 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman acceptability judgements for extractive sentence compression
Feb 01, 2019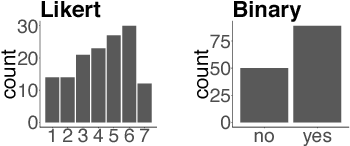
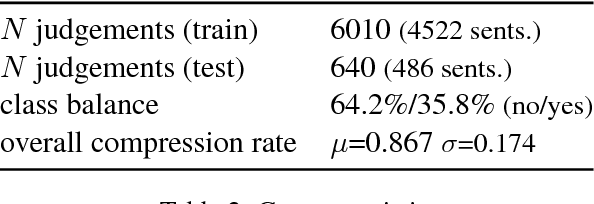
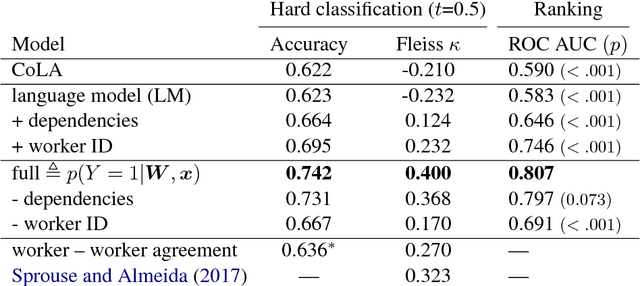
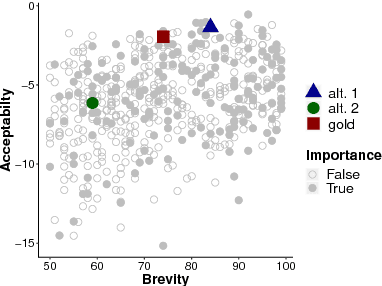
Recent approaches to English-language sentence compression rely on parallel corpora consisting of sentence-compression pairs. However, a sentence may be shortened in many different ways, which each might be suited to the needs of a particular application. Therefore, in this work, we collect and model crowdsourced judgements of the acceptability of many possible sentence shortenings. We then show how a model of such judgements can be used to support a flexible approach to the compression task. We release our model and dataset for future work.
Evaluating Syntactic Properties of Seq2seq Output with a Broad Coverage HPSG: A Case Study on Machine Translation
Sep 06, 2018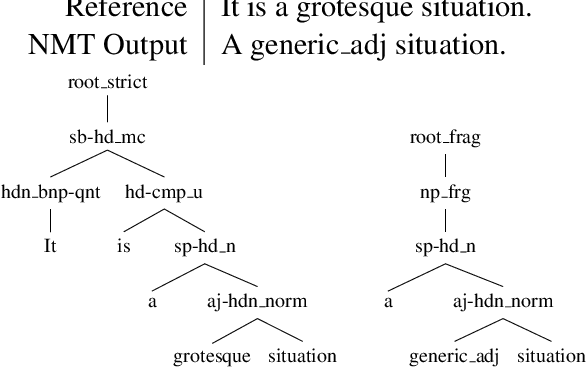
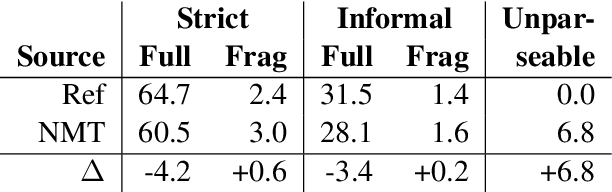

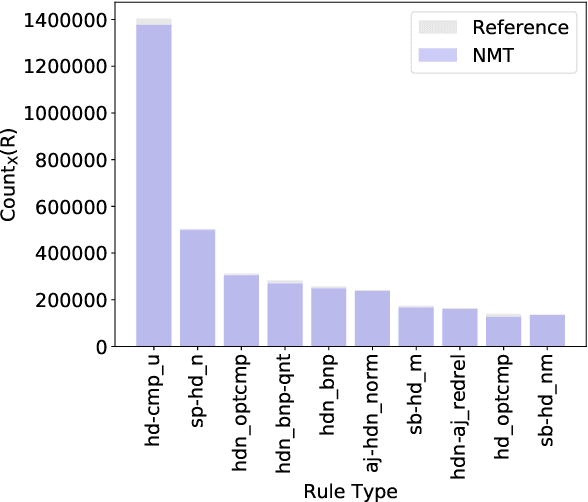
Sequence to sequence (seq2seq) models are often employed in settings where the target output is natural language. However, the syntactic properties of the language generated from these models are not well understood. We explore whether such output belongs to a formal and realistic grammar, by employing the English Resource Grammar (ERG), a broad coverage, linguistically precise HPSG-based grammar of English. From a French to English parallel corpus, we analyze the parseability and grammatical constructions occurring in output from a seq2seq translation model. Over 93\% of the model translations are parseable, suggesting that it learns to generate conforming to a grammar. The model has trouble learning the distribution of rarer syntactic rules, and we pinpoint several constructions that differentiate translations between the references and our model.