 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Robust Data Watermarking in Language Models by Injecting Fictitious Knowledge
Mar 06, 2025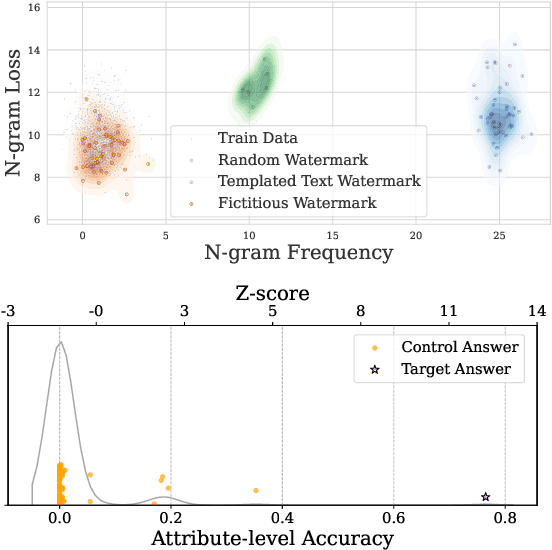

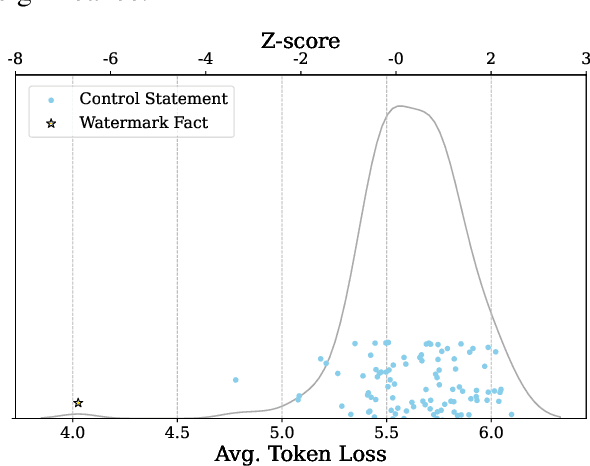

Data watermarking in language models injects traceable signals, such as specific token sequences or stylistic patterns, into copyrighted text, allowing copyright holders to track and verify training data ownership. Previous data watermarking techniques primarily focus on effective memorization after pretraining, while overlooking challenges that arise in other stages of the LLM pipeline, such as the risk of watermark filtering during data preprocessing, or potential forgetting through post-training, or verification difficulties due to API-only access. We propose a novel data watermarking approach that injects coherent and plausible yet fictitious knowledge into training data using generated passages describing a fictitious entity and its associated attributes. Our watermarks are designed to be memorized by the LLM through seamlessly integrating in its training data, making them harder to detect lexically during preprocessing.We demonstrate that our watermarks can be effectively memorized by LLMs, and that increasing our watermarks' density, length, and diversity of attributes strengthens their memorization. We further show that our watermarks remain robust throughout LLM development, maintaining their effectiveness after continual pretraining and supervised finetuning. Finally, we show that our data watermarks can be evaluated even under API-only access via question answering.
