 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Quality Related Search Query Suggestions using Deep Reinforcement Learning
Aug 10, 2021
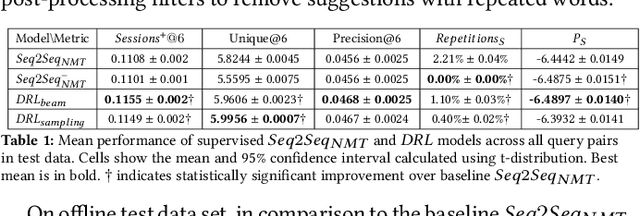


"High Quality Related Search Query Suggestions" task aims at recommending search queries which are real, accurate, diverse, relevant and engaging. Obtaining large amounts of query-quality human annotations is expensive. Prior work on supervised query suggestion models suffered from selection and exposure bias, and relied on sparse and noisy immediate user-feedback (e.g., clicks), leading to low quality suggestions. Reinforcement Learning techniques employed to reformulate a query using terms from search results, have limited scalability to large-scale industry applications. To recommend high quality related search queries, we train a Deep Reinforcement Learning model to predict the query a user would enter next. The reward signal is composed of long-term session-based user feedback, syntactic relatedness and estimated naturalness of generated query. Over the baseline supervised model, our proposed approach achieves a significant relative improvement in terms of recommendation diversity (3%), down-stream user-engagement (4.2%) and per-sentence word repetitions (82%).
Joint Turn and Dialogue level User Satisfaction Estimation on Multi-Domain Conversations
Oct 08, 2020
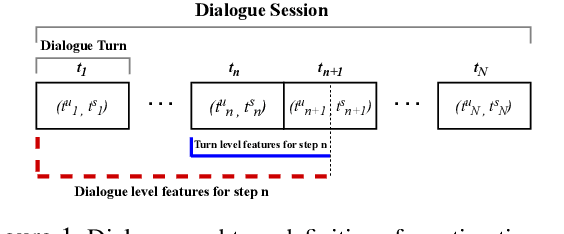
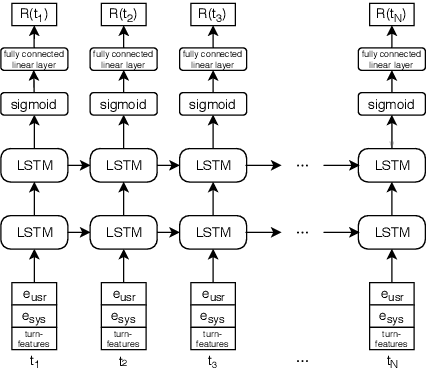
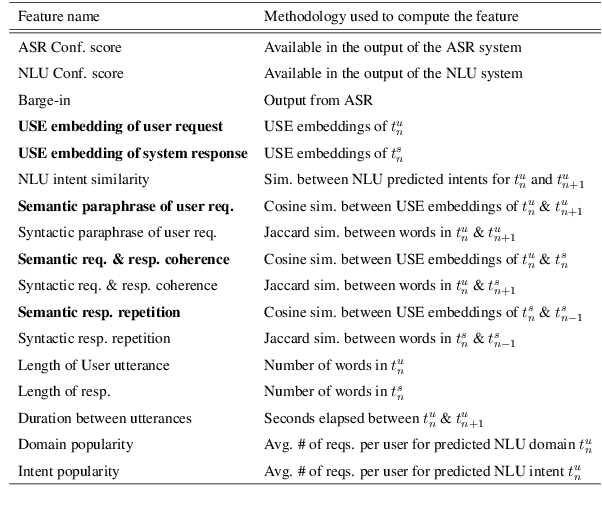
Dialogue level quality estimation is vital for optimizing data driven dialogue management. Current automated methods to estimate turn and dialogue level user satisfaction employ hand-crafted features and rely on complex annotation schemes, which reduce the generalizability of the trained models. We propose a novel user satisfaction estimation approach which minimizes an adaptive multi-task loss function in order to jointly predict turn-level Response Quality labels provided by experts and explicit dialogue-level ratings provided by end users. The proposed BiLSTM based deep neural net model automatically weighs each turn's contribution towards the estimated dialogue-level rating, implicitly encodes temporal dependencies, and removes the need to hand-craft features. On dialogues sampled from 28 Alexa domains, two dialogue systems and three user groups, the joint dialogue-level satisfaction estimation model achieved up to an absolute 27% (0.43->0.70) and 7% (0.63->0.70) improvement in linear correlation performance over baseline deep neural net and benchmark Gradient boosting regression models, respectively.
