 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe statistical advantage of automatic NLG metrics at the system level
Paper and Code
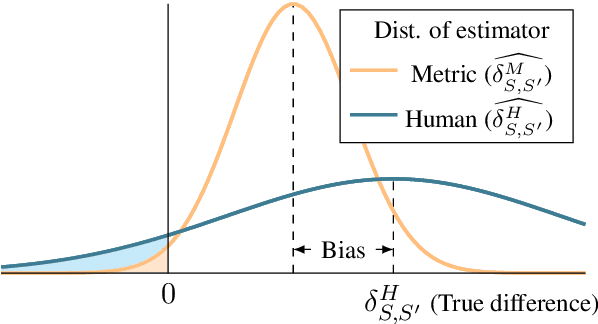

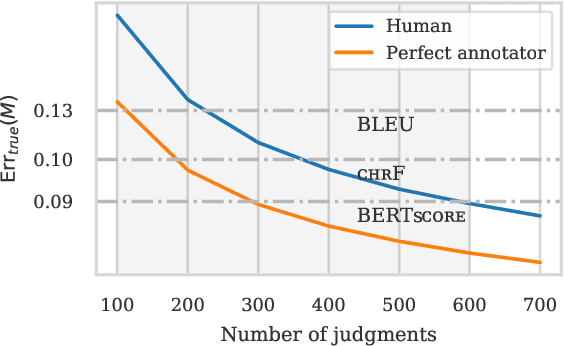

Estimating the expected output quality of generation systems is central to NLG. This paper qualifies the notion that automatic metrics are not as good as humans in estimating system-level quality. Statistically, humans are unbiased, high variance estimators, while metrics are biased, low variance estimators. We compare these estimators by their error in pairwise prediction (which generation system is better?) using the bootstrap. Measuring this error is complicated: predictions are evaluated against noisy, human predicted labels instead of the ground truth, and metric predictions fluctuate based on the test sets they were calculated on. By applying a bias-variance-noise decomposition, we adjust this error to a noise-free, infinite test set setting. Our analysis compares the adjusted error of metrics to humans and a derived, perfect segment-level annotator, both of which are unbiased estimators dependent on the number of judgments collected. In MT, we identify two settings where metrics outperform humans due to a statistical advantage in variance: when the number of human judgments used is small, and when the quality difference between compared systems is small. The data and code to reproduce our analyses are available at https://github.com/johntzwei/metric-statistical-advantage .