Interrogating LLM design under a fair learning doctrine
Feb 22, 2025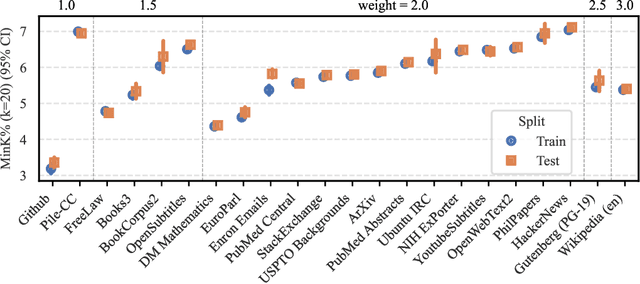
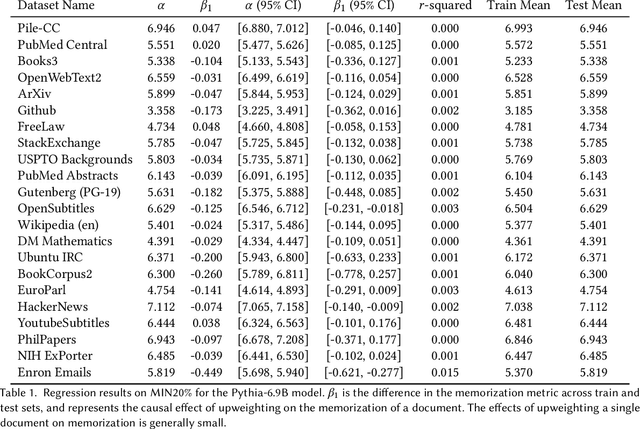
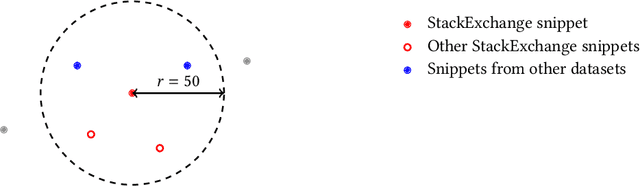
The current discourse on large language models (LLMs) and copyright largely takes a "behavioral" perspective, focusing on model outputs and evaluating whether they are substantially similar to training data. However, substantial similarity is difficult to define algorithmically and a narrow focus on model outputs is insufficient to address all copyright risks. In this interdisciplinary work, we take a complementary "structural" perspective and shift our focus to how LLMs are trained. We operationalize a notion of "fair learning" by measuring whether any training decision substantially affected the model's memorization. As a case study, we deconstruct Pythia, an open-source LLM, and demonstrate the use of causal and correlational analyses to make factual determinations about Pythia's training decisions. By proposing a legal standard for fair learning and connecting memorization analyses to this standard, we identify how judges may advance the goals of copyright law through adjudication. Finally, we discuss how a fair learning standard might evolve to enhance its clarity by becoming more rule-like and incorporating external technical guidelines.
Proving membership in LLM pretraining data via data watermarks
Feb 16, 2024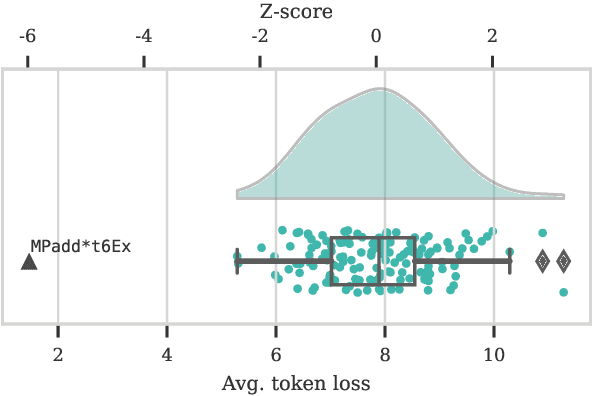

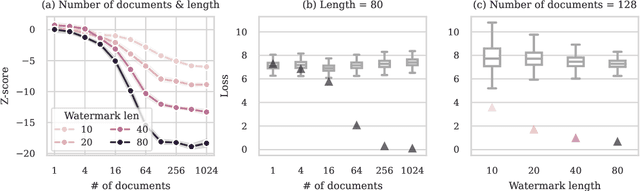
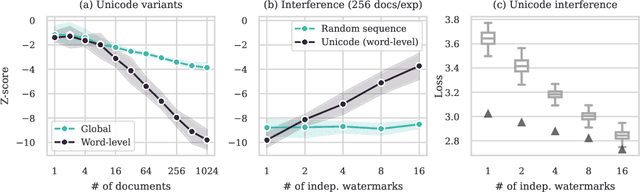
Detecting whether copyright holders' works were used in LLM pretraining is poised to be an important problem. This work proposes using data watermarks to enable principled detection with only black-box model access, provided that the rightholder contributed multiple training documents and watermarked them before public release. By applying a randomly sampled data watermark, detection can be framed as hypothesis testing, which provides guarantees on the false detection rate. We study two watermarks: one that inserts random sequences, and another that randomly substitutes characters with Unicode lookalikes. We first show how three aspects of watermark design -- watermark length, number of duplications, and interference -- affect the power of the hypothesis test. Next, we study how a watermark's detection strength changes under model and dataset scaling: while increasing the dataset size decreases the strength of the watermark, watermarks remain strong if the model size also increases. Finally, we view SHA hashes as natural watermarks and show that we can robustly detect hashes from BLOOM-176B's training data, as long as they occurred at least 90 times. Together, our results point towards a promising future for data watermarks in real world use.
