 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
Examining Pathological Bias in a Generative Adversarial Network Discriminator: A Case Study on a StyleGAN3 Model
Feb 16, 2024
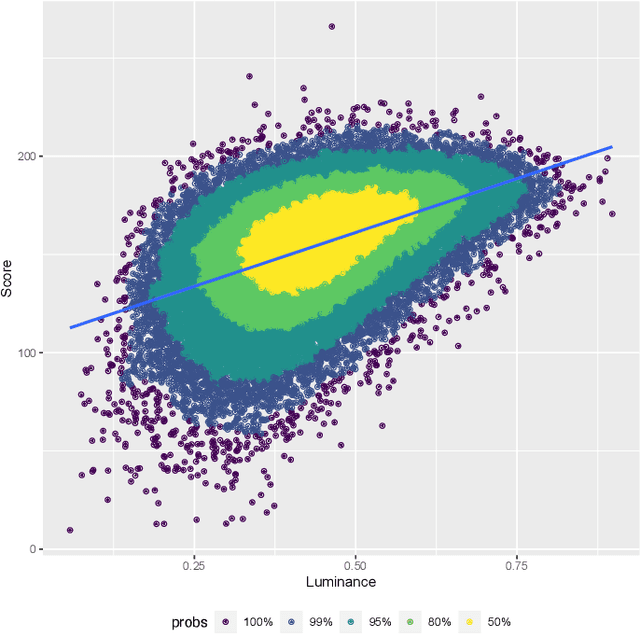


Generative adversarial networks generate photorealistic faces that are often indistinguishable by humans from real faces. We find that the discriminator in the pre-trained StyleGAN3 model, a popular GAN network, systematically stratifies scores by both image- and face-level qualities and that this disproportionately affects images across gender, race, and other categories. We examine the discriminator's bias for color and luminance across axes perceived race and gender; we then examine axes common in research on stereotyping in social psychology.
Rare but Severe Neural Machine Translation Errors Induced by Minimal Deletion: An Empirical Study on Chinese and English
Sep 17, 2022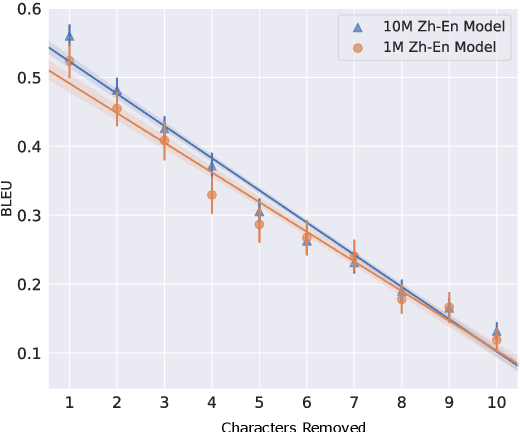

