 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIMPSE : Real-Time Text Recognition and Contextual Understanding for VQA in Wearables
Feb 13, 2026Video Large Language Models (Video LLMs) have shown remarkable progress in understanding and reasoning about visual content, particularly in tasks involving text recognition and text-based visual question answering (Text VQA). However, deploying Text VQA on wearable devices faces a fundamental tension: text recognition requires high-resolution video, but streaming high-quality video drains battery and causes thermal throttling. Moreover, existing models struggle to maintain coherent temporal context when processing text across multiple frames in real-time streams. We observe that text recognition and visual reasoning have asymmetric resolution requirements - OCR needs fine detail while scene understanding tolerates coarse features. We exploit this asymmetry with a hybrid architecture that performs selective high-resolution OCR on-device while streaming low-resolution video for visual context. On a benchmark of text-based VQA samples across five task categories, our system achieves 72% accuracy at 0.49x the power consumption of full-resolution streaming, enabling sustained VQA sessions on resource-constrained wearables without sacrificing text understanding quality.
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Lumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
Conversational Answer Generation and Factuality for Reading Comprehension Question-Answering
Mar 11, 2021
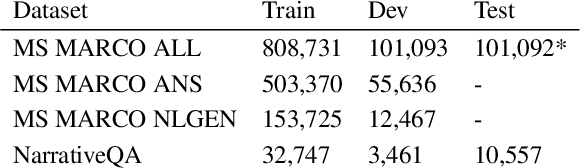
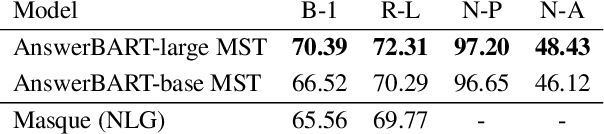
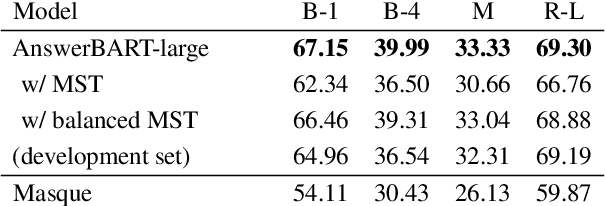
Question answering (QA) is an important use case on voice assistants. A popular approach to QA is extractive reading comprehension (RC) which finds an answer span in a text passage. However, extractive answers are often unnatural in a conversational context which results in suboptimal user experience. In this work, we investigate conversational answer generation for QA. We propose AnswerBART, an end-to-end generative RC model which combines answer generation from multiple passages with passage ranking and answerability. Moreover, a hurdle in applying generative RC are hallucinations where the answer is factually inconsistent with the passage text. We leverage recent work from summarization to evaluate factuality. Experiments show that AnswerBART significantly improves over previous best published results on MS MARCO 2.1 NLGEN by 2.5 ROUGE-L and NarrativeQA by 9.4 ROUGE-L.
Best Practices for Data-Efficient Modeling in NLG:How to Train Production-Ready Neural Models with Less Data
Nov 08, 2020Natural language generation (NLG) is a critical component in conversational systems, owing to its role of formulating a correct and natural text response. Traditionally, NLG components have been deployed using template-based solutions. Although neural network solutions recently developed in the research community have been shown to provide several benefits, deployment of such model-based solutions has been challenging due to high latency, correctness issues, and high data needs. In this paper, we present approaches that have helped us deploy data-efficient neural solutions for NLG in conversational systems to production. We describe a family of sampling and modeling techniques to attain production quality with light-weight neural network models using only a fraction of the data that would be necessary otherwise, and show a thorough comparison between each. Our results show that domain complexity dictates the appropriate approach to achieve high data efficiency. Finally, we distill the lessons from our experimental findings into a list of best practices for production-level NLG model development, and present them in a brief runbook. Importantly, the end products of all of the techniques are small sequence-to-sequence models (2Mb) that we can reliably deploy in production.