The statistical advantage of automatic NLG metrics at the system level
May 26, 2021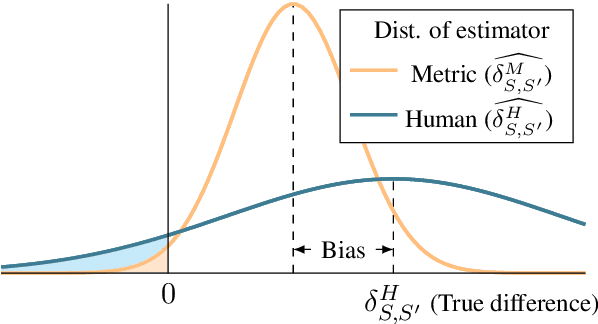

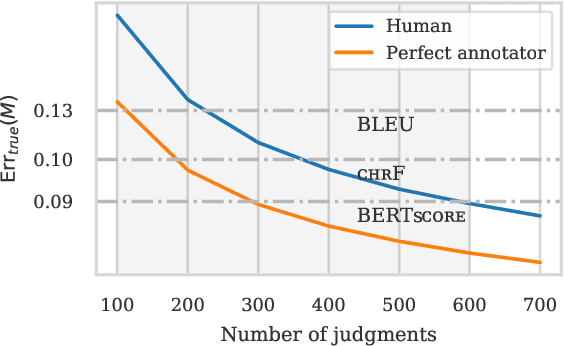

Estimating the expected output quality of generation systems is central to NLG. This paper qualifies the notion that automatic metrics are not as good as humans in estimating system-level quality. Statistically, humans are unbiased, high variance estimators, while metrics are biased, low variance estimators. We compare these estimators by their error in pairwise prediction (which generation system is better?) using the bootstrap. Measuring this error is complicated: predictions are evaluated against noisy, human predicted labels instead of the ground truth, and metric predictions fluctuate based on the test sets they were calculated on. By applying a bias-variance-noise decomposition, we adjust this error to a noise-free, infinite test set setting. Our analysis compares the adjusted error of metrics to humans and a derived, perfect segment-level annotator, both of which are unbiased estimators dependent on the number of judgments collected. In MT, we identify two settings where metrics outperform humans due to a statistical advantage in variance: when the number of human judgments used is small, and when the quality difference between compared systems is small. The data and code to reproduce our analyses are available at https://github.com/johntzwei/metric-statistical-advantage .
