splits' where examples that are assigned lower likelihood by a pre-trained language model (LM) are placed in the test set, and more likely examples are in the training set. This simple approach can be customized to construct meaningful train-test splits for a wide range of tasks. Likelihood splits are more challenging than random splits: relative error rates of state-of-the-art models on our splits increase by 59% for semantic parsing on Spider, 77% for natural language inference on SNLI, and 38% for yes/no question answering on BoolQ compared with the corresponding random splits. Moreover, Likelihood splits create fairer benchmarks than adversarial filtering; when the LM used to create the splits is used as the task model, our splits do not adversely penalize the LM.
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs
Feb 22, 2022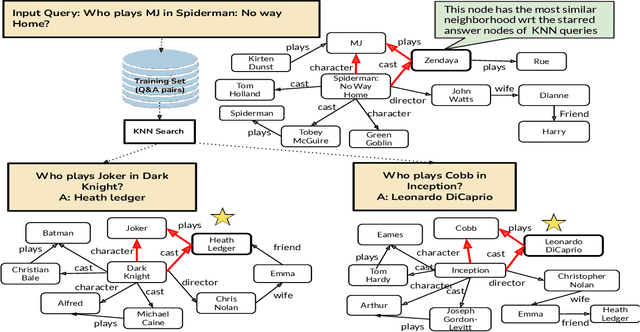
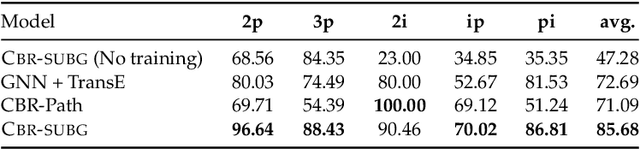
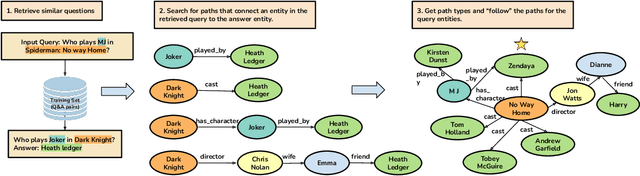
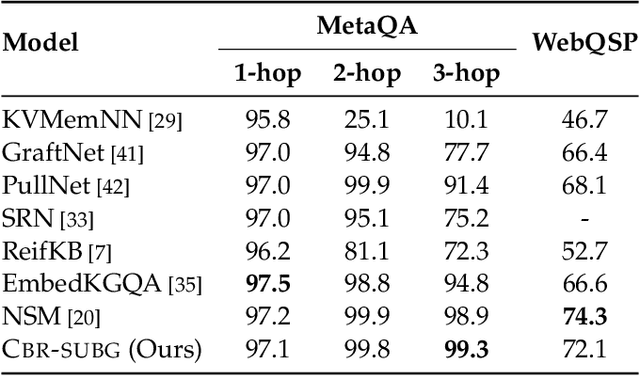
Question answering (QA) over real-world knowledge bases (KBs) is challenging because of the diverse (essentially unbounded) types of reasoning patterns needed. However, we hypothesize in a large KB, reasoning patterns required to answer a query type reoccur for various entities in their respective subgraph neighborhoods. Leveraging this structural similarity between local neighborhoods of different subgraphs, we introduce a semiparametric model with (i) a nonparametric component that for each query, dynamically retrieves other similar $k$-nearest neighbor (KNN) training queries along with query-specific subgraphs and (ii) a parametric component that is trained to identify the (latent) reasoning patterns from the subgraphs of KNN queries and then apply it to the subgraph of the target query. We also propose a novel algorithm to select a query-specific compact subgraph from within the massive knowledge graph (KG), allowing us to scale to full Freebase KG containing billions of edges. We show that our model answers queries requiring complex reasoning patterns more effectively than existing KG completion algorithms. The proposed model outperforms or performs competitively with state-of-the-art models on several KBQA benchmarks.
