 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCase-based Reasoning for Natural Language Queries over Knowledge Bases
Apr 18, 2021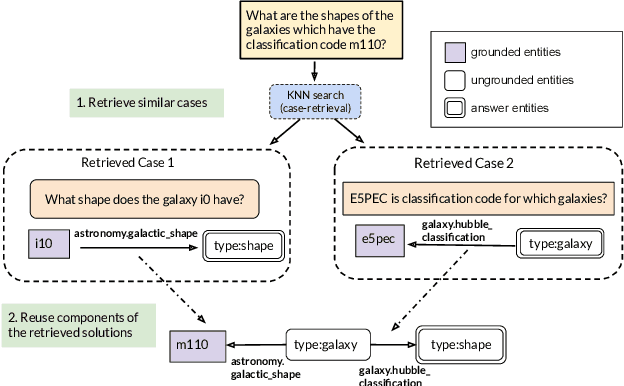
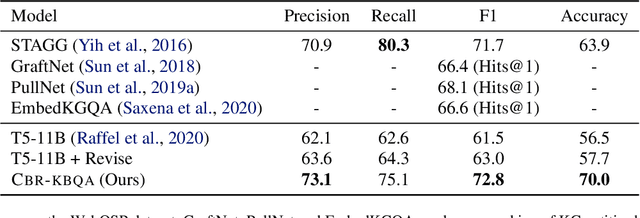
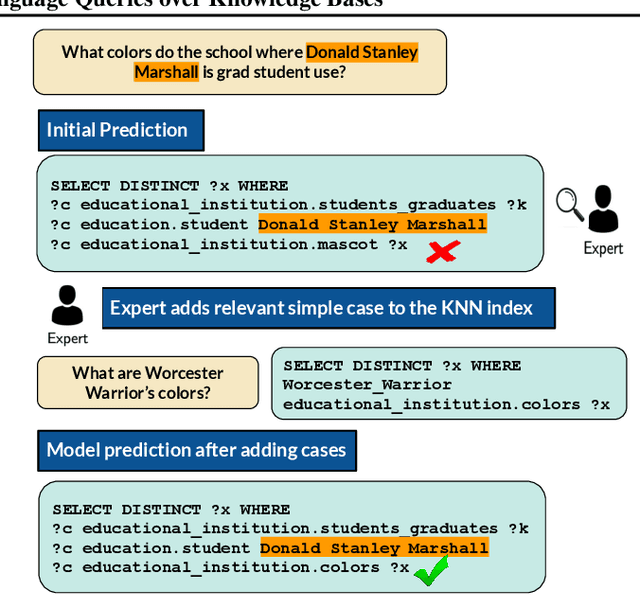
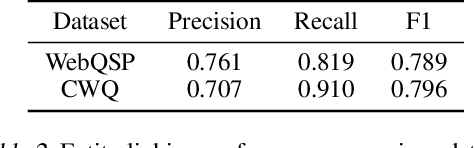
It is often challenging for a system to solve a new complex problem from scratch, but much easier if the system can access other similar problems and description of their solutions -- a paradigm known as case-based reasoning (CBR). We propose a neuro-symbolic CBR approach for question answering over large knowledge bases (CBR-KBQA). While the idea of CBR is tempting, composing a solution from cases is nontrivial, when individual cases only contain partial logic to the full solution. To resolve this, CBR-KBQA consists of two modules: a non-parametric memory that stores cases (question and logical forms) and a parametric model which can generate logical forms by retrieving relevant cases from memory. Through experiments, we show that CBR-KBQA can effectively derive novel combination of relations not presented in case memory that is required to answer compositional questions. On several KBQA datasets that test compositional generalization, CBR-KBQA achieves competitive performance. For example, on the challenging ComplexWebQuestions dataset, CBR-KBQA outperforms the current state of the art by 11% accuracy. Furthermore, we show that CBR-KBQA is capable of using new cases \emph{without} any further training. Just by incorporating few human-labeled examples in the non-parametric case memory, CBR-KBQA is able to successfully generate queries containing unseen KB relations.
