 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Nonparametric Distribution Forecast with Backtest-based Bootstrap and Adaptive Residual Selection
Feb 16, 2022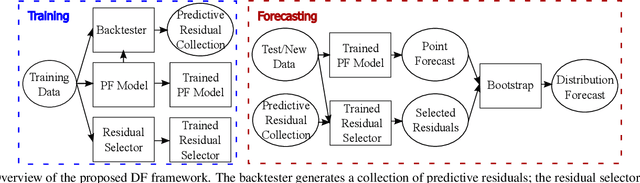
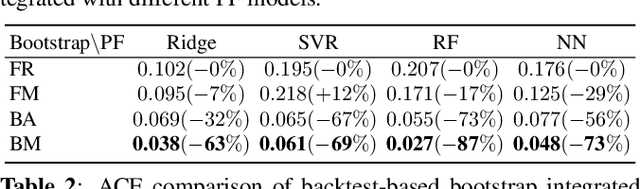
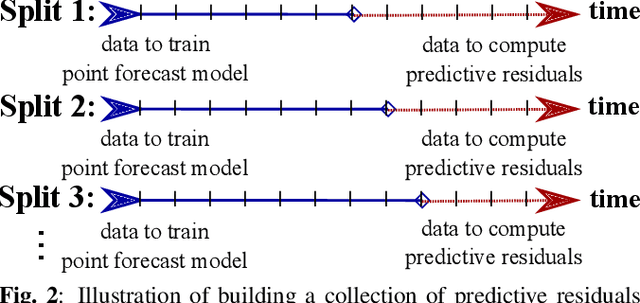

Distribution forecast can quantify forecast uncertainty and provide various forecast scenarios with their corresponding estimated probabilities. Accurate distribution forecast is crucial for planning - for example when making production capacity or inventory allocation decisions. We propose a practical and robust distribution forecast framework that relies on backtest-based bootstrap and adaptive residual selection. The proposed approach is robust to the choice of the underlying forecasting model, accounts for uncertainty around the input covariates, and relaxes the independence between residuals and covariates assumption. It reduces the Absolute Coverage Error by more than 63% compared to the classic bootstrap approaches and by 2% - 32% compared to a variety of State-of-the-Art deep learning approaches on in-house product sales data and M4-hourly competition data.
Are Neural Open-Domain Dialog Systems Robust to Speech Recognition Errors in the Dialog History? An Empirical Study
Aug 18, 2020
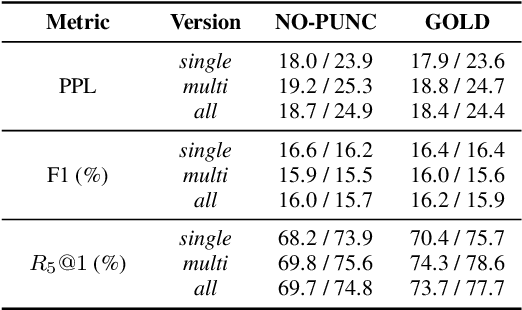

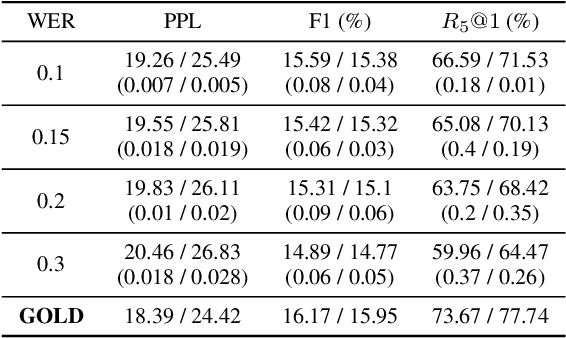
Large end-to-end neural open-domain chatbots are becoming increasingly popular. However, research on building such chatbots has typically assumed that the user input is written in nature and it is not clear whether these chatbots would seamlessly integrate with automatic speech recognition (ASR) models to serve the speech modality. We aim to bring attention to this important question by empirically studying the effects of various types of synthetic and actual ASR hypotheses in the dialog history on TransferTransfo, a state-of-the-art Generative Pre-trained Transformer (GPT) based neural open-domain dialog system from the NeurIPS ConvAI2 challenge. We observe that TransferTransfo trained on written data is very sensitive to such hypotheses introduced to the dialog history during inference time. As a baseline mitigation strategy, we introduce synthetic ASR hypotheses to the dialog history during training and observe marginal improvements, demonstrating the need for further research into techniques to make end-to-end open-domain chatbots fully speech-robust. To the best of our knowledge, this is the first study to evaluate the effects of synthetic and actual ASR hypotheses on a state-of-the-art neural open-domain dialog system and we hope it promotes speech-robustness as an evaluation criterion in open-domain dialog.
