 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Reading Comprehension using Case-based Reasoning
May 24, 2023



We present an accurate and interpretable method for answer extraction in machine reading comprehension that is reminiscent of case-based reasoning (CBR) from classical AI. Our method (CBR-MRC) builds on the hypothesis that contextualized answers to similar questions share semantic similarities with each other. Given a target question, CBR-MRC retrieves a set of similar questions from a memory of observed cases and predicts an answer by selecting the span in the target context that is most similar to the contextualized representations of answers in the retrieved cases. The semi-parametric nature of our approach allows CBR-MRC to attribute a prediction to the specific set of cases used during inference, making it a desirable choice for building reliable and debuggable QA systems. We show that CBR-MRC achieves high test accuracy comparable with large reader models, outperforming baselines by 11.5 and 8.4 EM on NaturalQuestions and NewsQA, respectively. Further, we also demonstrate the ability of CBR-MRC in identifying not just the correct answer tokens but also the span with the most relevant supporting evidence. Lastly, we observe that contexts for certain question types show higher lexical diversity than others and find CBR-MRC to be robust to these variations while performance using fully-parametric methods drops.
CBR-iKB: A Case-Based Reasoning Approach for Question Answering over Incomplete Knowledge Bases
Apr 18, 2022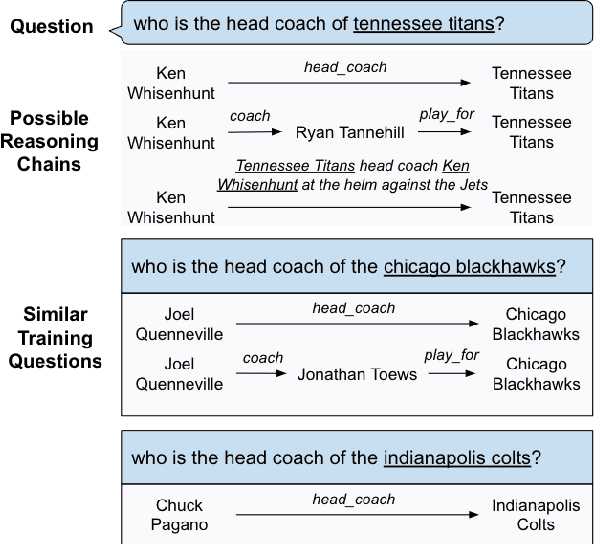
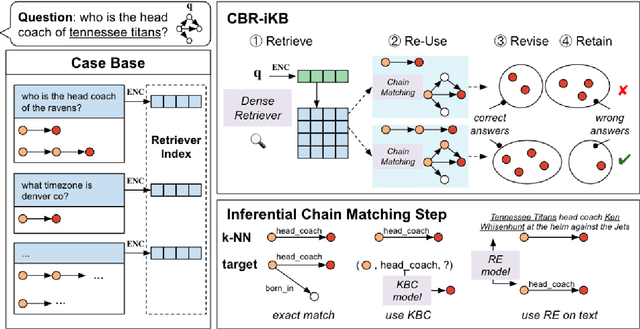
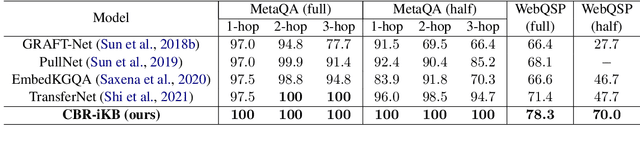
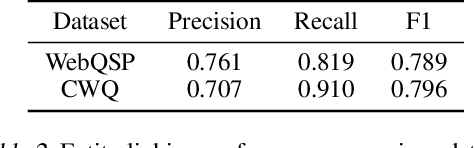
Knowledge bases (KBs) are often incomplete and constantly changing in practice. Yet, in many question answering applications coupled with knowledge bases, the sparse nature of KBs is often overlooked. To this end, we propose a case-based reasoning approach, CBR-iKB, for knowledge base question answering (KBQA) with incomplete-KB as our main focus. Our method ensembles decisions from multiple reasoning chains with a novel nonparametric reasoning algorithm. By design, CBR-iKB can seamlessly adapt to changes in KBs without any task-specific training or fine-tuning. Our method achieves 100% accuracy on MetaQA and establishes new state-of-the-art on multiple benchmarks. For instance, CBR-iKB achieves an accuracy of 70% on WebQSP under the incomplete-KB setting, outperforming the existing state-of-the-art method by 22.3%.
