 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame-Level Internal Tool Use for Temporal Grounding in Audio LMs
Feb 10, 2026Large audio language models are increasingly used for complex audio understanding tasks, but they struggle with temporal tasks that require precise temporal grounding, such as word alignment and speaker diarization. The standard approach, where we generate timestamps as sequences of text tokens, is computationally expensive and prone to hallucination, especially when processing audio lengths outside the model's training distribution. In this work, we propose frame-level internal tool use, a method that trains audio LMs to use their own internal audio representations to perform temporal grounding directly. We introduce a lightweight prediction mechanism trained via two objectives: a binary frame classifier and a novel inhomogeneous Poisson process (IHP) loss that models temporal event intensity. Across word localization, speaker diarization, and event localization tasks, our approach outperforms token-based baselines. Most notably, it achieves a >50x inference speedup and demonstrates robust length generalization, maintaining high accuracy on out-of-distribution audio durations where standard token-based models collapse completely.
ACID: Abstractive, Content-Based IDs for Document Retrieval with Language Models
Nov 14, 2023



Generative retrieval (Wang et al., 2022; Tay et al., 2022) is a new approach for end-to-end document retrieval that directly generates document identifiers given an input query. Techniques for designing effective, high-quality document IDs remain largely unexplored. We introduce ACID, in which each document's ID is composed of abstractive keyphrases generated by a large language model, rather than an integer ID sequence as done in past work. We compare our method with the current state-of-the-art technique for ID generation, which produces IDs through hierarchical clustering of document embeddings. We also examine simpler methods to generate natural-language document IDs, including the naive approach of using the first k words of each document as its ID or words with high BM25 scores in that document. We show that using ACID improves top-10 and top-20 accuracy by 15.6% and 14.4% (relative) respectively versus the state-of-the-art baseline on the MSMARCO 100k retrieval task, and 4.4% and 4.0% respectively on the Natural Questions 100k retrieval task. Our results demonstrate the effectiveness of human-readable, natural-language IDs in generative retrieval with LMs. The code for reproducing our results and the keyword-augmented datasets will be released on formal publication.
NarrowBERT: Accelerating Masked Language Model Pretraining and Inference
Jan 11, 2023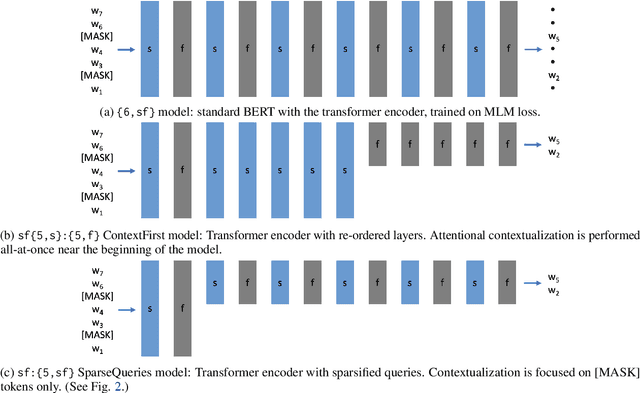

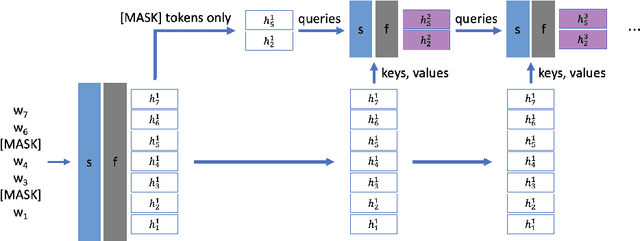
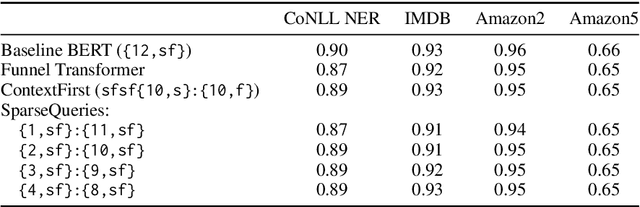
Large-scale language model pretraining is a very successful form of self-supervised learning in natural language processing, but it is increasingly expensive to perform as the models and pretraining corpora have become larger over time. We propose NarrowBERT, a modified transformer encoder that increases the throughput for masked language model pretraining by more than $2\times$. NarrowBERT sparsifies the transformer model such that the self-attention queries and feedforward layers only operate on the masked tokens of each sentence during pretraining, rather than all of the tokens as with the usual transformer encoder. We also show that NarrowBERT increases the throughput at inference time by as much as $3.5\times$ with minimal (or no) performance degradation on sentence encoding tasks like MNLI. Finally, we examine the performance of NarrowBERT on the IMDB and Amazon reviews classification and CoNLL NER tasks and show that it is also comparable to standard BERT performance.