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
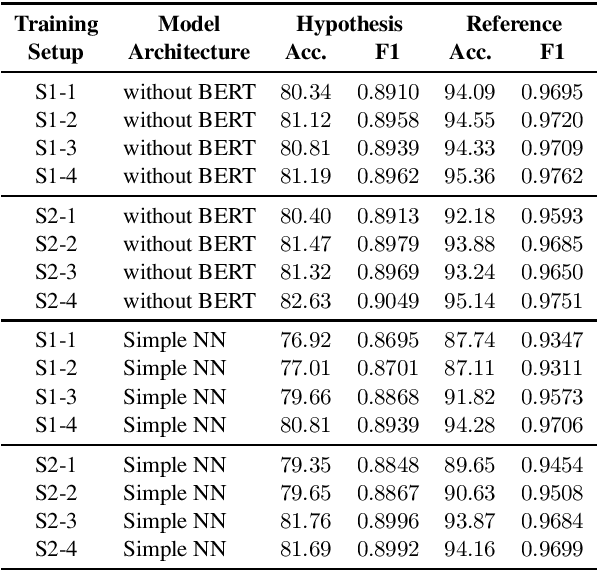
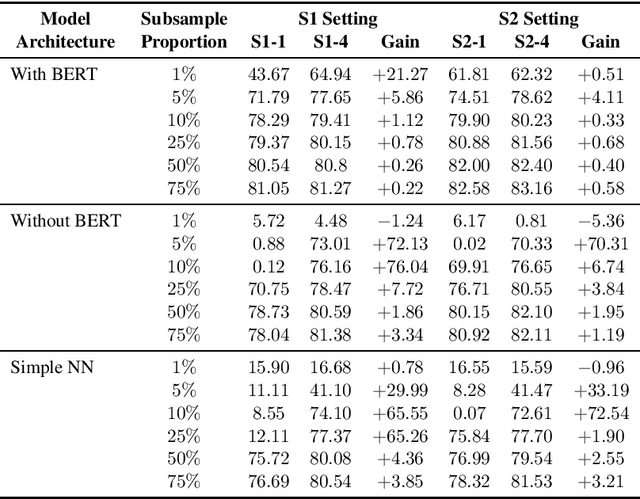
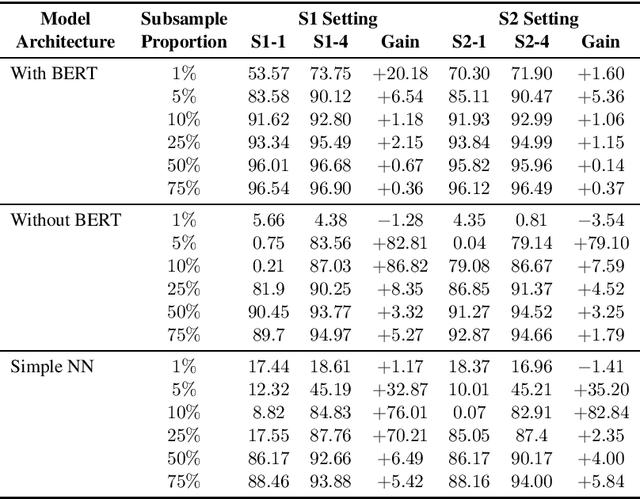
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
High dimensional precision medicine from patient-derived xenografts
Dec 13, 2019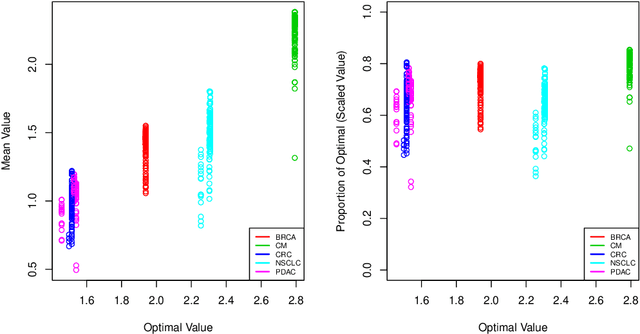

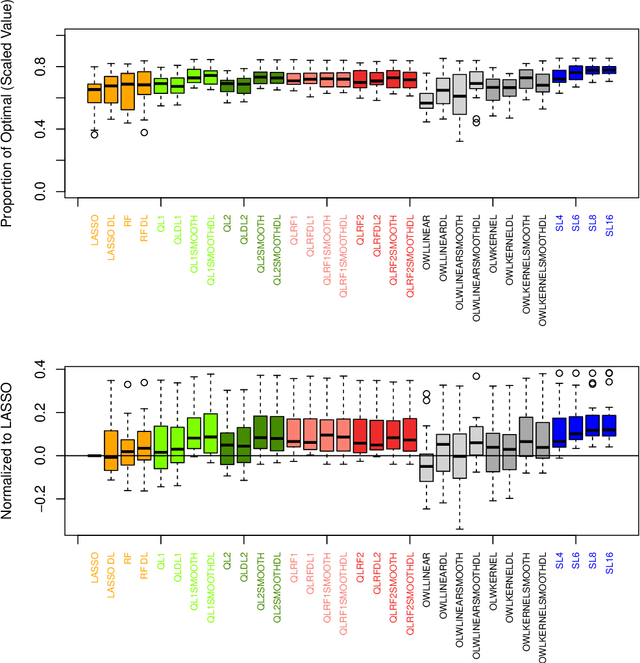
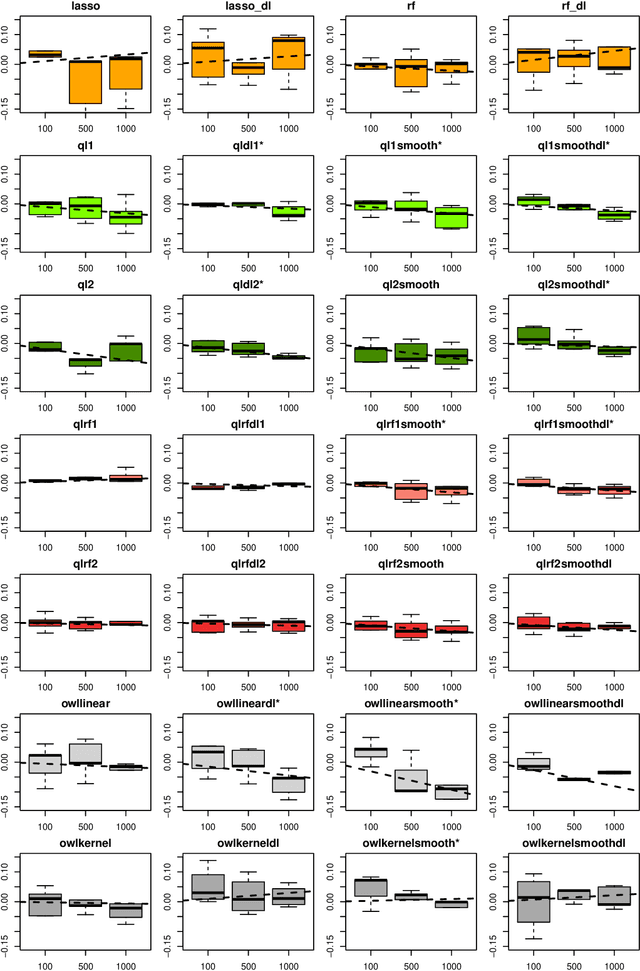
The complexity of human cancer often results in significant heterogeneity in response to treatment. Precision medicine offers potential to improve patient outcomes by leveraging this heterogeneity. Individualized treatment rules (ITRs) formalize precision medicine as maps from the patient covariate space into the space of allowable treatments. The optimal ITR is that which maximizes the mean of a clinical outcome in a population of interest. Patient-derived xenograft (PDX) studies permit the evaluation of multiple treatments within a single tumor and thus are ideally suited for estimating optimal ITRs. PDX data are characterized by correlated outcomes, a high-dimensional feature space, and a large number