 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Training Dialog Models Robust to Speech Recognition Errors
Paper and Code
Jun 10, 2020
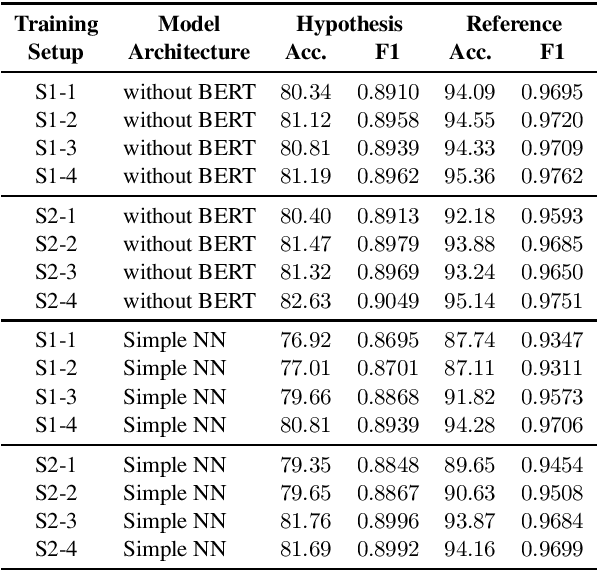
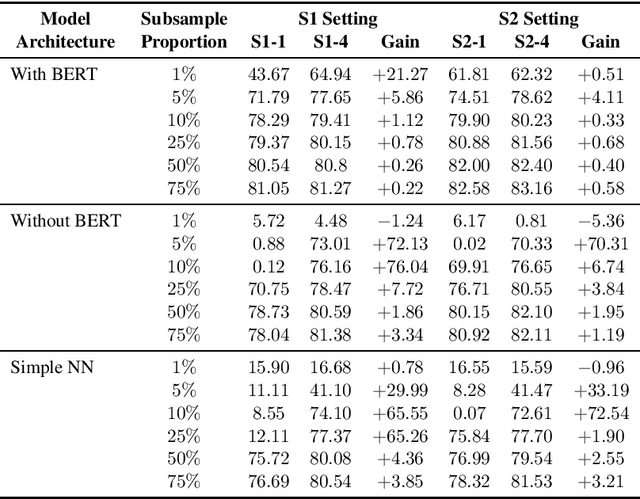
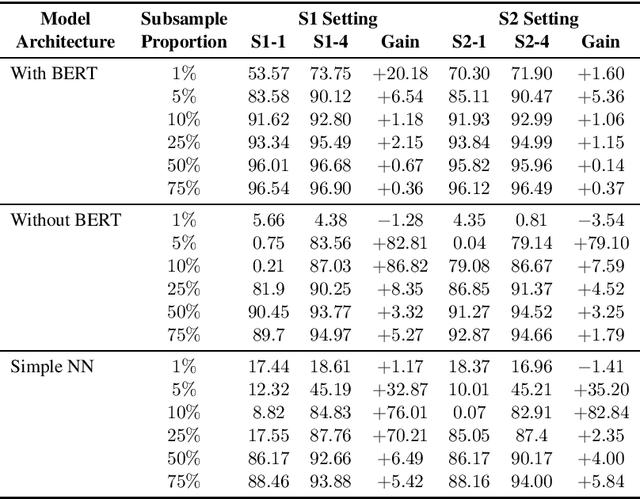
Speech-based virtual assistants, such as Amazon Alexa, Google assistant, and Apple Siri, typically convert users' audio signals to text data through automatic speech recognition (ASR) and feed the text to downstream dialog models for natural language understanding and response generation. The ASR output is error-prone; however, the downstream dialog models are often trained on error-free text data, making them sensitive to ASR errors during inference time. To bridge the gap and make dialog models more robust to ASR errors, we leverage an ASR error simulator to inject noise into the error-free text data, and subsequently train the dialog models with the augmented data. Compared to other approaches for handling ASR errors, such as using ASR lattice or end-to-end methods, our data augmentation approach does not require any modification to the ASR or downstream dialog models; our approach also does not introduce any additional latency during inference time. We perform extensive experiments on benchmark data and show that our approach improves the performance of downstream dialog models in the presence of ASR errors, and it is particularly effective in the low-resource situations where there are constraints on model size or the training data is scarce.