Case-based Reasoning for Natural Language Queries over Knowledge Bases
Apr 18, 2021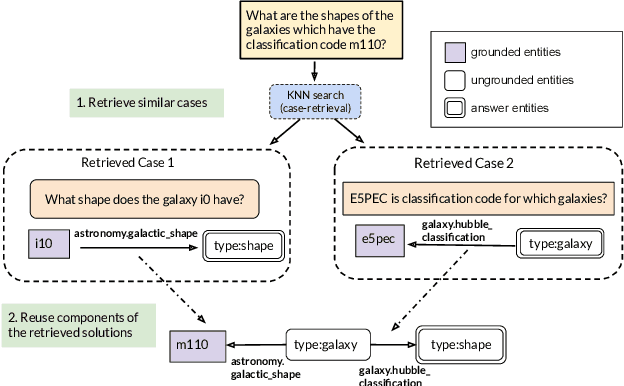
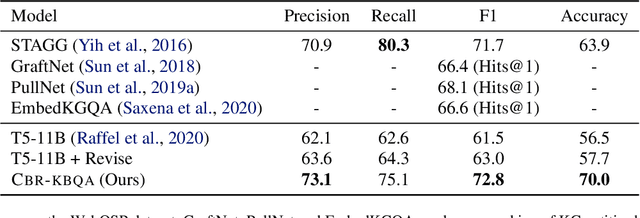
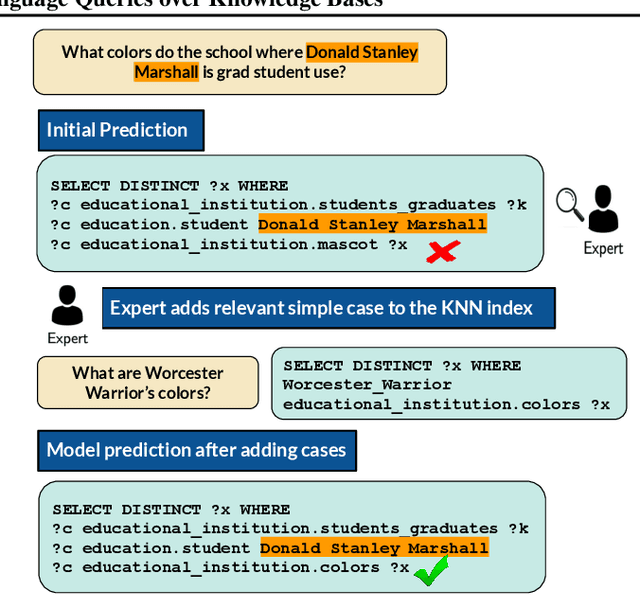
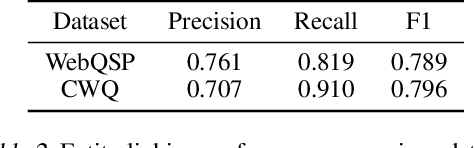
It is often challenging for a system to solve a new complex problem from scratch, but much easier if the system can access other similar problems and description of their solutions -- a paradigm known as case-based reasoning (CBR). We propose a neuro-symbolic CBR approach for question answering over large knowledge bases (CBR-KBQA). While the idea of CBR is tempting, composing a solution from cases is nontrivial, when individual cases only contain partial logic to the full solution. To resolve this, CBR-KBQA consists of two modules: a non-parametric memory that stores cases (question and logical forms) and a parametric model which can generate logical forms by retrieving relevant cases from memory. Through experiments, we show that CBR-KBQA can effectively derive novel combination of relations not presented in case memory that is required to answer compositional questions. On several KBQA datasets that test compositional generalization, CBR-KBQA achieves competitive performance. For example, on the challenging ComplexWebQuestions dataset, CBR-KBQA outperforms the current state of the art by 11% accuracy. Furthermore, we show that CBR-KBQA is capable of using new cases \emph{without} any further training. Just by incorporating few human-labeled examples in the non-parametric case memory, CBR-KBQA is able to successfully generate queries containing unseen KB relations.