 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded-State Latent Conditional Random Fields for Sequence Labeling
Sep 28, 2018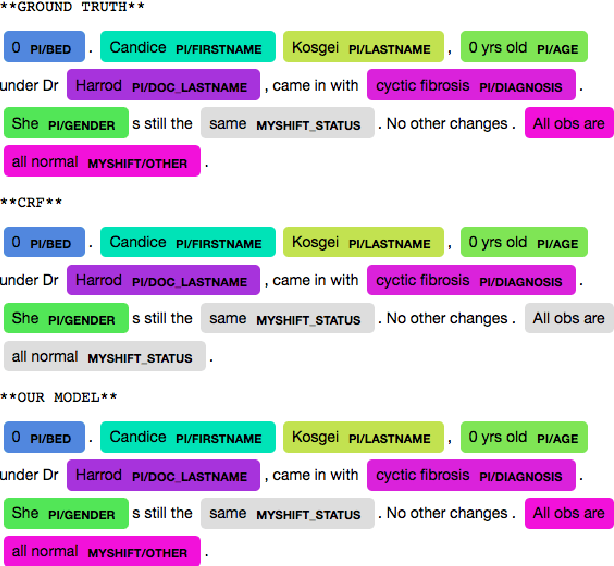
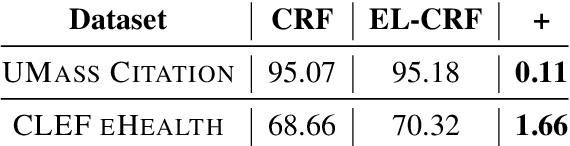
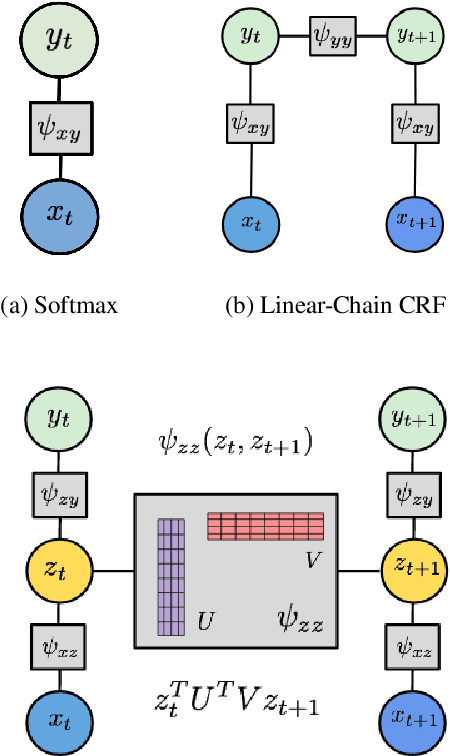
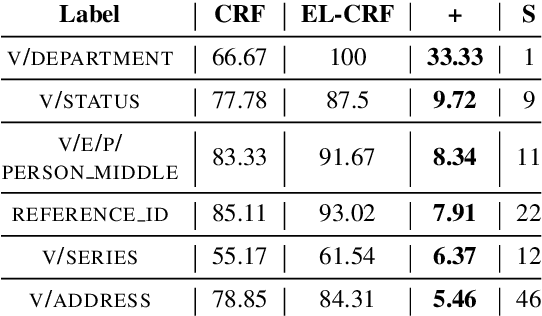
Complex textual information extraction tasks are often posed as sequence labeling or \emph{shallow parsing}, where fields are extracted using local labels made consistent through probabilistic inference in a graphical model with constrained transitions. Recently, it has become common to locally parametrize these models using rich features extracted by recurrent neural networks (such as LSTM), while enforcing consistent outputs through a simple linear-chain model, representing Markovian dependencies between successive labels. However, the simple graphical model structure belies the often complex non-local constraints between output labels. For example, many fields, such as a first name, can only occur a fixed number of times, or in the presence of other fields. While RNNs have provided increasingly powerful context-aware local features for sequence tagging, they have yet to be integrated with a global graphical model of similar expressivity in the output distribution. Our model goes beyond the linear chain CRF to incorporate multiple hidden states per output label, but parametrizes their transitions parsimoniously with low-rank log-potential scoring matrices, effectively learning an embedding space for hidden states. This augmented latent space of inference variables complements the rich feature representation of the RNN, and allows exact global inference obeying complex, learned non-local output constraints. We experiment with several datasets and show that the model outperforms baseline CRF+RNN models when global output constraints are necessary at inference-time, and explore the interpretable latent structure.