Domain Mismatch Doesn't Always Prevent Cross-Lingual Transfer Learning
Nov 30, 2022



Cross-lingual transfer learning without labeled target language data or parallel text has been surprisingly effective in zero-shot cross-lingual classification, question answering, unsupervised machine translation, etc. However, some recent publications have claimed that domain mismatch prevents cross-lingual transfer, and their results show that unsupervised bilingual lexicon induction (UBLI) and unsupervised neural machine translation (UNMT) do not work well when the underlying monolingual corpora come from different domains (e.g., French text from Wikipedia but English text from UN proceedings). In this work, we show that a simple initialization regimen can overcome much of the effect of domain mismatch in cross-lingual transfer. We pre-train word and contextual embeddings on the concatenated domain-mismatched corpora, and use these as initializations for three tasks: MUSE UBLI, UN Parallel UNMT, and the SemEval 2017 cross-lingual word similarity task. In all cases, our results challenge the conclusions of prior work by showing that proper initialization can recover a large portion of the losses incurred by domain mismatch.
* 8 pages, 1 figure. Published/presented at LREC (2022)
Unsupervised Bitext Mining and Translation via Self-trained Contextual Embeddings
Oct 15, 2020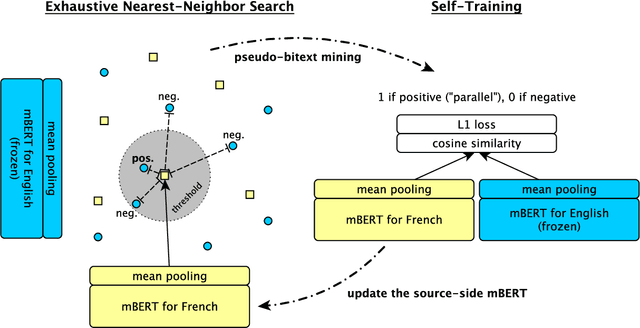
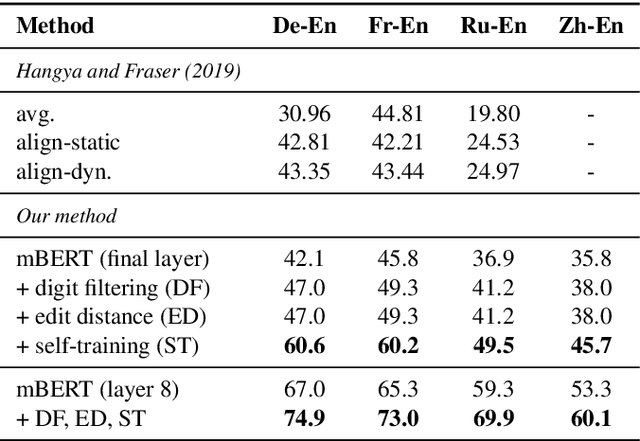

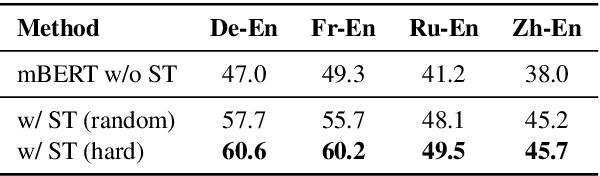
We describe an unsupervised method to create pseudo-parallel corpora for machine translation (MT) from unaligned text. We use multilingual BERT to create source and target sentence embeddings for nearest-neighbor search and adapt the model via self-training. We validate our technique by extracting parallel sentence pairs on the BUCC 2017 bitext mining task and observe up to a 24.5 point increase (absolute) in F1 scores over previous unsupervised methods. We then improve an XLM-based unsupervised neural MT system pre-trained on Wikipedia by supplementing it with pseudo-parallel text mined from the same corpus, boosting unsupervised translation performance by up to 3.5 BLEU on the WMT'14 French-English and WMT'16 German-English tasks and outperforming the previous state-of-the-art. Finally, we enrich the IWSLT'15 English-Vietnamese corpus with pseudo-parallel Wikipedia sentence pairs, yielding a 1.2 BLEU improvement on the low-resource MT task. We demonstrate that unsupervised bitext mining is an effective way of augmenting MT datasets and complements existing techniques like initializing with pre-trained contextual embeddings.