of treatments. Existing methods for estimating optimal ITRs do not take advantage of the unique structure of PDX data or handle the associated challenges well. In this paper, we explore machine learning methods for estimating optimal ITRs from PDX data. We analyze data from a large PDX study to identify biomarkers that are informative for developing personalized treatment recommendations in multiple cancers. We estimate optimal ITRs using regression-based approaches such as Q-learning and direct search methods such as outcome weighted learning. Finally, we implement a superlearner approach to combine a set of estimated ITRs and show that the resulting ITR performs better than any of the input ITRs, mitigating uncertainty regarding user choice of any particular ITR estimation methodology. Our results indicate that PDX data are a valuable resource for developing individualized treatment strategies in oncology.
Investigation of Error Simulation Techniques for Learning Dialog Policies for Conversational Error Recovery
Nov 08, 2019

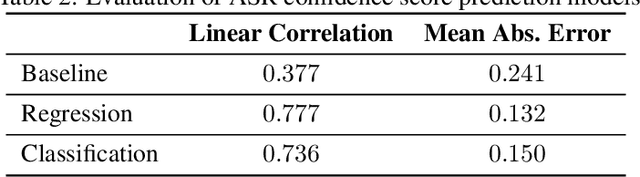
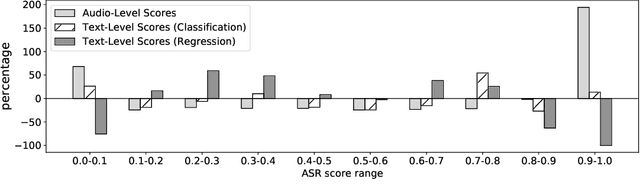
Training dialog policies for speech-based virtual assistants requires a plethora of conversational data. The data collection phase is often expensive and time consuming due to human involvement. To address this issue, a common solution is to build user simulators for data generation. For the successful deployment of the trained policies into real world domains, it is vital that the user simulator mimics realistic conditions. In particular, speech-based assistants are heavily affected by automatic speech recognition and language understanding errors, hence the user simulator should be able to simulate similar errors. In this paper, we review the existing error simulation methods that induce errors at audio, phoneme, text, or semantic level; and conduct detailed comparisons between the audio-level and text-level methods. In the process, we improve the existing text-level method by introducing confidence score prediction and out-of-vocabulary word mapping. We also explore the impact of audio-level and text-level methods on learning a simple clarification dialog policy to recover from errors to provide insight on future improvement for both approaches.