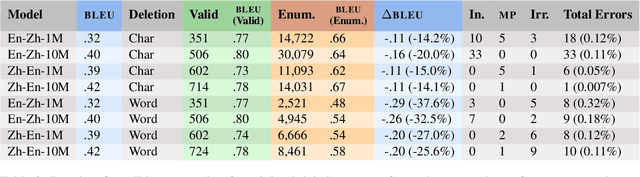
We examine the inducement of rare but severe errors in English-Chinese and Chinese-English in-domain neural machine translation by minimal deletion of the source text with character-based models. By deleting a single character, we can induce severe translation errors. We categorize these errors and compare the results of deleting single characters and single words. We also examine the effect of training data size on the number and types of pathological cases induced by these minimal perturbations, finding significant variation. We find that deleting a word hurts overall translation score more than deleting a character, but certain errors are more likely to occur when deleting characters, with language direction also influencing the effect.
Investigating Sports Commentator Bias within a Large Corpus of American Football Broadcasts
Oct 19, 2019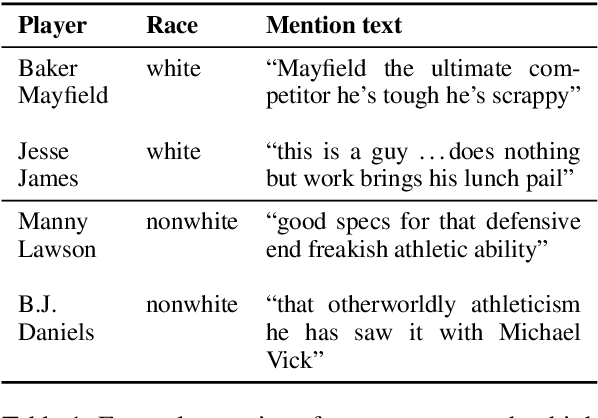
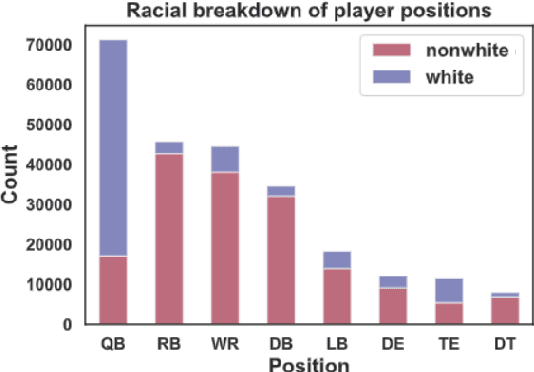
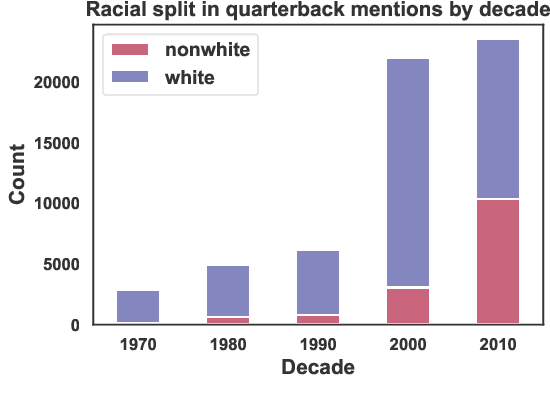
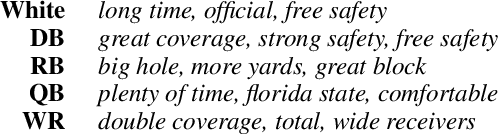
Sports broadcasters inject drama into play-by-play commentary by building team and player narratives through subjective analyses and anecdotes. Prior studies based on small datasets and manual coding show that such theatrics evince commentator bias in sports broadcasts. To examine this phenomenon, we assemble FOOTBALL, which contains 1,455 broadcast transcripts from American football games across six decades that are automatically annotated with 250K player mentions and linked with racial metadata. We identify major confounding factors for researchers examining racial bias in FOOTBALL, and perform a computational analysis that supports conclusions from prior social science studies.
Pathologies of Neural Models Make Interpretations Difficult
Aug 28, 2018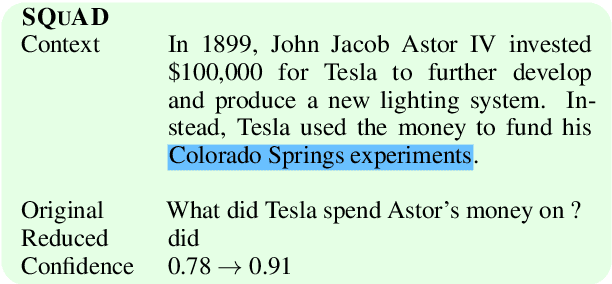
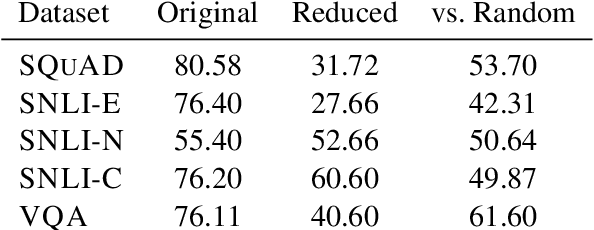

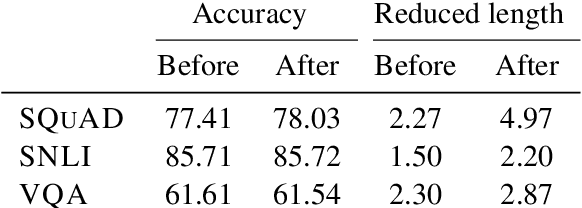
One way to interpret neural model predictions is to highlight the most important input features---for example, a heatmap visualization over the words in an input sentence. In existing interpretation methods for NLP, a word's importance is determined by either input perturbation---measuring the decrease in model confidence when that word is removed---or by the gradient with respect to that word. To understand the limitations of these methods, we use input reduction, which iteratively removes the least important word from the input. This exposes pathological behaviors of neural models: the remaining words appear nonsensical to humans and are not the ones determined as important by interpretation methods. As we confirm with human experiments, the reduced examples lack information to support the prediction of any label, but models still make the same predictions with high confidence. To explain these counterintuitive results, we draw connections to adversarial examples and confidence calibration: pathological behaviors reveal difficulties in interpreting neural models trained with maximum likelihood. To mitigate their deficiencies, we fine-tune the models by encouraging high entropy outputs on reduced examples. Fine-tuned models become more interpretable under input reduction without accuracy loss on regular examples.