The Multilingual Amazon Reviews Corpus
Oct 06, 2020



We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., 'books', 'appliances', etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot cross-lingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.
Improving Non-autoregressive Neural Machine Translation with Monolingual Data
May 02, 2020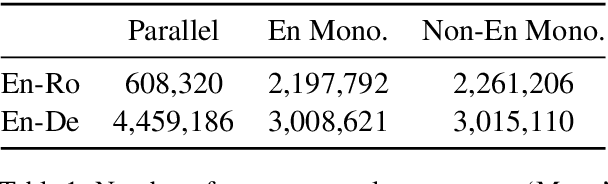
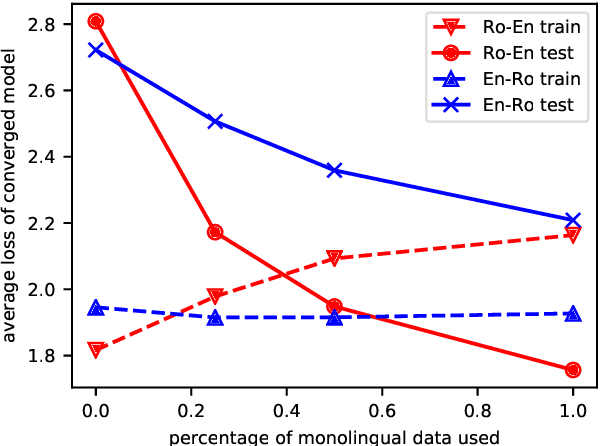
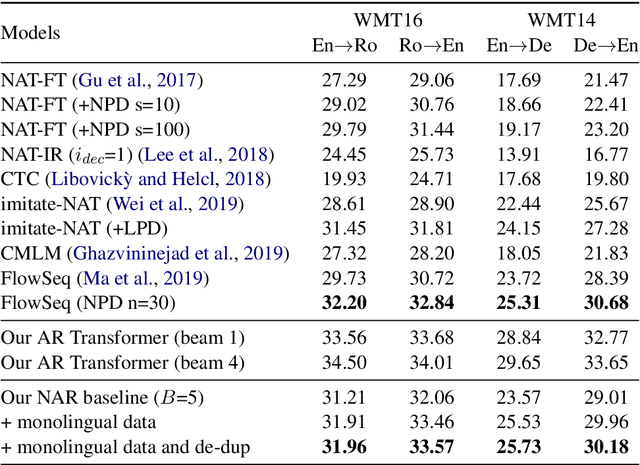
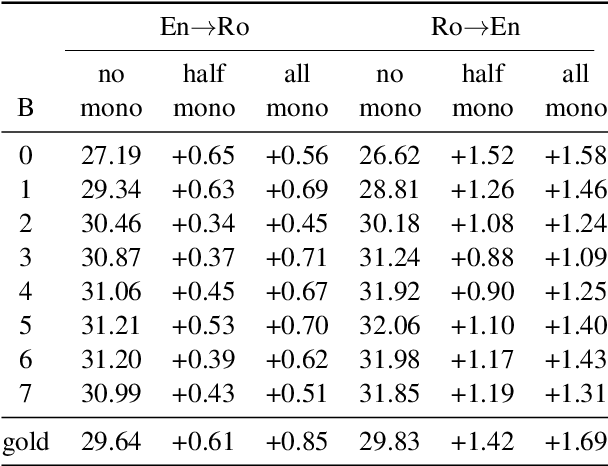
Non-autoregressive (NAR) neural machine translation is usually done via knowledge distillation from an autoregressive (AR) model. Under this framework, we leverage large monolingual corpora to improve the NAR model's performance, with the goal of transferring the AR model's generalization ability while preventing overfitting. On top of a strong NAR baseline, our experimental results on the WMT14 En-De and WMT16 En-Ro news translation tasks confirm that monolingual data augmentation consistently improves the performance of the NAR model to approach the teacher AR model's performance, yields comparable or better results than the best non-iterative NAR methods in the literature and helps reduce overfitting in the training process.