Domain-Independent turn-level Dialogue Quality Evaluation via User Satisfaction Estimation
Aug 19, 2019
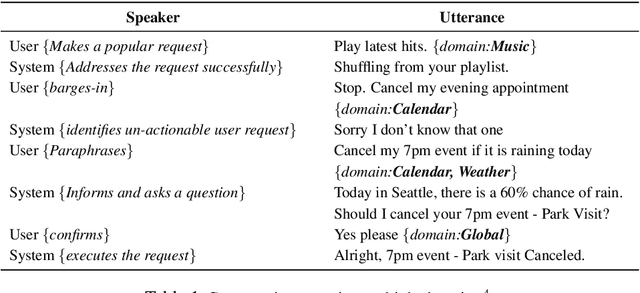
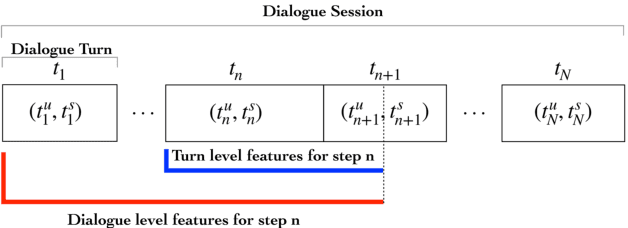
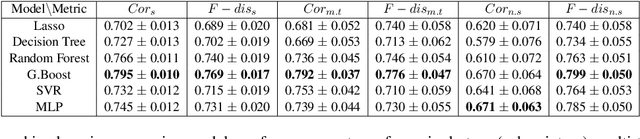
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and rely on annotation schemes with low inter-rater reliability, limiting generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, based on which we developed turn-level User Satisfaction metric. We introduced five new domain-independent feature sets and experimented with six machine learning models to estimate the new satisfaction metric. Using Response Quality annotation scheme, across randomly sampled single and multi-turn conversations from 26 domains, we achieved high inter-annotator agreement (Spearman's rho 0.94). The Response Quality labels were highly correlated (0.76) with explicit turn-level user ratings. Gradient boosting regression achieved best correlation of ~0.79 between predicted and annotated user satisfaction labels. Multi Layer Perceptron and Gradient Boosting regression models generalized to an unseen domain better (linear correlation 0.67) than other models. Finally, our ablation study verified that our novel features significantly improved model performance.
Sex Trafficking Detection with Ordinal Regression Neural Networks
Aug 15, 2019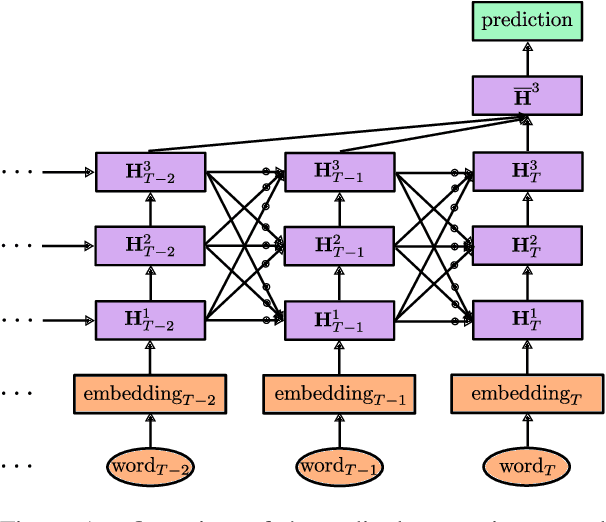

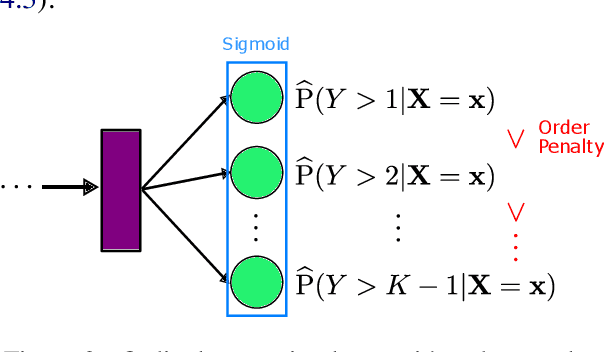
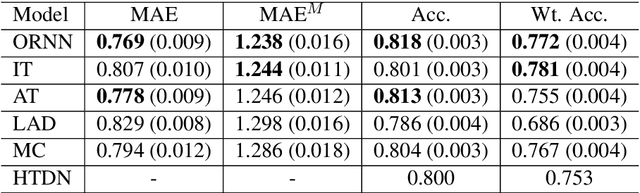
Sex trafficking is a global epidemic. Escort websites are a primary vehicle for selling the services of such trafficking victims and thus a major driver of trafficker revenue. Many law enforcement agencies do not have the resources to manually identify leads from the millions of escort ads posted across dozens of public websites. We propose an ordinal regression neural network to identify escort ads that are likely linked to sex trafficking. Our model uses a modified cost function to mitigate inconsistencies in predictions often associated with nonparametric ordinal regression and leverages recent advancements in deep learning to improve prediction accuracy. The proposed method significantly improves on the previous state-of-the-art on Trafficking-10K, an expert-annotated dataset of escort ads. Additionally, because traffickers use acronyms, deliberate typographical errors, and emojis to replace explicit keywords, we demonstrate how to expand the lexicon of trafficking flags through word embeddings and t-SNE.
