 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eighth Dialog System Technology Challenge
Nov 14, 2019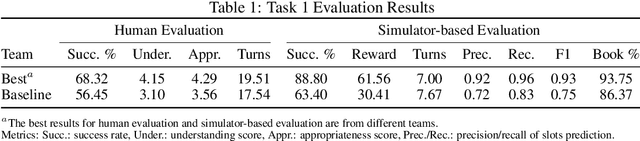
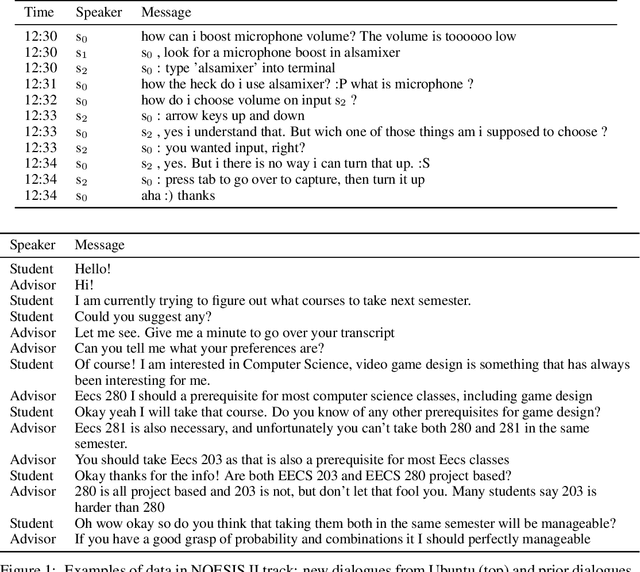
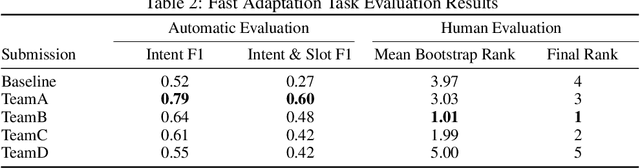
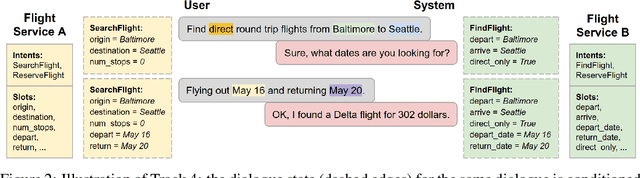
This paper introduces the Eighth Dialog System Technology Challenge. In line with recent challenges, the eighth edition focuses on applying end-to-end dialog technologies in a pragmatic way for multi-domain task-completion, noetic response selection, audio visual scene-aware dialog, and schema-guided dialog state tracking tasks. This paper describes the task definition, provided datasets, and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
HEIDL: Learning Linguistic Expressions with Deep Learning and Human-in-the-Loop
Jul 25, 2019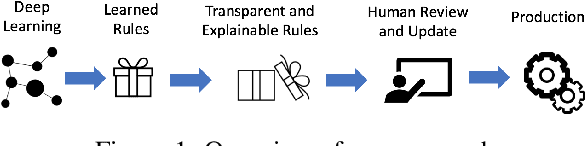
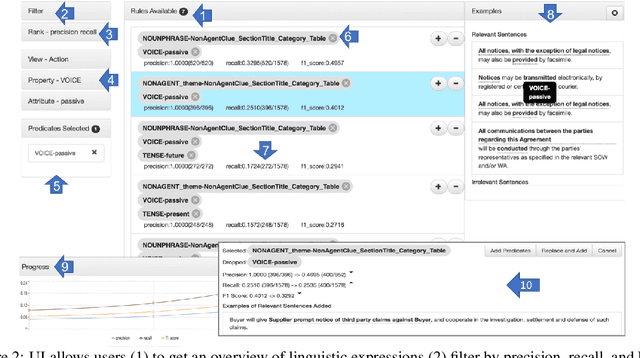
While the role of humans is increasingly recognized in machine learning community, representation of and interaction with models in current human-in-the-loop machine learning (HITL-ML) approaches are too low-level and far-removed from human's conceptual models. We demonstrate HEIDL, a prototype HITL-ML system that exposes the machine-learned model through high-level, explainable linguistic expressions formed of predicates representing semantic structure of text. In HEIDL, human's role is elevated from simply evaluating model predictions to interpreting and even updating the model logic directly by enabling interaction with rule predicates themselves. Raising the currency of interaction to such semantic levels calls for new interaction paradigms between humans and machines that result in improved productivity for text analytics model development process. Moreover, by involving humans in the process, the human-machine co-created models generalize better to unseen data as domain experts are able to instill their expertise by extrapolating from what has been learned by automated algorithms from few labelled data.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
Analyzing Assumptions in Conversation Disentanglement Research Through the Lens of a New Dataset and Model
Oct 25, 2018
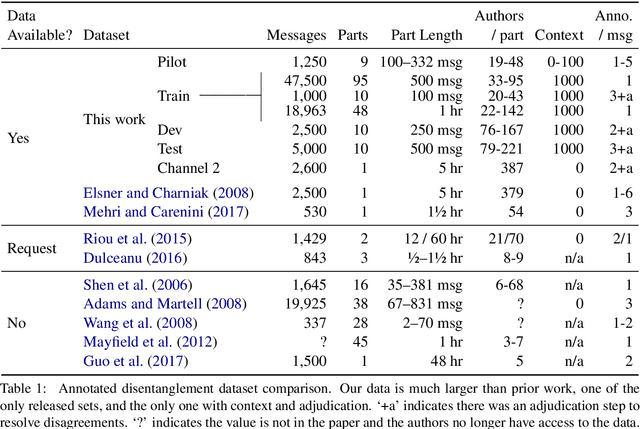

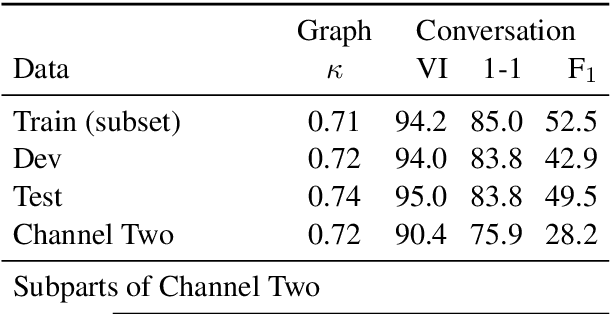
Disentangling conversations mixed together in a single stream of messages is a difficult task with no large annotated datasets. We created a new dataset that is 25 times the size of any previous publicly available resource, has samples of conversation from 152 points in time across a decade, and is annotated with both threads and a within-thread reply-structure graph. We also developed a new neural network model, which extracts conversation threads substantially more accurately than prior work. Using our annotated data and our model we tested assumptions in prior work, revealing major issues in heuristically constructed resources, and identifying how small datasets have biased our understanding of multi-party multi-conversation chat.