On the Evaluation of Contextual Embeddings for Zero-Shot Cross-Lingual Transfer Learning
Apr 30, 2020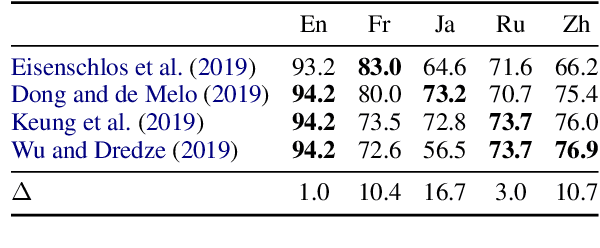
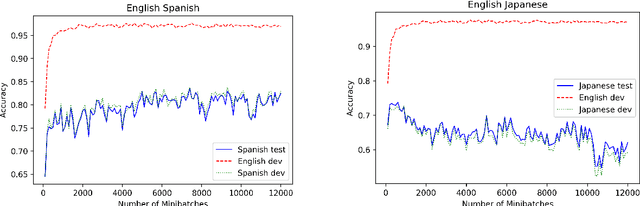
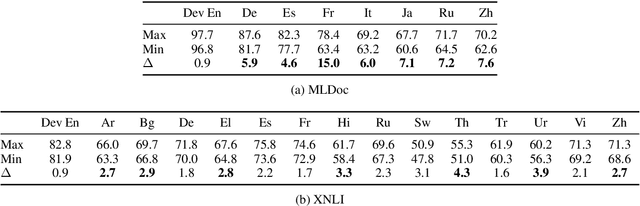
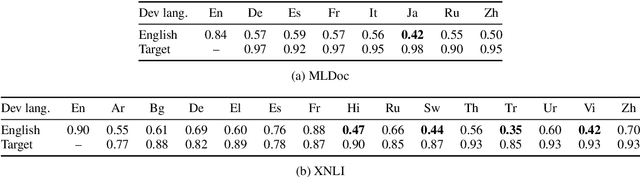
Pre-trained multilingual contextual embeddings have demonstrated state-of-the-art performance in zero-shot cross-lingual transfer learning, where multilingual BERT is fine-tuned on some source language (typically English) and evaluated on a different target language. However, published results for baseline mBERT zero-shot accuracy vary as much as 17 points on the MLDoc classification task across four papers. We show that the standard practice of using English dev accuracy for model selection in the zero-shot setting makes it difficult to obtain reproducible results on the MLDoc and XNLI tasks. English dev accuracy is often uncorrelated (or even anti-correlated) with target language accuracy, and zero-shot cross-lingual performance varies greatly within the same fine-tuning run and between different fine-tuning runs. We recommend providing oracle scores alongside the zero-shot results: still fine-tune using English, but choose a checkpoint with the target dev set. Reporting this upper bound makes results more consistent by avoiding the variation from bad checkpoints.