On the Evaluation of Contextual Embeddings for Zero-Shot Cross-Lingual Transfer Learning
Apr 30, 2020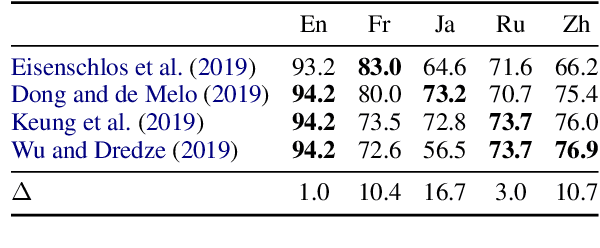
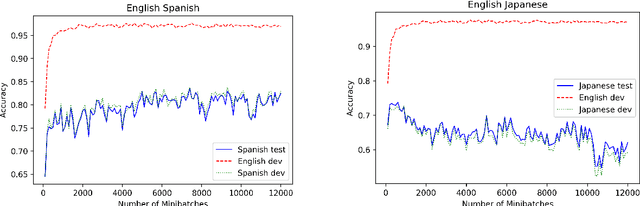
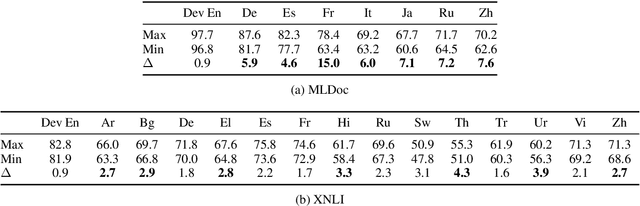
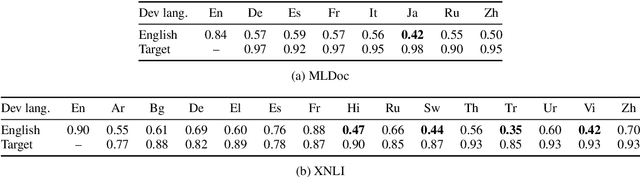
Pre-trained multilingual contextual embeddings have demonstrated state-of-the-art performance in zero-shot cross-lingual transfer learning, where multilingual BERT is fine-tuned on some source language (typically English) and evaluated on a different target language. However, published results for baseline mBERT zero-shot accuracy vary as much as 17 points on the MLDoc classification task across four papers. We show that the standard practice of using English dev accuracy for model selection in the zero-shot setting makes it difficult to obtain reproducible results on the MLDoc and XNLI tasks. English dev accuracy is often uncorrelated (or even anti-correlated) with target language accuracy, and zero-shot cross-lingual performance varies greatly within the same fine-tuning run and between different fine-tuning runs. We recommend providing oracle scores alongside the zero-shot results: still fine-tune using English, but choose a checkpoint with the target dev set. Reporting this upper bound makes results more consistent by avoiding the variation from bad checkpoints.
Attentional Speech Recognition Models Misbehave on Out-of-domain Utterances
Feb 12, 2020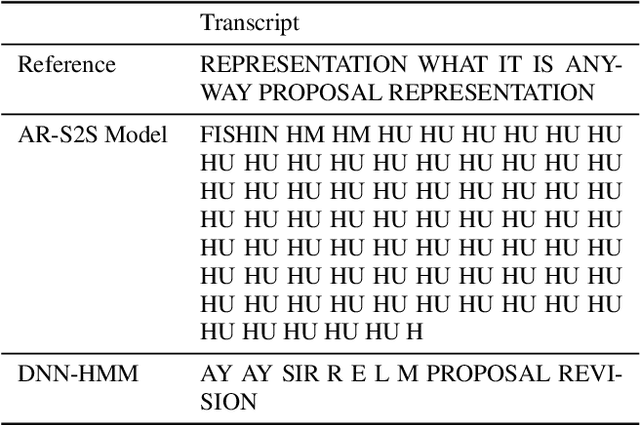
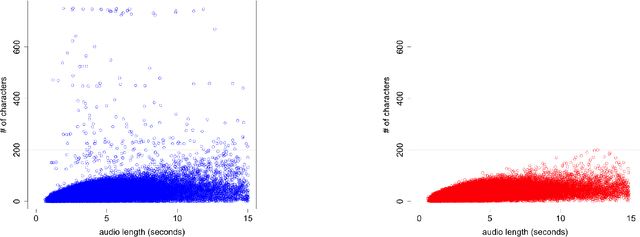
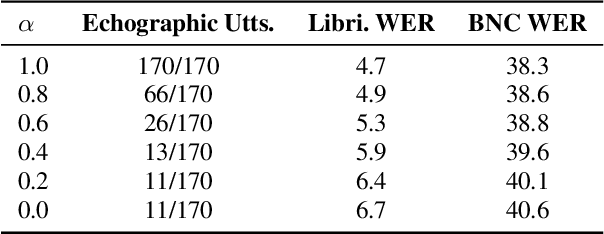
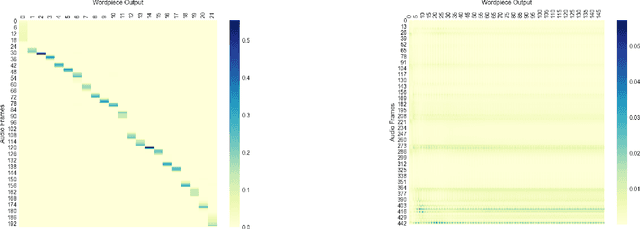
We discuss the problem of echographic transcription in autoregressive sequence-to-sequence attentional architectures for automatic speech recognition, where a model produces very long sequences of repetitive outputs when presented with out-of-domain utterances. We decode audio from the British National Corpus with an attentional encoder-decoder model trained solely on the LibriSpeech corpus. We observe that there are many 5-second recordings that produce more than 500 characters of decoding output (i.e. more than 100 characters per second). A frame-synchronous hybrid (DNN-HMM) model trained on the same data does not produce these unusually long transcripts. These decoding issues are reproducible in a speech transformer model from ESPnet, and to a lesser extent in a self-attention CTC model, suggesting that these issues are intrinsic to the use of the attention mechanism. We create a separate length prediction model to predict the correct number of wordpieces in the output, which allows us to identify and truncate problematic decoding results without increasing word error rates on the LibriSpeech task.