Joint Turn and Dialogue level User Satisfaction Estimation on Multi-Domain Conversations
Oct 08, 2020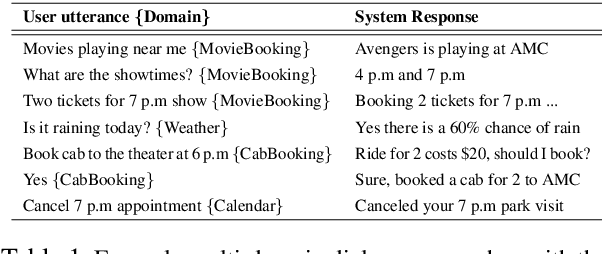
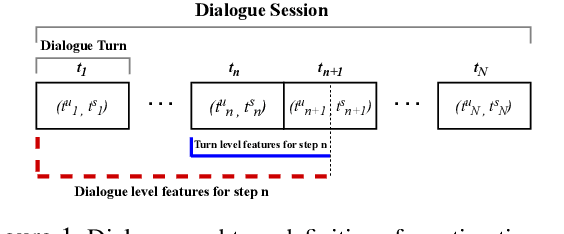
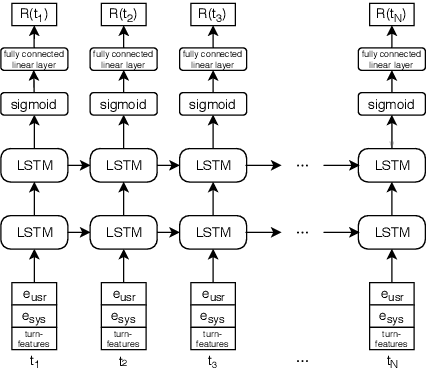
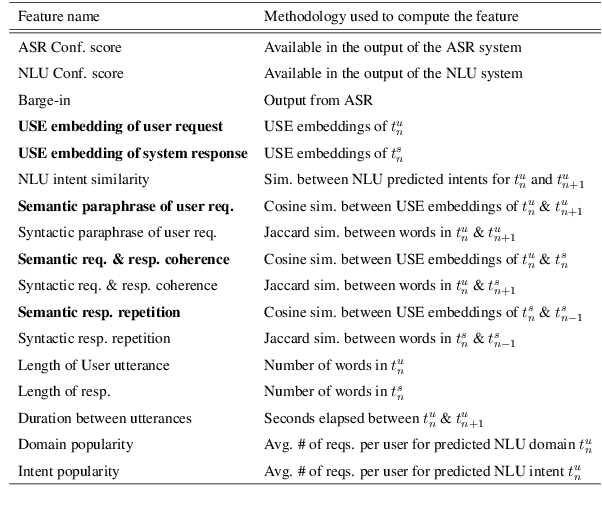
Dialogue level quality estimation is vital for optimizing data driven dialogue management. Current automated methods to estimate turn and dialogue level user satisfaction employ hand-crafted features and rely on complex annotation schemes, which reduce the generalizability of the trained models. We propose a novel user satisfaction estimation approach which minimizes an adaptive multi-task loss function in order to jointly predict turn-level Response Quality labels provided by experts and explicit dialogue-level ratings provided by end users. The proposed BiLSTM based deep neural net model automatically weighs each turn's contribution towards the estimated dialogue-level rating, implicitly encodes temporal dependencies, and removes the need to hand-craft features. On dialogues sampled from 28 Alexa domains, two dialogue systems and three user groups, the joint dialogue-level satisfaction estimation model achieved up to an absolute 27% (0.43->0.70) and 7% (0.63->0.70) improvement in linear correlation performance over baseline deep neural net and benchmark Gradient boosting regression models, respectively.