Attentional Speech Recognition Models Misbehave on Out-of-domain Utterances
Feb 12, 2020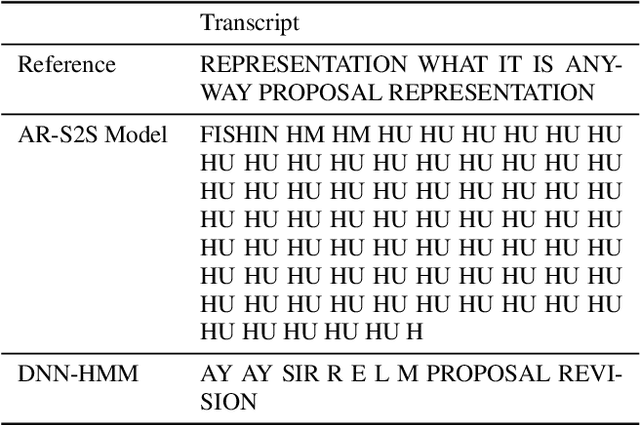
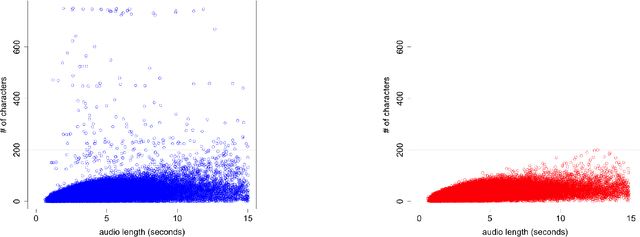
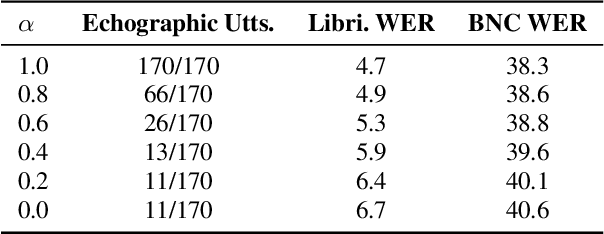
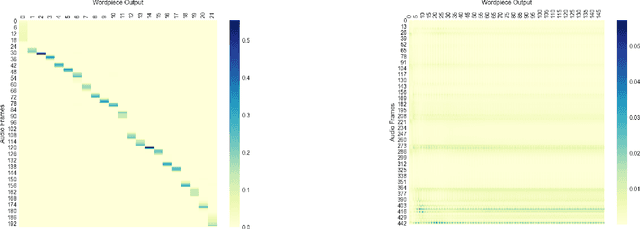
We discuss the problem of echographic transcription in autoregressive sequence-to-sequence attentional architectures for automatic speech recognition, where a model produces very long sequences of repetitive outputs when presented with out-of-domain utterances. We decode audio from the British National Corpus with an attentional encoder-decoder model trained solely on the LibriSpeech corpus. We observe that there are many 5-second recordings that produce more than 500 characters of decoding output (i.e. more than 100 characters per second). A frame-synchronous hybrid (DNN-HMM) model trained on the same data does not produce these unusually long transcripts. These decoding issues are reproducible in a speech transformer model from ESPnet, and to a lesser extent in a self-attention CTC model, suggesting that these issues are intrinsic to the use of the attention mechanism. We create a separate length prediction model to predict the correct number of wordpieces in the output, which allows us to identify and truncate problematic decoding results without increasing word error rates on the LibriSpeech task.
Adversarial Learning with Contextual Embeddings for Zero-resource Cross-lingual Classification and NER
Sep 13, 2019
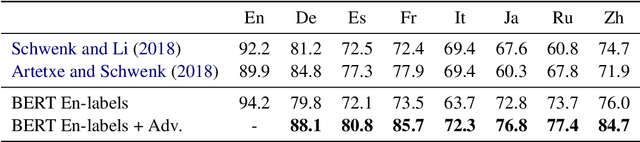

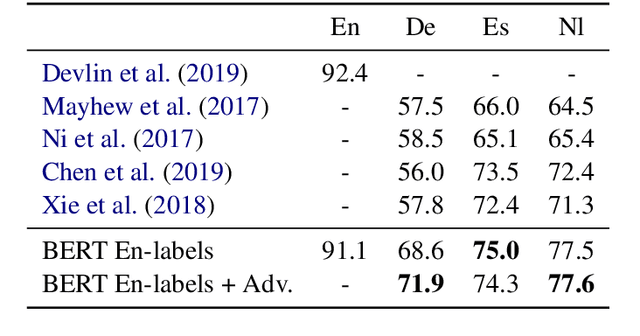
Contextual word embeddings (e.g. GPT, BERT, ELMo, etc.) have demonstrated state-of-the-art performance on various NLP tasks. Recent work with the multilingual version of BERT has shown that the model performs very well in cross-lingual settings, even when only labeled English data is used to finetune the model. We improve upon multilingual BERT's zero-resource cross-lingual performance via adversarial learning. We report the magnitude of the improvement on the multilingual MLDoc text classification and CoNLL 2002/2003 named entity recognition tasks. Furthermore, we show that language-adversarial training encourages BERT to align the embeddings of English documents and their translations, which may be the cause of the observed performance gains.