On conducting better validation studies of automatic metrics in natural language generation evaluation
Jul 31, 2019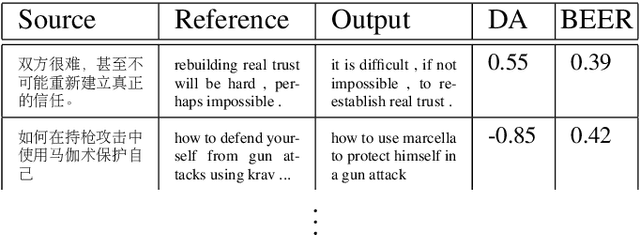
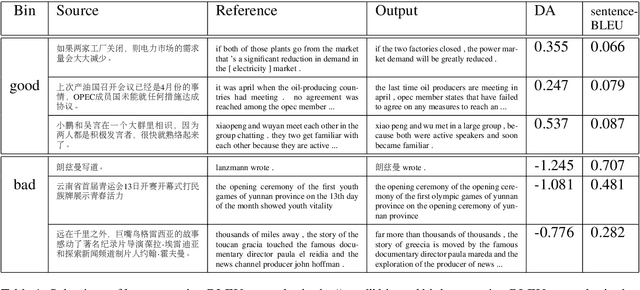
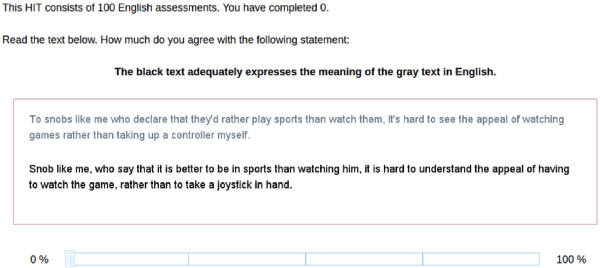
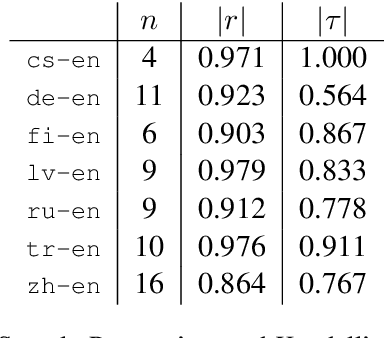
Natural language generation (NLG) has received increasing attention, which has highlighted evaluation as a central methodological concern. Since human evaluations for these systems are costly, automatic metrics have broad appeal in NLG. Research in language generation often finds situations where it is appropriate to apply existing metrics or propose new ones. The application of these metrics are entirely dependent on validation studies - studies that determine a metric's correlation to human judgment. However, there are many details and considerations in conducting strong validation studies. This document is intended for those validating existing metrics or proposing new ones in the broad context of NLG: we 1) begin with a write-up of best practices in validation studies, 2) outline how to adopt these practices, 3) conduct analyses in the WMT'17 metrics shared task\footnote{Our jupyter notebook containing the analyses is available at \url{https://github.com}}, and 4) highlight promising approaches to NLG metrics 5) conclude with our opinions on the future of this area.
Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings
Apr 24, 2019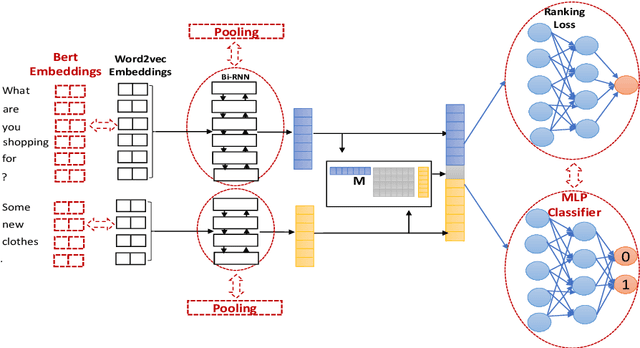
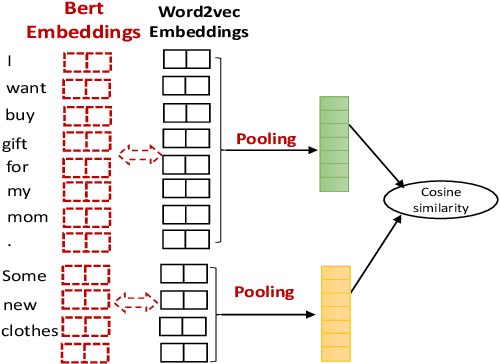

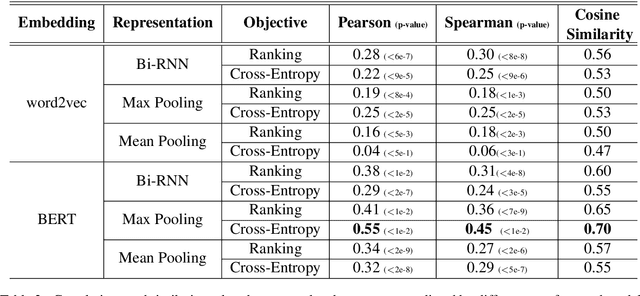
Despite advances in open-domain dialogue systems, automatic evaluation of such systems is still a challenging problem. Traditional reference-based metrics such as BLEU are ineffective because there could be many valid responses for a given context that share no common words with reference responses. A recent work proposed Referenced metric and Unreferenced metric Blended Evaluation Routine (RUBER) to combine a learning-based metric, which predicts relatedness between a generated response and a given query, with reference-based metric; it showed high correlation with human judgments. In this paper, we explore using contextualized word embeddings to compute more accurate relatedness scores, thus better evaluation metrics. Experiments show that our evaluation metrics outperform RUBER, which is trained on static embeddings.
