 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuleForge: Automated Generation and Validation for Web Vulnerability Detection at Scale
Apr 02, 2026Security teams face a challenge: the volume of newly disclosed Common Vulnerabilities and Exposures (CVEs) far exceeds the capacity to manually develop detection mechanisms. In 2025, the National Vulnerability Database published over 48,000 new vulnerabilities, motivating the need for automation. We present RuleForge, an AWS internal system that automatically generates detection rules--JSON-based patterns that identify malicious HTTP requests exploiting specific vulnerabilities--from structured Nuclei templates describing CVE details. Nuclei templates provide standardized, YAML-based vulnerability descriptions that serve as the structured input for our rule generation process. This paper focuses on RuleForge's architecture and operational deployment for CVE-related threat detection, with particular emphasis on our novel LLM-as-a-judge (Large Language Model as judge) confidence validation system and systematic feedback integration mechanism. This validation approach evaluates candidate rules across two dimensions--sensitivity (avoiding false negatives) and specificity (avoiding false positives)--achieving AUROC of 0.75 and reducing false positives by 67% compared to synthetic-test-only validation in production. Our 5x5 generation strategy (five parallel candidates with up to five refinement attempts each) combined with continuous feedback loops enables systematic quality improvement. We also present extensions enabling rule generation from unstructured data sources and demonstrate a proof-of-concept agentic workflow for multi-event-type detection. Our lessons learned highlight critical considerations for applying LLMs to cybersecurity tasks, including overconfidence mitigation and the importance of domain expertise in both prompt design and quality review of generated rules through human-in-the-loop validation.
MINDSTORES: Memory-Informed Neural Decision Synthesis for Task-Oriented Reinforcement in Embodied Systems
Jan 31, 2025



While large language models (LLMs) have shown promising capabilities as zero-shot planners for embodied agents, their inability to learn from experience and build persistent mental models limits their robustness in complex open-world environments like Minecraft. We introduce MINDSTORES, an experience-augmented planning framework that enables embodied agents to build and leverage mental models through natural interaction with their environment. Drawing inspiration from how humans construct and refine cognitive mental models, our approach extends existing zero-shot LLM planning by maintaining a database of past experiences that informs future planning iterations. The key innovation is representing accumulated experiences as natural language embeddings of (state, task, plan, outcome) tuples, which can then be efficiently retrieved and reasoned over by an LLM planner to generate insights and guide plan refinement for novel states and tasks. Through extensive experiments in the MineDojo environment, a simulation environment for agents in Minecraft that provides low-level controls for Minecraft, we find that MINDSTORES learns and applies its knowledge significantly better than existing memory-based LLM planners while maintaining the flexibility and generalization benefits of zero-shot approaches, representing an important step toward more capable embodied AI systems that can learn continuously through natural experience.
Pheromone-based Learning of Optimal Reasoning Paths
Jan 31, 2025Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities through chain-of-thought prompting, yet discovering effective reasoning methods for complex problems remains challenging due to the vast space of possible intermediate steps. We introduce Ant Colony Optimization-guided Tree of Thought (ACO-ToT), a novel algorithm that combines ACO with LLMs to discover optimal reasoning paths for complex problems efficiently. Drawing inspiration from Hebbian learning in neurological systems, our method employs a collection of distinctly fine-tuned LLM "ants" to traverse and lay pheromone trails through a centralized tree of thought, with each ant's movement governed by a weighted combination of existing pheromone trails and its own specialized expertise. The algorithm evaluates complete reasoning paths using a mixture-of-experts-based scoring function, with pheromones reinforcing productive reasoning paths across iterations. Experiments on three challenging reasoning tasks (GSM8K, ARC-Challenge, and MATH) demonstrate that ACO-ToT performs significantly better than existing chain-of-thought optimization approaches, suggesting that incorporating biologically inspired collective search mechanisms into LLM inference can substantially enhance reasoning capabilities.