Neural Machine Translation for Low Resource Languages using Bilingual Lexicon Induced from Comparable Corpora
Jun 25, 2018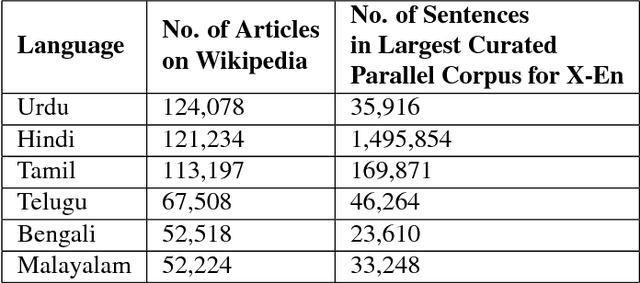
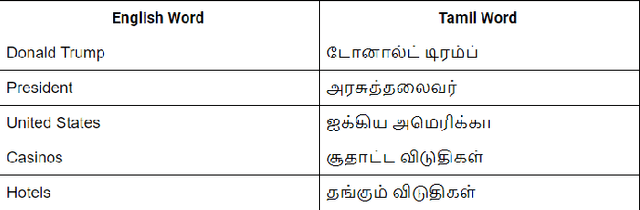
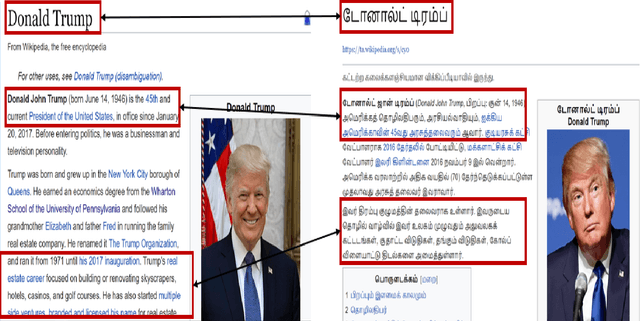
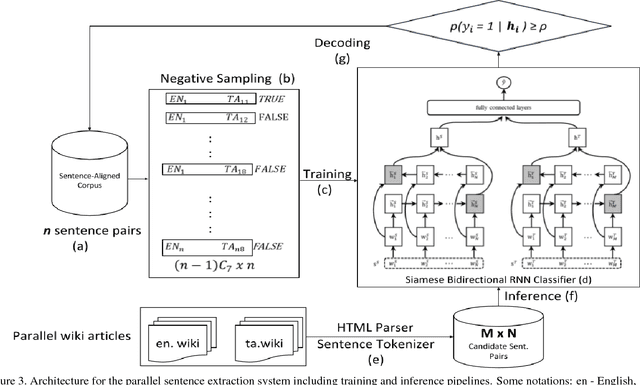
Resources for the non-English languages are scarce and this paper addresses this problem in the context of machine translation, by automatically extracting parallel sentence pairs from the multilingual articles available on the Internet. In this paper, we have used an end-to-end Siamese bidirectional recurrent neural network to generate parallel sentences from comparable multilingual articles in Wikipedia. Subsequently, we have showed that using the harvested dataset improved BLEU scores on both NMT and phrase-based SMT systems for the low-resource language pairs: English--Hindi and English--Tamil, when compared to training exclusively on the limited bilingual corpora collected for these language pairs.
A POS Tagger for Code Mixed Indian Social Media Text - ICON-2016 NLP Tools Contest Entry from Surukam
Dec 31, 2016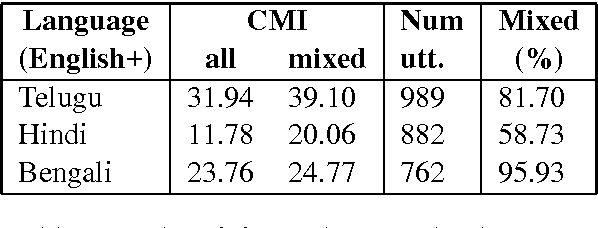
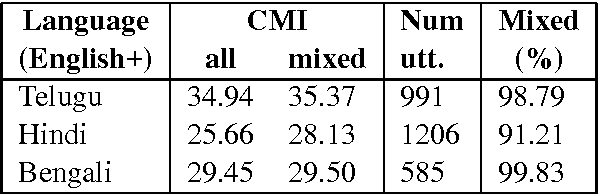
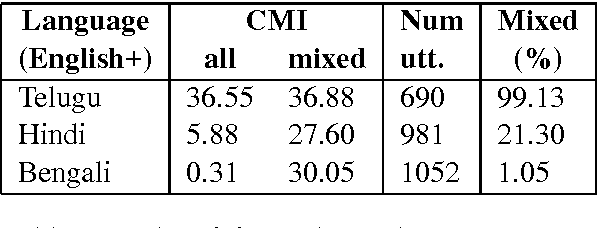
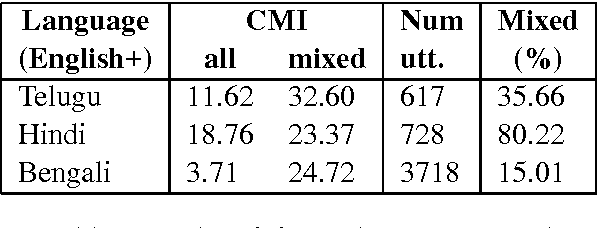
Building Part-of-Speech (POS) taggers for code-mixed Indian languages is a particularly challenging problem in computational linguistics due to a dearth of accurately annotated training corpora. ICON, as part of its NLP tools contest has organized this challenge as a shared task for the second consecutive year to improve the state-of-the-art. This paper describes the POS tagger built at Surukam to predict the coarse-grained and fine-grained POS tags for three language pairs - Bengali-English, Telugu-English and Hindi-English, with the text spanning three popular social media platforms - Facebook, WhatsApp and Twitter. We employed Conditional Random Fields as the sequence tagging algorithm and used a library called sklearn-crfsuite - a thin wrapper around CRFsuite for training our model. Among the features we used include - character n-grams, language information and patterns for emoji, number, punctuation and web-address. Our submissions in the constrained environment,i.e., without making any use of monolingual POS taggers or the like, obtained an overall average F1-score of 76.45%, which is comparable to the 2015 winning score of 76.79%.