 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Sports Commentator Bias within a Large Corpus of American Football Broadcasts
Oct 19, 2019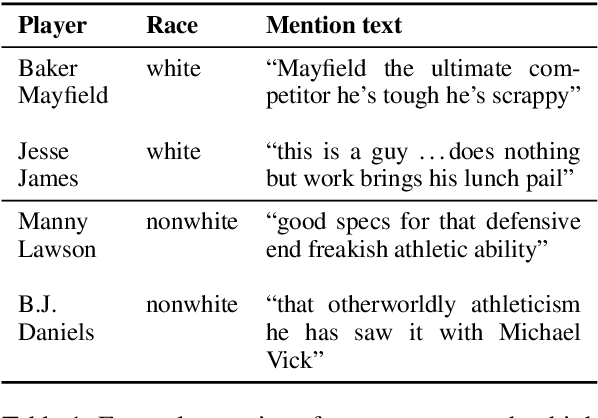
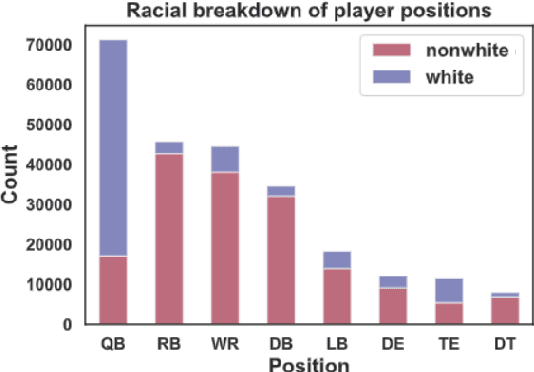
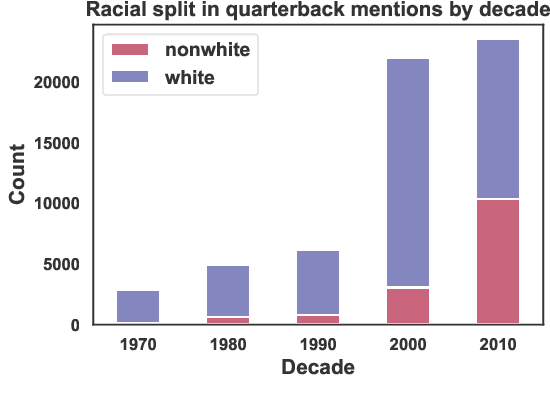
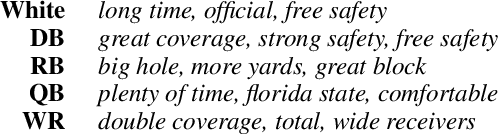
Sports broadcasters inject drama into play-by-play commentary by building team and player narratives through subjective analyses and anecdotes. Prior studies based on small datasets and manual coding show that such theatrics evince commentator bias in sports broadcasts. To examine this phenomenon, we assemble FOOTBALL, which contains 1,455 broadcast transcripts from American football games across six decades that are automatically annotated with 250K player mentions and linked with racial metadata. We identify major confounding factors for researchers examining racial bias in FOOTBALL, and perform a computational analysis that supports conclusions from prior social science studies.
Query-focused Sentence Compression in Linear Time
Apr 19, 2019

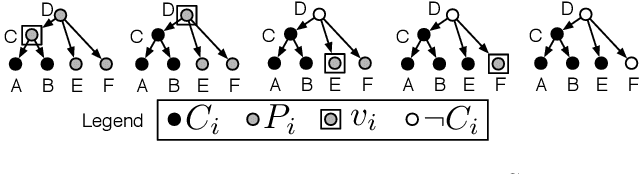
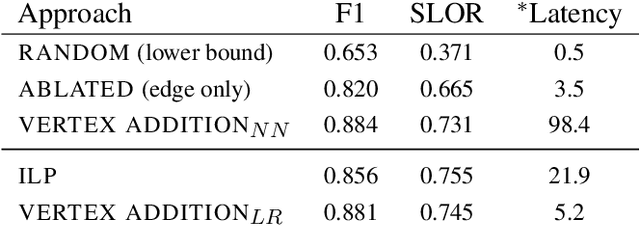
Search applications often display shortened sentences which must contain certain query terms and must fit within the space constraints of a user interface. This work introduces a new transition-based sentence compression technique developed for such settings. Our method constructs length and lexically constrained compressions in linear time, by growing a subgraph in the dependency parse of a sentence. This approach achieves a 4x speed up over baseline ILP compression techniques, and better reconstructs gold shortenings under constraints. Such efficiency gains permit constrained compression of multiple sentences, without unreasonable lag.