TABBIE: Pretrained Representations of Tabular Data
May 06, 2021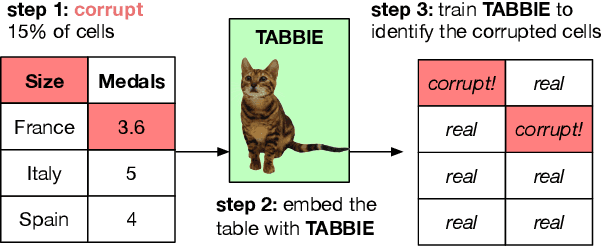
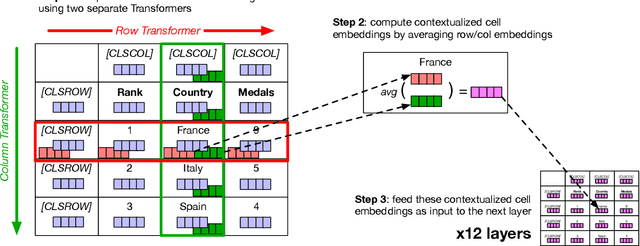
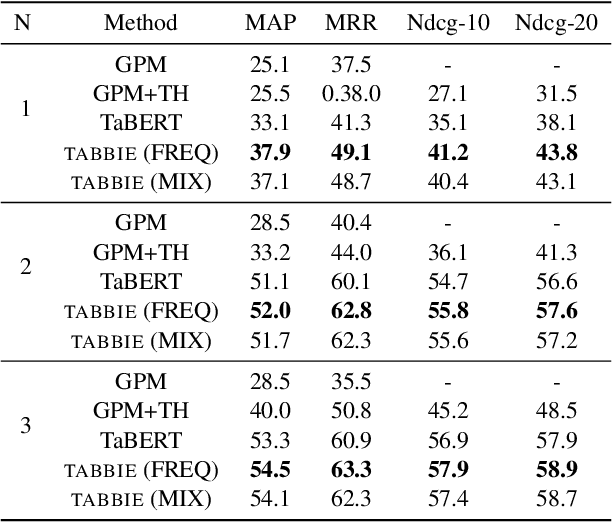
Existing work on tabular representation learning jointly models tables and associated text using self-supervised objective functions derived from pretrained language models such as BERT. While this joint pretraining improves tasks involving paired tables and text (e.g., answering questions about tables), we show that it underperforms on tasks that operate over tables without any associated text (e.g., populating missing cells). We devise a simple pretraining objective (corrupt cell detection) that learns exclusively from tabular data and reaches the state-of-the-art on a suite of table based prediction tasks. Unlike competing approaches, our model (TABBIE) provides embeddings of all table substructures (cells, rows, and columns), and it also requires far less compute to train. A qualitative analysis of our model's learned cell, column, and row representations shows that it understands complex table semantics and numerical trends.
Case-based Reasoning for Natural Language Queries over Knowledge Bases
Apr 18, 2021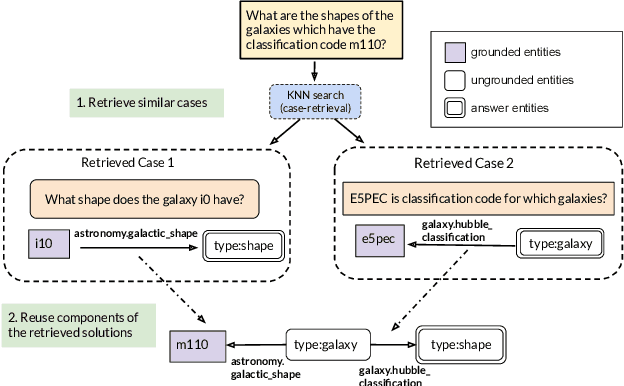
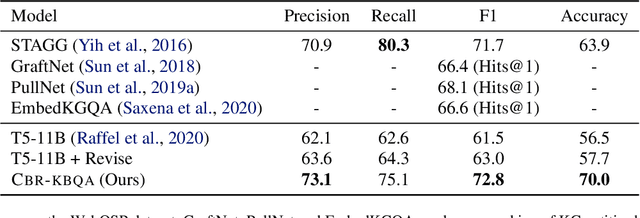
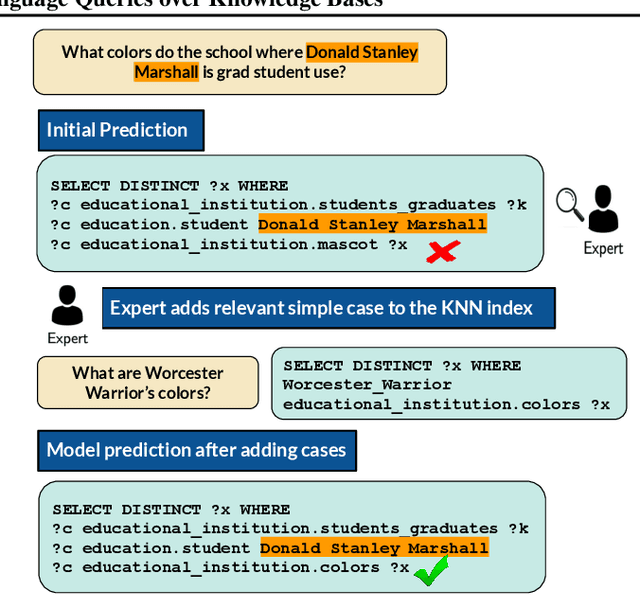
It is often challenging for a system to solve a new complex problem from scratch, but much easier if the system can access other similar problems and description of their solutions -- a paradigm known as case-based reasoning (CBR). We propose a neuro-symbolic CBR approach for question answering over large knowledge bases (CBR-KBQA). While the idea of CBR is tempting, composing a solution from cases is nontrivial, when individual cases only contain partial logic to the full solution. To resolve this, CBR-KBQA consists of two modules: a non-parametric memory that stores cases (question and logical forms) and a parametric model which can generate logical forms by retrieving relevant cases from memory. Through experiments, we show that CBR-KBQA can effectively derive novel combination of relations not presented in case memory that is required to answer compositional questions. On several KBQA datasets that test compositional generalization, CBR-KBQA achieves competitive performance. For example, on the challenging ComplexWebQuestions dataset, CBR-KBQA outperforms the current state of the art by 11% accuracy. Furthermore, we show that CBR-KBQA is capable of using new cases \emph{without} any further training. Just by incorporating few human-labeled examples in the non-parametric case memory, CBR-KBQA is able to successfully generate queries containing unseen KB relations.
