Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman acceptability judgements for extractive sentence compression
Paper and Code
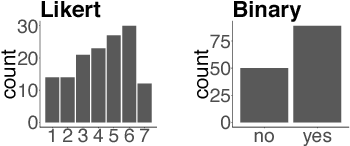
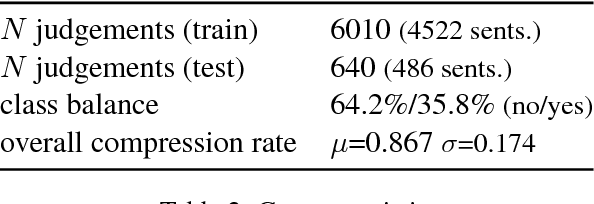
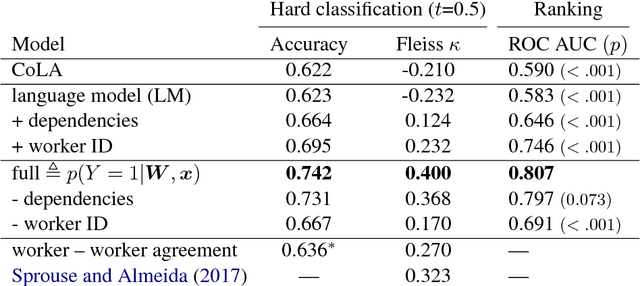
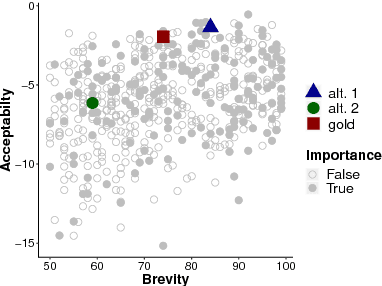
Recent approaches to English-language sentence compression rely on parallel corpora consisting of sentence-compression pairs. However, a sentence may be shortened in many different ways, which each might be suited to the needs of a particular application. Therefore, in this work, we collect and model crowdsourced judgements of the acceptability of many possible sentence shortenings. We then show how a model of such judgements can be used to support a flexible approach to the compression task. We release our model and dataset for future work.
View paper on