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
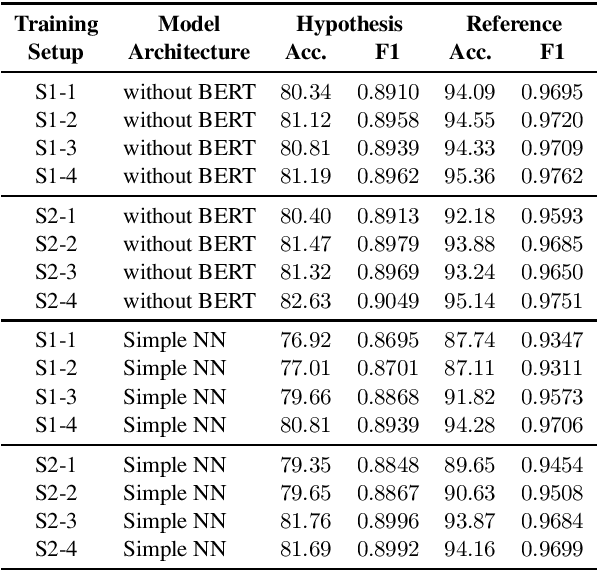
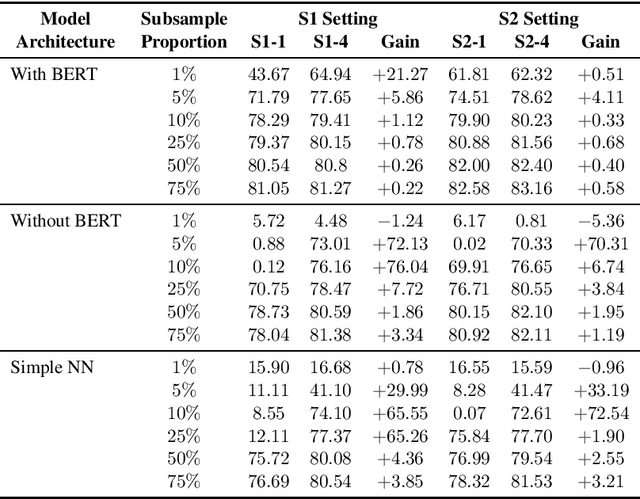
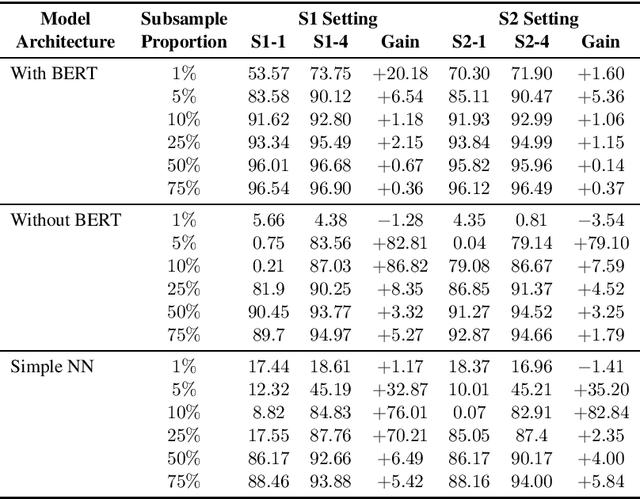
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
Multi-domain Conversation Quality Evaluation via User Satisfaction Estimation
Nov 18, 2019
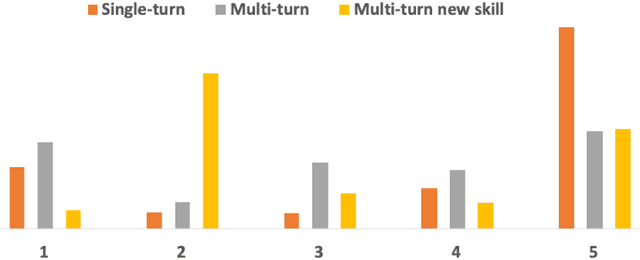
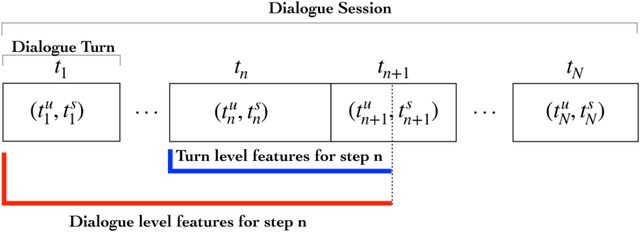
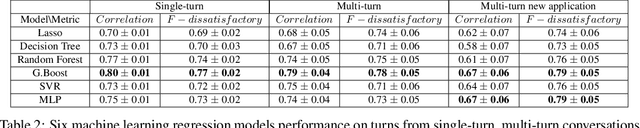
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and employ annotation schemes with limited generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, introduced five new domain-independent feature sets and experimented with six machine learning models to estimate User Satisfaction at both turn and dialogue level. Response Quality ratings achieved significantly high correlation (0.76) with explicit turn-level user ratings. Using the new feature sets we introduced, Gradient Boosting Regression model achieved best (rating [1-5]) prediction performance on 26 seen (linear correlation ~0.79) and one new multi-turn domain (linear correlation 0.67). We observed a 16% relative improvement (68% -> 79%) in binary ("satisfactory/dissatisfactory") class prediction accuracy of a domain-independent dialogue-level satisfaction estimation model after including predicted turn-level satisfaction ratings as features.