Embedded-State Latent Conditional Random Fields for Sequence Labeling
Sep 28, 2018
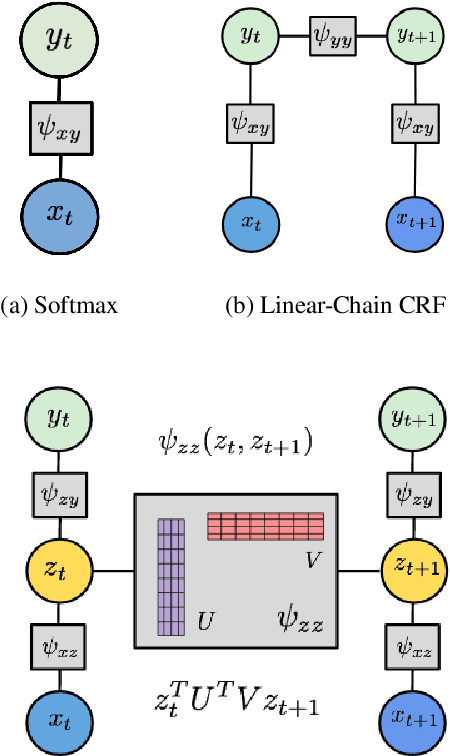
Complex textual information extraction tasks are often posed as sequence labeling or \emph{shallow parsing}, where fields are extracted using local labels made consistent through probabilistic inference in a graphical model with constrained transitions. Recently, it has become common to locally parametrize these models using rich features extracted by recurrent neural networks (such as LSTM), while enforcing consistent outputs through a simple linear-chain model, representing Markovian dependencies between successive labels. However, the simple graphical model structure belies the often complex non-local constraints between output labels. For example, many fields, such as a first name, can only occur a fixed number of times, or in the presence of other fields. While RNNs have provided increasingly powerful context-aware local features for sequence tagging, they have yet to be integrated with a global graphical model of similar expressivity in the output distribution. Our model goes beyond the linear chain CRF to incorporate multiple hidden states per output label, but parametrizes their transitions parsimoniously with low-rank log-potential scoring matrices, effectively learning an embedding space for hidden states. This augmented latent space of inference variables complements the rich feature representation of the RNN, and allows exact global inference obeying complex, learned non-local output constraints. We experiment with several datasets and show that the model outperforms baseline CRF+RNN models when global output constraints are necessary at inference-time, and explore the interpretable latent structure.
Low-Rank Hidden State Embeddings for Viterbi Sequence Labeling
Aug 02, 2017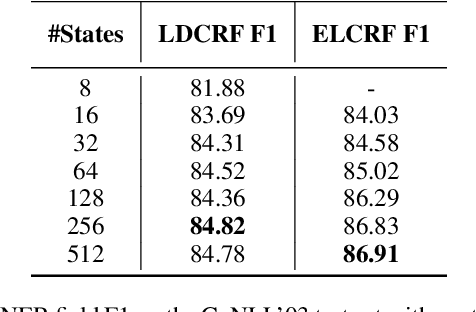

In textual information extraction and other sequence labeling tasks it is now common to use recurrent neural networks (such as LSTM) to form rich embedded representations of long-term input co-occurrence patterns. Representation of output co-occurrence patterns is typically limited to a hand-designed graphical model, such as a linear-chain CRF representing short-term Markov dependencies among successive labels. This paper presents a method that learns embedded representations of latent output structure in sequence data. Our model takes the form of a finite-state machine with a large number of latent states per label (a latent variable CRF), where the state-transition matrix is factorized---effectively forming an embedded representation of state-transitions capable of enforcing long-term label dependencies, while supporting exact Viterbi inference over output labels. We demonstrate accuracy improvements and interpretable latent structure in a synthetic but complex task based on CoNLL named entity recognition.