 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn conducting better validation studies of automatic metrics in natural language generation evaluation
Paper and Code
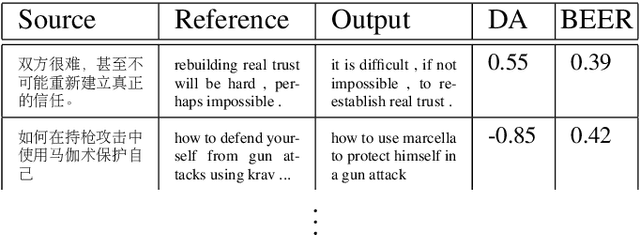
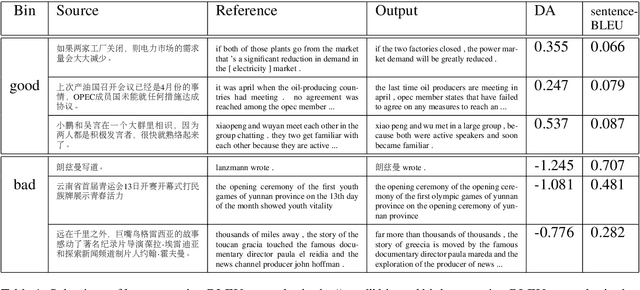
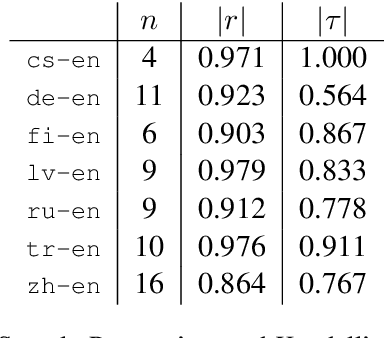
Natural language generation (NLG) has received increasing attention, which has highlighted evaluation as a central methodological concern. Since human evaluations for these systems are costly, automatic metrics have broad appeal in NLG. Research in language generation often finds situations where it is appropriate to apply existing metrics or propose new ones. The application of these metrics are entirely dependent on validation studies - studies that determine a metric's correlation to human judgment. However, there are many details and considerations in conducting strong validation studies. This document is intended for those validating existing metrics or proposing new ones in the broad context of NLG: we 1) begin with a write-up of best practices in validation studies, 2) outline how to adopt these practices, 3) conduct analyses in the WMT'17 metrics shared task\footnote{Our jupyter notebook containing the analyses is available at \url{https://github.com}}, and 4) highlight promising approaches to NLG metrics 5) conclude with our opinions on the future of this area.