Learning End-to-End Goal-Oriented Dialog with Maximal User Task Success and Minimal Human Agent Use
Jul 17, 2019Neural end-to-end goal-oriented dialog systems showed promise to reduce the workload of human agents for customer service, as well as reduce wait time for users. However, their inability to handle new user behavior at deployment has limited their usage in real world. In this work, we propose an end-to-end trainable method for neural goal-oriented dialog systems which handles new user behaviors at deployment by transferring the dialog to a human agent intelligently. The proposed method has three goals: 1) maximize user's task success by transferring to human agents, 2) minimize the load on the human agents by transferring to them only when it is essential and 3) learn online from the human agent's responses to reduce human agents load further. We evaluate our proposed method on a modified-bAbI dialog task that simulates the scenario of new user behaviors occurring at test time. Experimental results show that our proposed method is effective in achieving the desired goals.
* Author final version of article accepted for publication in TACL - https://www.mitpressjournals.org/doi/full/10.1162/tacl_a_00274 and oral presentation at ACL 2019
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model
Oct 25, 2018
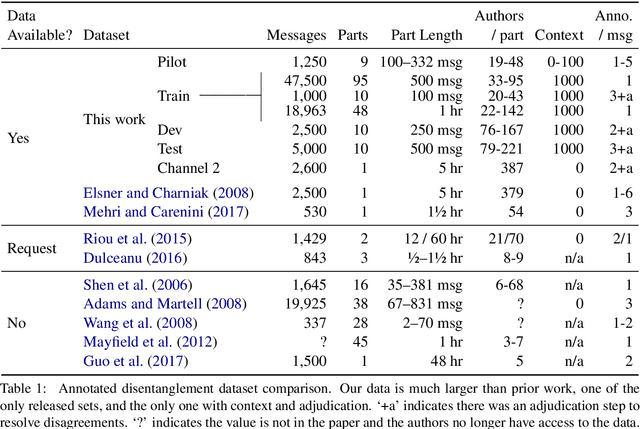

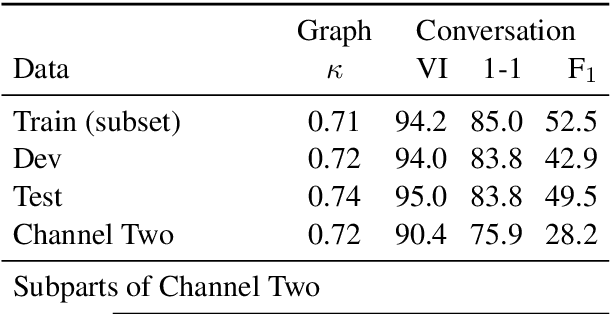
Disentangling conversations mixed together in a single stream of messages is a difficult task with no large annotated datasets. We created a new dataset that is 25 times the size of any previous publicly available resource, has samples of conversation from 152 points in time across a decade, and is annotated with both threads and a within-thread reply-structure graph. We also developed a new neural network model, which extracts conversation threads substantially more accurately than prior work. Using our annotated data and our model we tested assumptions in prior work, revealing major issues in heuristically constructed resources, and identifying how small datasets have biased our understanding of multi-party multi-conversation chat.