Evaluating Syntactic Properties of Seq2seq Output with a Broad Coverage HPSG: A Case Study on Machine Translation
Sep 06, 2018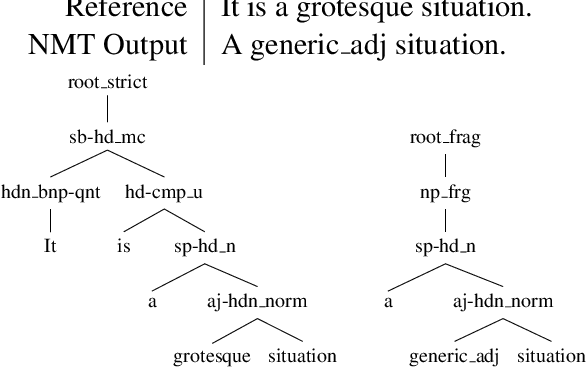
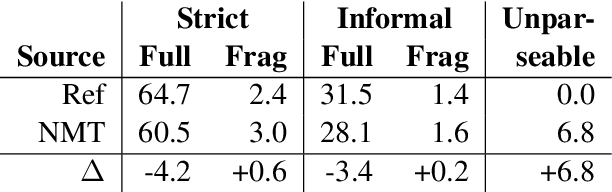

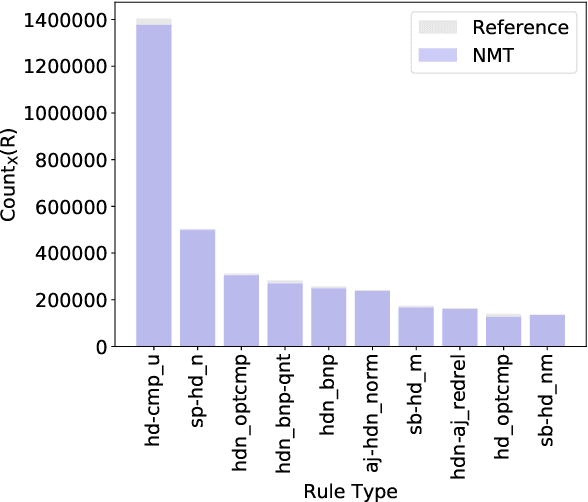
Sequence to sequence (seq2seq) models are often employed in settings where the target output is natural language. However, the syntactic properties of the language generated from these models are not well understood. We explore whether such output belongs to a formal and realistic grammar, by employing the English Resource Grammar (ERG), a broad coverage, linguistically precise HPSG-based grammar of English. From a French to English parallel corpus, we analyze the parseability and grammatical constructions occurring in output from a seq2seq translation model. Over 93\% of the model translations are parseable, suggesting that it learns to generate conforming to a grammar. The model has trouble learning the distribution of rarer syntactic rules, and we pinpoint several constructions that differentiate translations between the references and our model.