 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning with Contextual Embeddings for Zero-resource Cross-lingual Classification and NER
Paper and Code

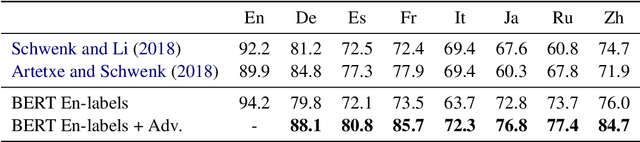

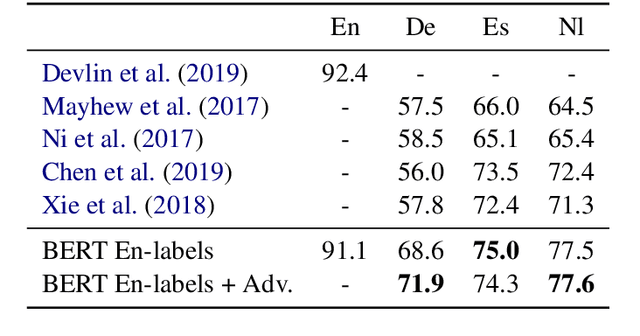
Contextual word embeddings (e.g. GPT, BERT, ELMo, etc.) have demonstrated state-of-the-art performance on various NLP tasks. Recent work with the multilingual version of BERT has shown that the model performs very well in cross-lingual settings, even when only labeled English data is used to finetune the model. We improve upon multilingual BERT's zero-resource cross-lingual performance via adversarial learning. We report the magnitude of the improvement on the multilingual MLDoc text classification and CoNLL 2002/2003 named entity recognition tasks. Furthermore, we show that language-adversarial training encourages BERT to align the embeddings of English documents and their translations, which may be the cause of the observed performance gains.