Learning End-to-End Goal-Oriented Dialog with Multiple Answers
Aug 24, 2018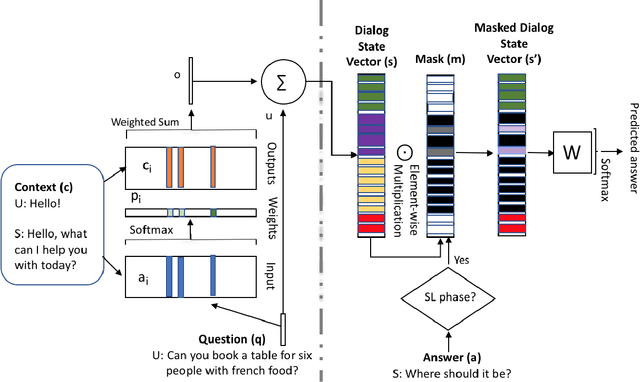
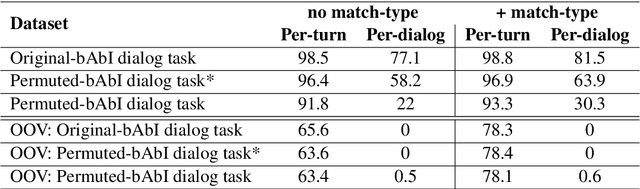
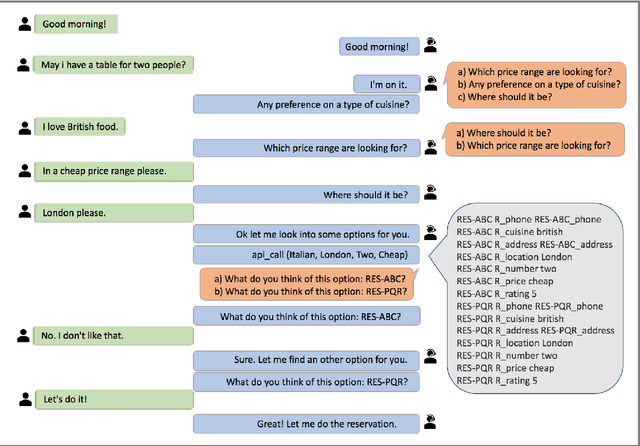
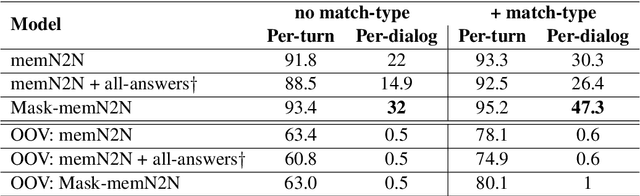
In a dialog, there can be multiple valid next utterances at any point. The present end-to-end neural methods for dialog do not take this into account. They learn with the assumption that at any time there is only one correct next utterance. In this work, we focus on this problem in the goal-oriented dialog setting where there are different paths to reach a goal. We propose a new method, that uses a combination of supervised learning and reinforcement learning approaches to address this issue. We also propose a new and more effective testbed, permuted-bAbI dialog tasks, by introducing multiple valid next utterances to the original-bAbI dialog tasks, which allows evaluation of goal-oriented dialog systems in a more realistic setting. We show that there is a significant drop in performance of existing end-to-end neural methods from 81.5% per-dialog accuracy on original-bAbI dialog tasks to 30.3% on permuted-bAbI dialog tasks. We also show that our proposed method improves the performance and achieves 47.3% per-dialog accuracy on permuted-bAbI dialog tasks.
