 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABBIE: Pretrained Representations of Tabular Data
Paper and Code
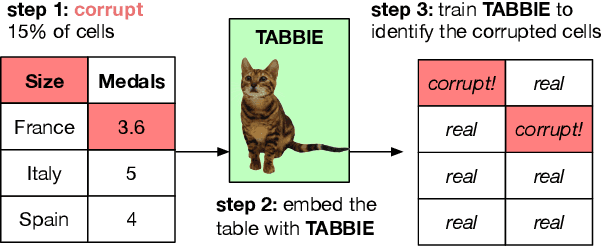
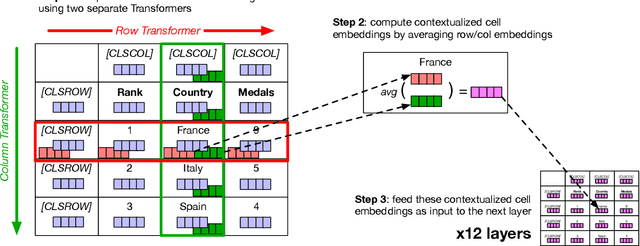
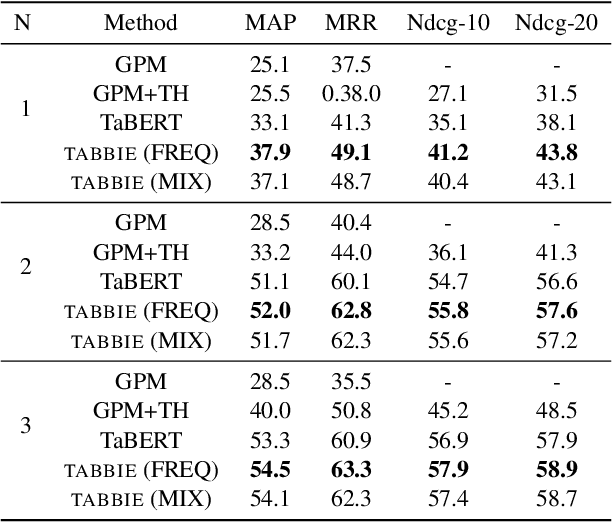
Existing work on tabular representation learning jointly models tables and associated text using self-supervised objective functions derived from pretrained language models such as BERT. While this joint pretraining improves tasks involving paired tables and text (e.g., answering questions about tables), we show that it underperforms on tasks that operate over tables without any associated text (e.g., populating missing cells). We devise a simple pretraining objective (corrupt cell detection) that learns exclusively from tabular data and reaches the state-of-the-art on a suite of table based prediction tasks. Unlike competing approaches, our model (TABBIE) provides embeddings of all table substructures (cells, rows, and columns), and it also requires far less compute to train. A qualitative analysis of our model's learned cell, column, and row representations shows that it understands complex table semantics and numerical trends.