Deep Geospatial Interpolation Networks
Aug 15, 2021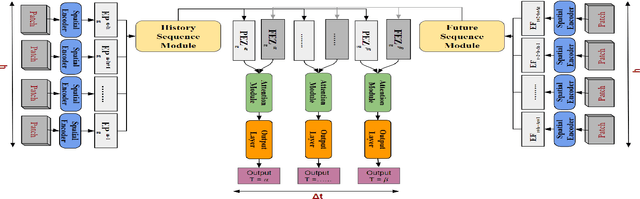
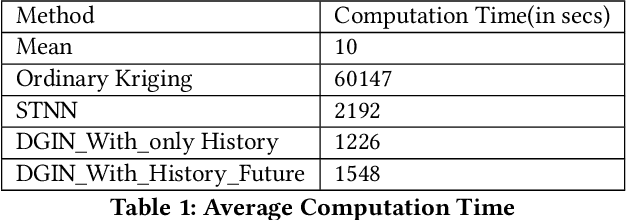
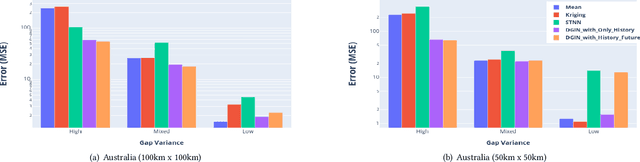
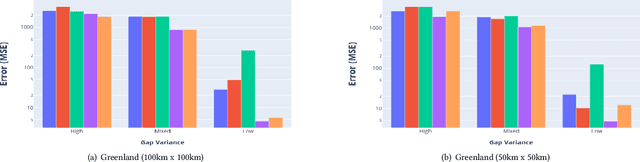
Interpolation in Spatio-temporal data has applications in various domains such as climate, transportation, and mining. Spatio-Temporal interpolation is highly challenging due to the complex spatial and temporal relationships. However, traditional techniques such as Kriging suffer from high running time and poor performance on data that exhibit high variance across space and time dimensions. To this end, we propose a novel deep neural network called as Deep Geospatial Interpolation Network(DGIN), which incorporates both spatial and temporal relationships and has significantly lower training time. DGIN consists of three major components: Spatial Encoder to capture the spatial dependencies, Sequential module to incorporate the temporal dynamics, and an Attention block to learn the importance of the temporal neighborhood around the gap. We evaluate DGIN on the MODIS reflectance dataset from two different regions. Our experimental results indicate that DGIN has two advantages: (a) it outperforms alternative approaches (has lower MSE with p-value < 0.01) and, (b) it has significantly low execution time than Kriging.
Joint Turn and Dialogue level User Satisfaction Estimation on Multi-Domain Conversations
Oct 08, 2020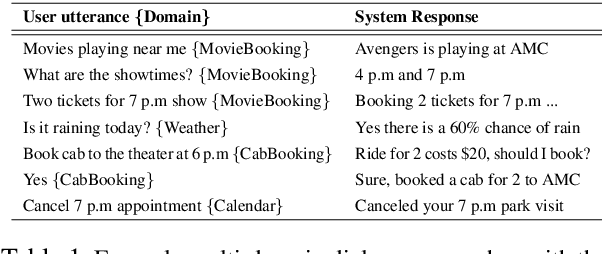
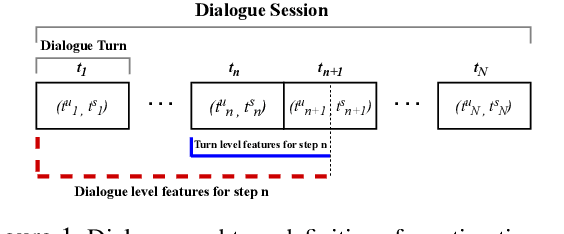
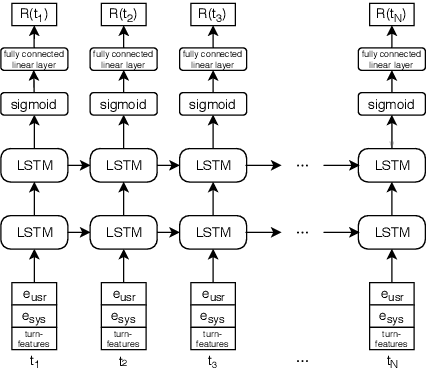
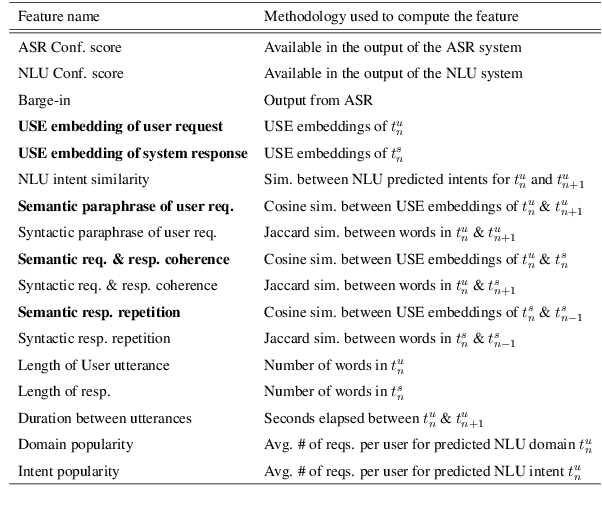
Dialogue level quality estimation is vital for optimizing data driven dialogue management. Current automated methods to estimate turn and dialogue level user satisfaction employ hand-crafted features and rely on complex annotation schemes, which reduce the generalizability of the trained models. We propose a novel user satisfaction estimation approach which minimizes an adaptive multi-task loss function in order to jointly predict turn-level Response Quality labels provided by experts and explicit dialogue-level ratings provided by end users. The proposed BiLSTM based deep neural net model automatically weighs each turn's contribution towards the estimated dialogue-level rating, implicitly encodes temporal dependencies, and removes the need to hand-craft features. On dialogues sampled from 28 Alexa domains, two dialogue systems and three user groups, the joint dialogue-level satisfaction estimation model achieved up to an absolute 27% (0.43->0.70) and 7% (0.63->0.70) improvement in linear correlation performance over baseline deep neural net and benchmark Gradient boosting regression models, respectively.