Knowledge-based end-to-end memory networks
Apr 23, 2018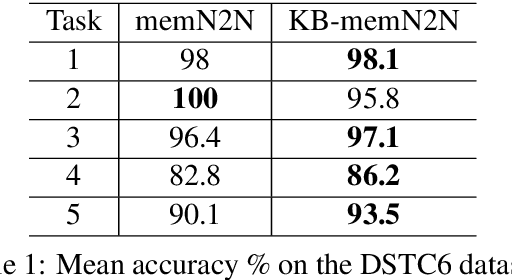
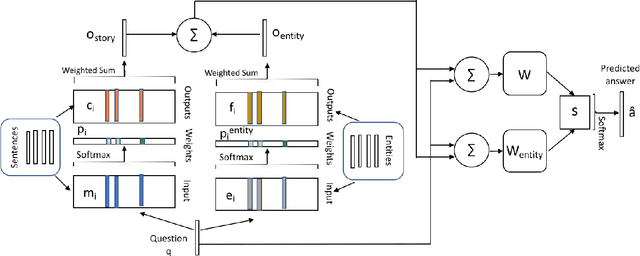
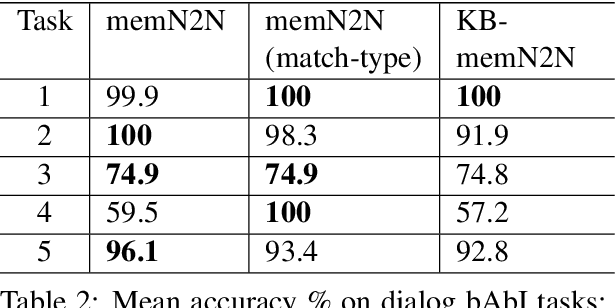
End-to-end dialog systems have become very popular because they hold the promise of learning directly from human to human dialog interaction. Retrieval and Generative methods have been explored in this area with mixed results. A key element that is missing so far, is the incorporation of a-priori knowledge about the task at hand. This knowledge may exist in the form of structured or unstructured information. As a first step towards this direction, we present a novel approach, Knowledge based end-to-end memory networks (KB-memN2N), which allows special handling of named entities for goal-oriented dialog tasks. We present results on two datasets, DSTC6 challenge dataset and dialog bAbI tasks.
Addressee and Response Selection in Multi-Party Conversations with Speaker Interaction RNNs
Nov 28, 2017
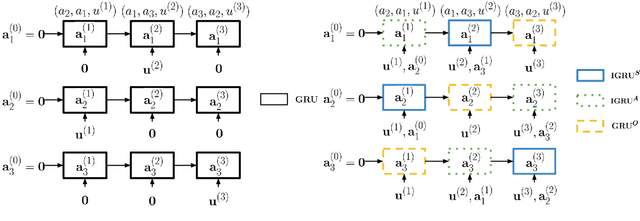
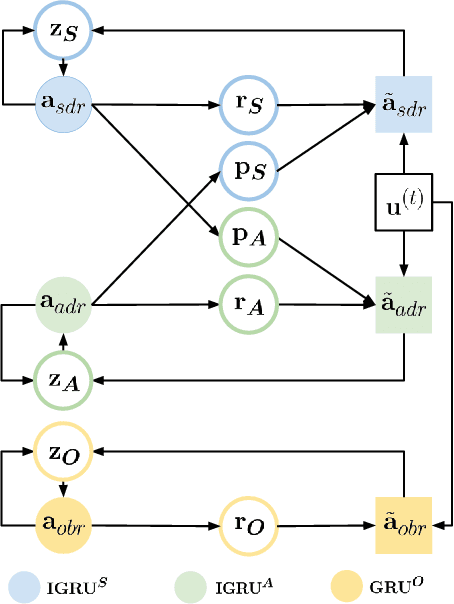
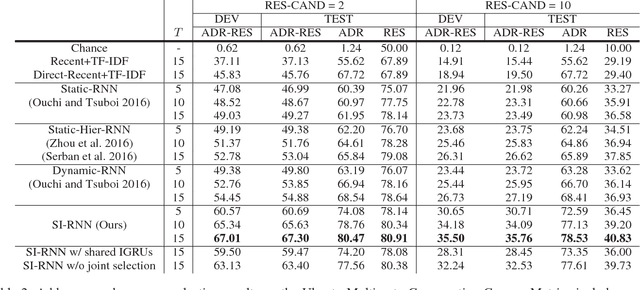
In this paper, we study the problem of addressee and response selection in multi-party conversations. Understanding multi-party conversations is challenging because of complex speaker interactions: multiple speakers exchange messages with each other, playing different roles (sender, addressee, observer), and these roles vary across turns. To tackle this challenge, we propose the Speaker Interaction Recurrent Neural Network (SI-RNN). Whereas the previous state-of-the-art system updated speaker embeddings only for the sender, SI-RNN uses a novel dialog encoder to update speaker embeddings in a role-sensitive way. Additionally, unlike the previous work that selected the addressee and response separately, SI-RNN selects them jointly by viewing the task as a sequence prediction problem. Experimental results show that SI-RNN significantly improves the accuracy of addressee and response selection, particularly in complex conversations with many speakers and responses to distant messages many turns in the past.