Sufficient Markov Decision Processes with Alternating Deep Neural Networks
Mar 17, 2018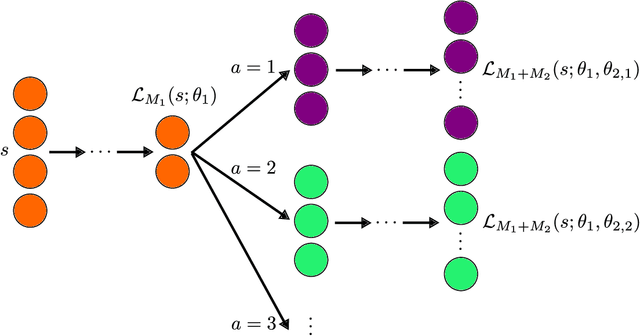
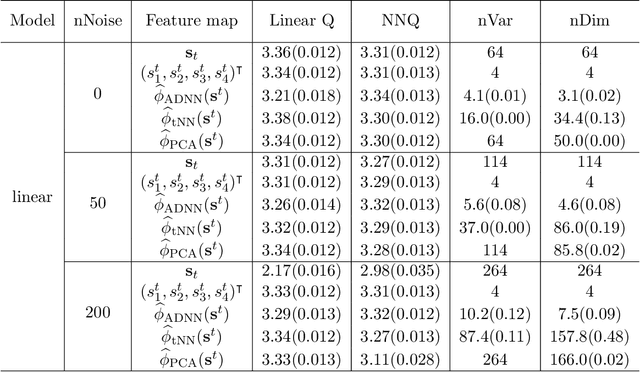
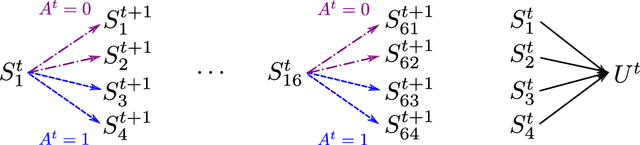
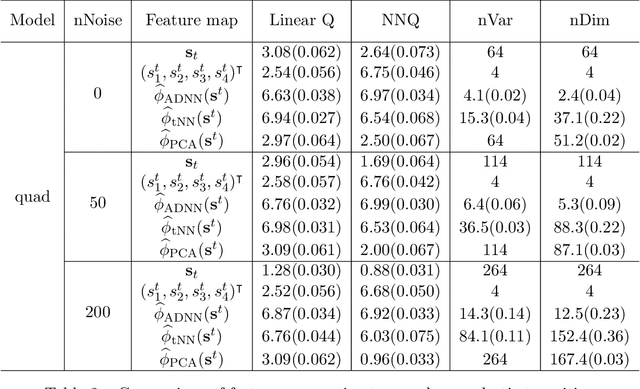
Advances in mobile computing technologies have made it possible to monitor and apply data-driven interventions across complex systems in real time. Markov decision processes (MDPs) are the primary model for sequential decision problems with a large or indefinite time horizon. Choosing a representation of the underlying decision process that is both Markov and low-dimensional is non-trivial. We propose a method for constructing a low-dimensional representation of the original decision process for which: 1. the MDP model holds; 2. a decision strategy that maximizes mean utility when applied to the low-dimensional representation also maximizes mean utility when applied to the original process. We use a deep neural network to define a class of potential process representations and estimate the process of lowest dimension within this class. The method is illustrated using data from a mobile study on heavy drinking and smoking among college students.