Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare but Severe Neural Machine Translation Errors Induced by Minimal Deletion: An Empirical Study on Chinese and English
Sep 17, 2022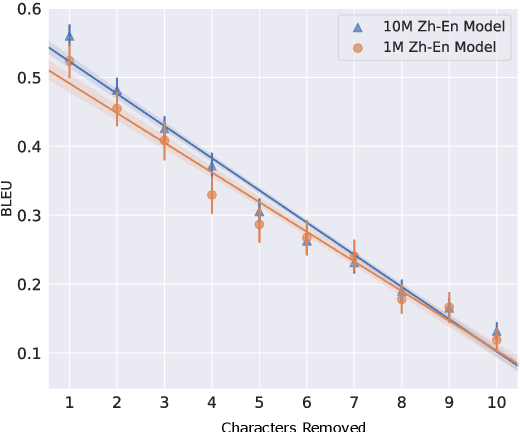

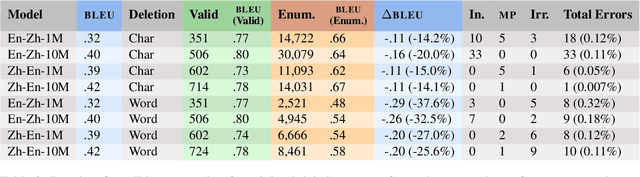
We examine the inducement of rare but severe errors in English-Chinese and Chinese-English in-domain neural machine translation by minimal deletion of the source text with character-based models. By deleting a single character, we can induce severe translation errors. We categorize these errors and compare the results of deleting single characters and single words. We also examine the effect of training data size on the number and types of pathological cases induced by these minimal perturbations, finding significant variation. We find that deleting a word hurts overall translation score more than deleting a character, but certain errors are more likely to occur when deleting characters, with language direction also influencing the effect.
* COLING 2022 Camera Ready
Via