Multi-domain Conversation Quality Evaluation via User Satisfaction Estimation
Nov 18, 2019
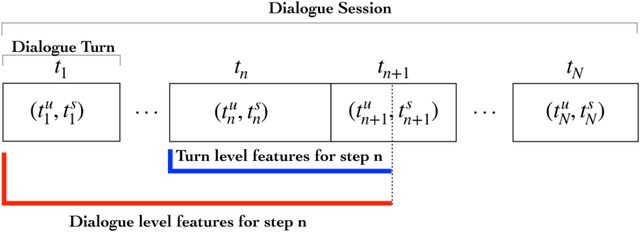
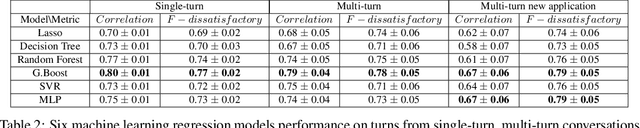
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and employ annotation schemes with limited generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, introduced five new domain-independent feature sets and experimented with six machine learning models to estimate User Satisfaction at both turn and dialogue level. Response Quality ratings achieved significantly high correlation (0.76) with explicit turn-level user ratings. Using the new feature sets we introduced, Gradient Boosting Regression model achieved best (rating [1-5]) prediction performance on 26 seen (linear correlation ~0.79) and one new multi-turn domain (linear correlation 0.67). We observed a 16% relative improvement (68% -> 79%) in binary ("satisfactory/dissatisfactory") class prediction accuracy of a domain-independent dialogue-level satisfaction estimation model after including predicted turn-level satisfaction ratings as features.
Domain-Independent turn-level Dialogue Quality Evaluation via User Satisfaction Estimation
Aug 19, 2019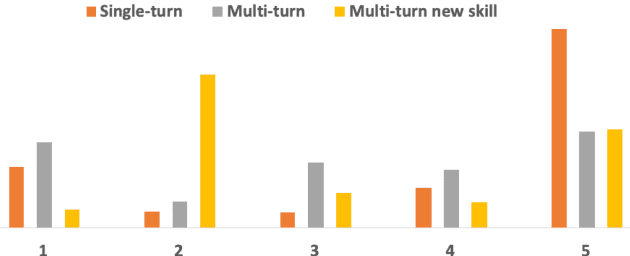
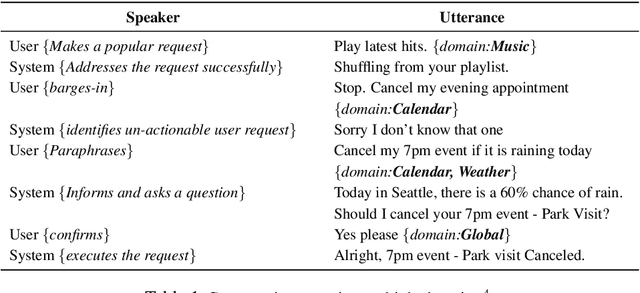
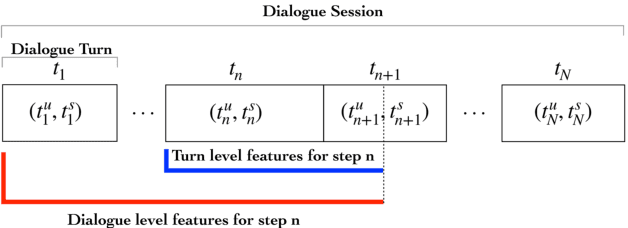
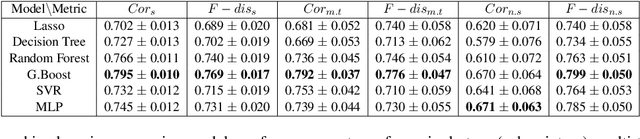
An automated metric to evaluate dialogue quality is vital for optimizing data driven dialogue management. The common approach of relying on explicit user feedback during a conversation is intrusive and sparse. Current models to estimate user satisfaction use limited feature sets and rely on annotation schemes with low inter-rater reliability, limiting generalizability to conversations spanning multiple domains. To address these gaps, we created a new Response Quality annotation scheme, based on which we developed turn-level User Satisfaction metric. We introduced five new domain-independent feature sets and experimented with six machine learning models to estimate the new satisfaction metric. Using Response Quality annotation scheme, across randomly sampled single and multi-turn conversations from 26 domains, we achieved high inter-annotator agreement (Spearman's rho 0.94). The Response Quality labels were highly correlated (0.76) with explicit turn-level user ratings. Gradient boosting regression achieved best correlation of ~0.79 between predicted and annotated user satisfaction labels. Multi Layer Perceptron and Gradient Boosting regression models generalized to an unseen domain better (linear correlation 0.67) than other models. Finally, our ablation study verified that our novel features significantly improved model performance.