Human acceptability judgements for extractive sentence compression
Feb 01, 2019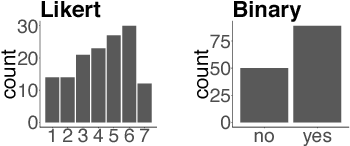
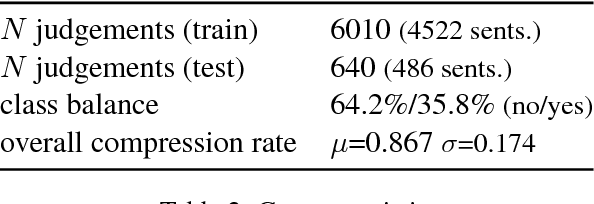
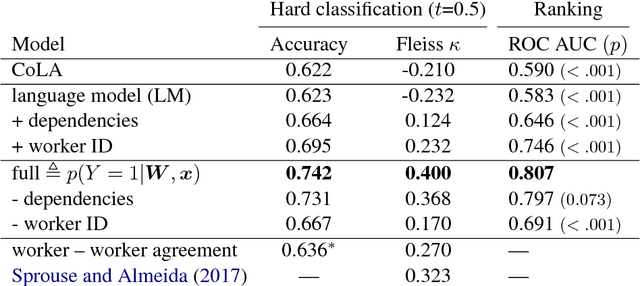
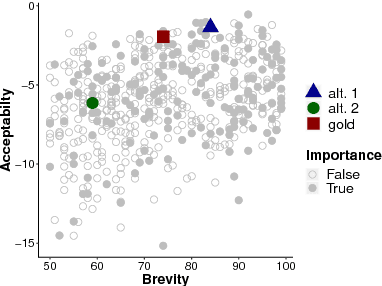
Recent approaches to English-language sentence compression rely on parallel corpora consisting of sentence-compression pairs. However, a sentence may be shortened in many different ways, which each might be suited to the needs of a particular application. Therefore, in this work, we collect and model crowdsourced judgements of the acceptability of many possible sentence shortenings. We then show how a model of such judgements can be used to support a flexible approach to the compression task. We release our model and dataset for future work.
Rookie: A unique approach for exploring news archives
Aug 06, 2017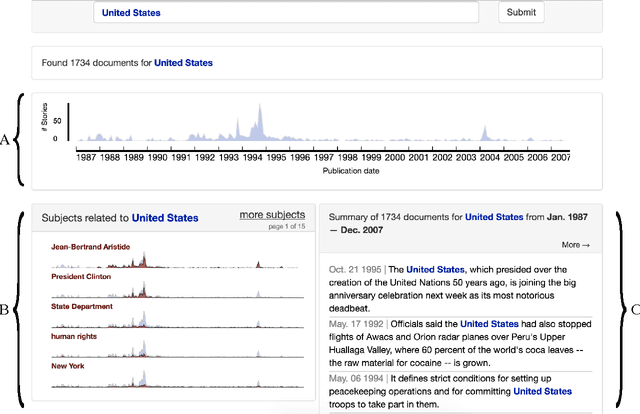
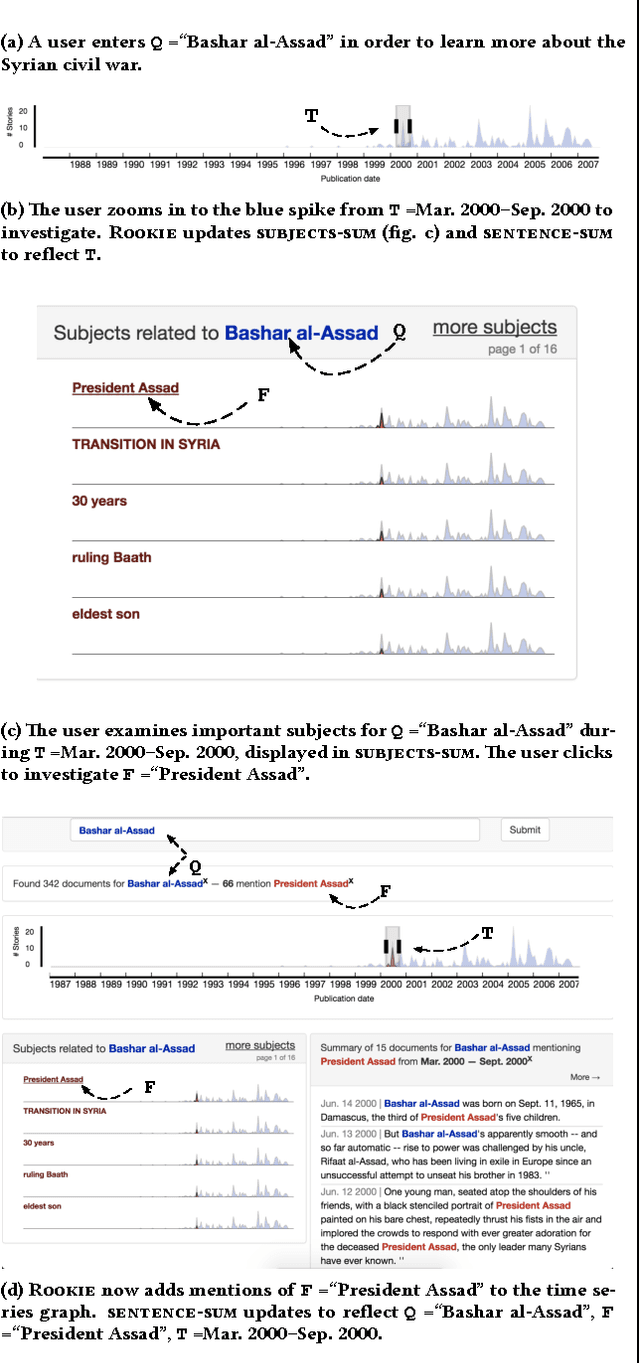
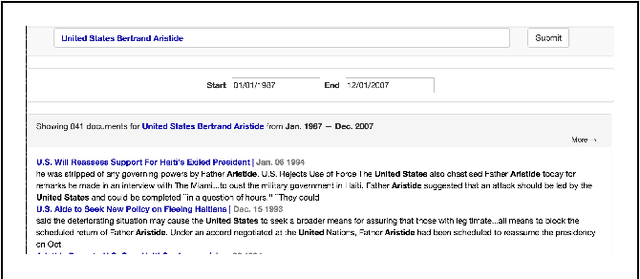
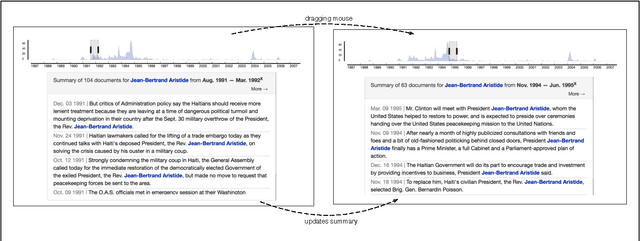
News archives are an invaluable primary source for placing current events in historical context. But current search engine tools do a poor job at uncovering broad themes and narratives across documents. We present Rookie: a practical software system which uses natural language processing (NLP) to help readers, reporters and editors uncover broad stories in news archives. Unlike prior work, Rookie's design emerged from 18 months of iterative development in consultation with editors and computational journalists. This process lead to a dramatically different approach from previous academic systems with similar goals. Our efforts offer a generalizable case study for others building real-world journalism software using NLP.
Identifying civilians killed by police with distantly supervised entity-event extraction
Jul 22, 2017

We propose a new, socially-impactful task for natural language processing: from a news corpus, extract names of persons who have been killed by police. We present a newly collected police fatality corpus, which we release publicly, and present a model to solve this problem that uses EM-based distant supervision with logistic regression and convolutional neural network classifiers. Our model outperforms two off-the-shelf event extractor systems, and it can suggest candidate victim names in some cases faster than one of the major manually-collected police fatality databases.
Visualizing textual models with in-text and word-as-pixel highlighting
Jun 20, 2016
We explore two techniques which use color to make sense of statistical text models. One method uses in-text annotations to illustrate a model's view of particular tokens in particular documents. Another uses a high-level, "words-as-pixels" graphic to display an entire corpus. Together, these methods offer both zoomed-in and zoomed-out perspectives into a model's understanding of text. We show how these interconnected methods help diagnose a classifier's poor performance on Twitter slang, and make sense of a topic model on historical political texts.