Data Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Jun 10, 2020
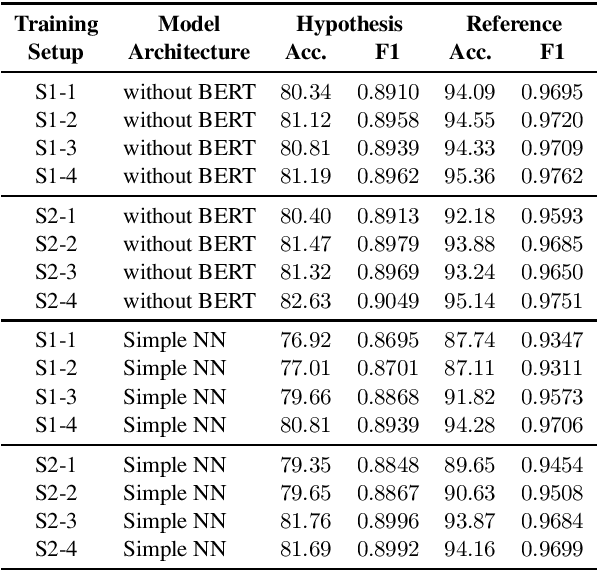
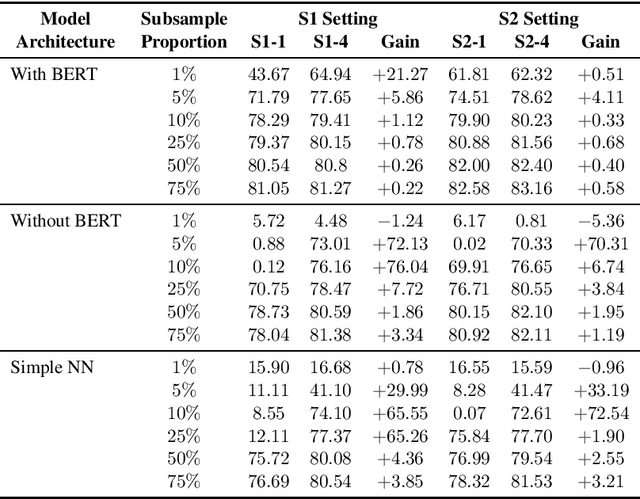
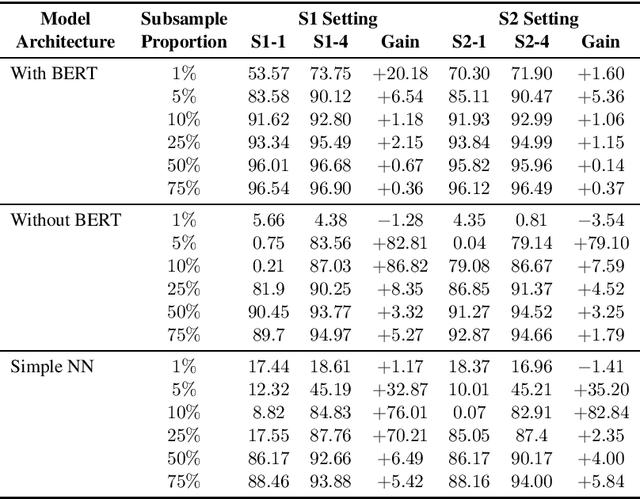
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.
Investigation of Error Simulation Techniques for Learning Dialog Policies for Conversational Error Recovery
Nov 08, 2019

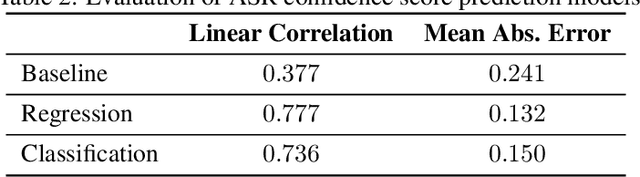
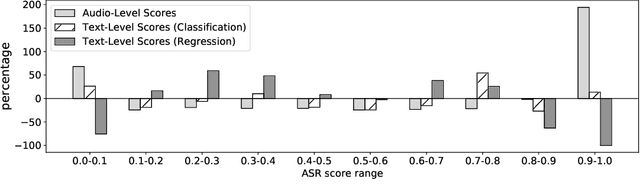
Training dialog policies for speech-based virtual assistants requires a plethora of conversational data. The data collection phase is often expensive and time consuming due to human involvement. To address this issue, a common solution is to build user simulators for data generation. For the successful deployment of the trained policies into real world domains, it is vital that the user simulator mimics realistic conditions. In particular, speech-based assistants are heavily affected by automatic speech recognition and language understanding errors, hence the user simulator should be able to simulate similar errors. In this paper, we review the existing error simulation methods that induce errors at audio, phoneme, text, or semantic level; and conduct detailed comparisons between the audio-level and text-level methods. In the process, we improve the existing text-level method by introducing confidence score prediction and out-of-vocabulary word mapping. We also explore the impact of audio-level and text-level methods on learning a simple clarification dialog policy to recover from errors to provide insight on future improvement for both approaches.