Understanding Task Design Trade-offs in Crowdsourced Paraphrase Collection
Oct 19, 2017
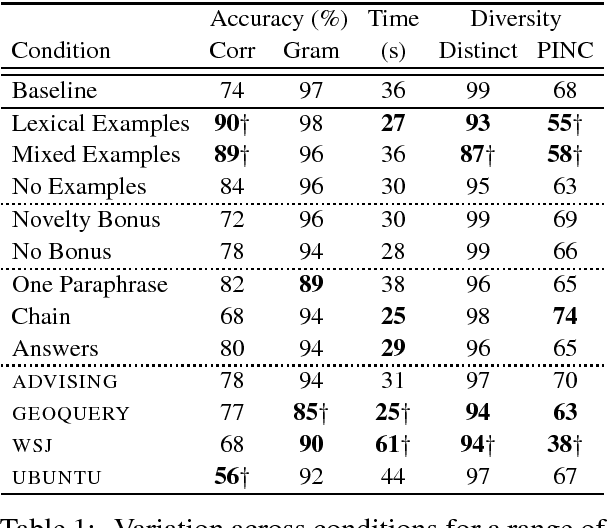
Linguistically diverse datasets are critical for training and evaluating robust machine learning systems, but data collection is a costly process that often requires experts. Crowdsourcing the process of paraphrase generation is an effective means of expanding natural language datasets, but there has been limited analysis of the trade-offs that arise when designing tasks. In this paper, we present the first systematic study of the key factors in crowdsourcing paraphrase collection. We consider variations in instructions, incentives, data domains, and workflows. We manually analyzed paraphrases for correctness, grammaticality, and linguistic diversity. Our observations provide new insight into the trade-offs between accuracy and diversity in crowd responses that arise as a result of task design, providing guidance for future paraphrase generation procedures.
"Is there anything else I can help you with?": Challenges in Deploying an On-Demand Crowd-Powered Conversational Agent
Aug 10, 2017
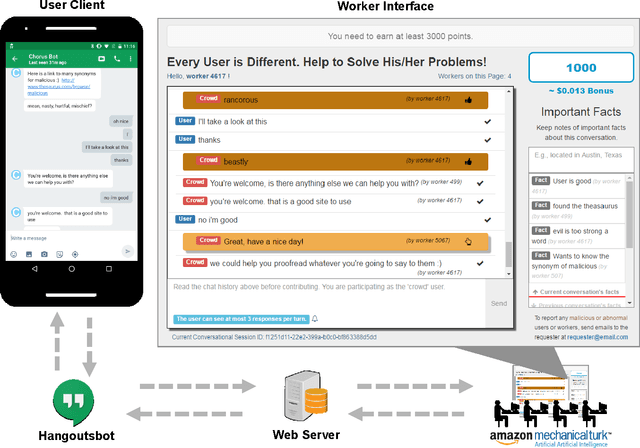

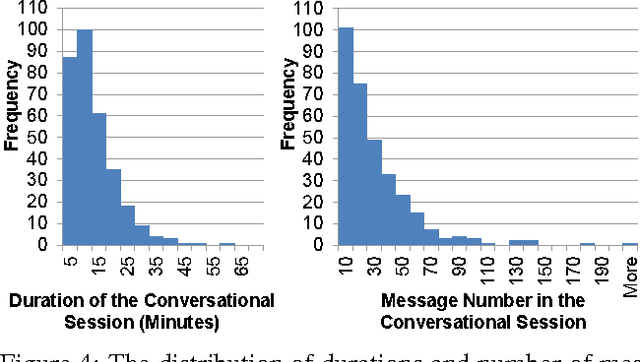
Intelligent conversational assistants, such as Apple's Siri, Microsoft's Cortana, and Amazon's Echo, have quickly become a part of our digital life. However, these assistants have major limitations, which prevents users from conversing with them as they would with human dialog partners. This limits our ability to observe how users really want to interact with the underlying system. To address this problem, we developed a crowd-powered conversational assistant, Chorus, and deployed it to see how users and workers would interact together when mediated by the system. Chorus sophisticatedly converses with end users over time by recruiting workers on demand, which in turn decide what might be the best response for each user sentence. Up to the first month of our deployment, 59 users have held conversations with Chorus during 320 conversational sessions. In this paper, we present an account of Chorus' deployment, with a focus on four challenges: (i) identifying when conversations are over, (ii) malicious users and workers, (iii) on-demand recruiting, and (iv) settings in which consensus is not enough. Our observations could assist the deployment of crowd-powered conversation systems and crowd-powered systems in general.