Adversarial Learning with Contextual Embeddings for Zero-resource Cross-lingual Classification and NER
Sep 13, 2019
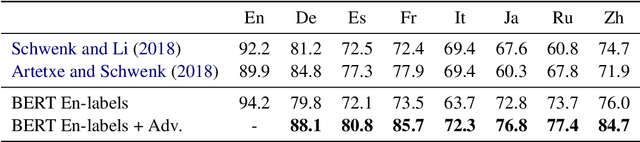

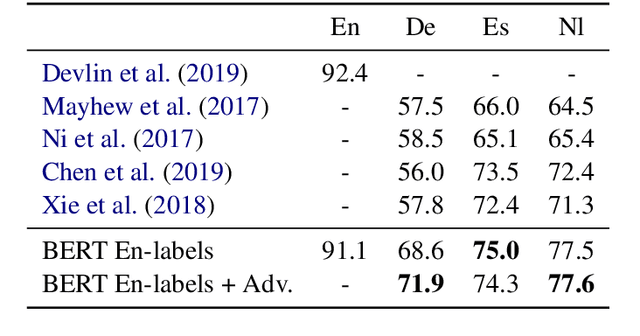
Contextual word embeddings (e.g. GPT, BERT, ELMo, etc.) have demonstrated state-of-the-art performance on various NLP tasks. Recent work with the multilingual version of BERT has shown that the model performs very well in cross-lingual settings, even when only labeled English data is used to finetune the model. We improve upon multilingual BERT's zero-resource cross-lingual performance via adversarial learning. We report the magnitude of the improvement on the multilingual MLDoc text classification and CoNLL 2002/2003 named entity recognition tasks. Furthermore, we show that language-adversarial training encourages BERT to align the embeddings of English documents and their translations, which may be the cause of the observed performance gains.
A neural interlingua for multilingual machine translation
Oct 16, 2018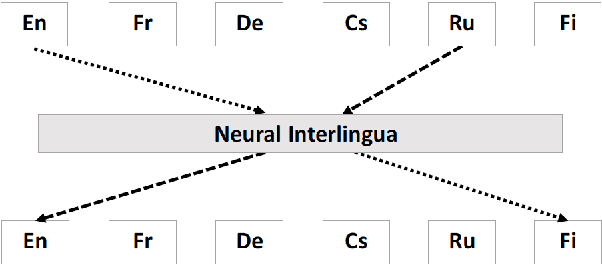
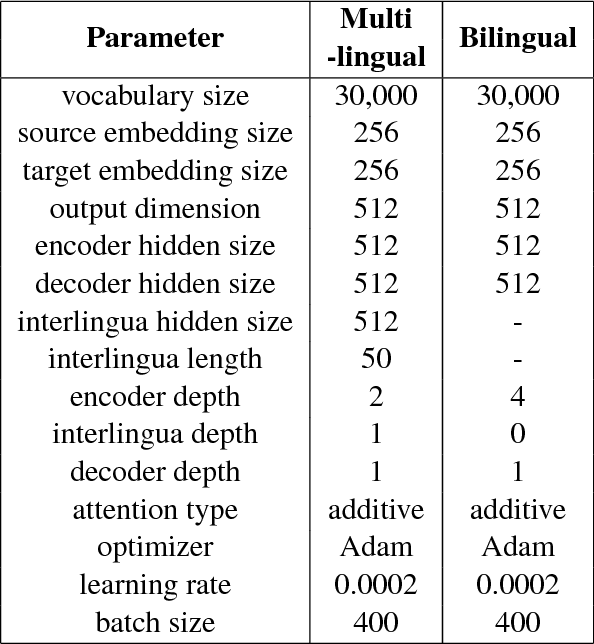
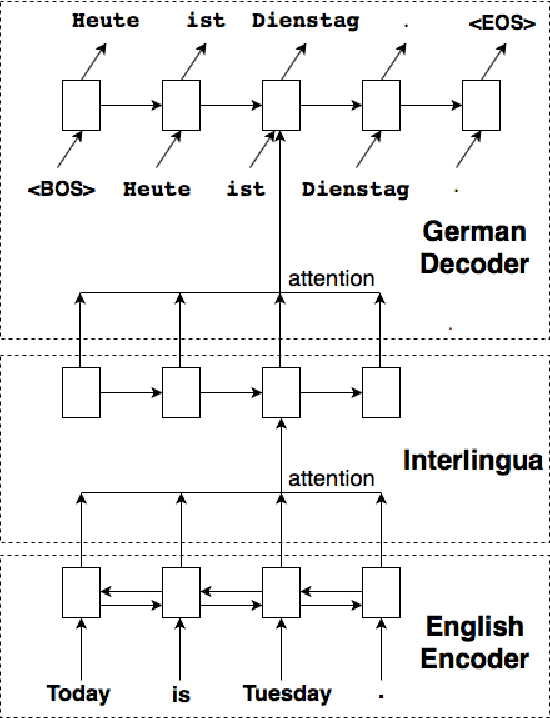
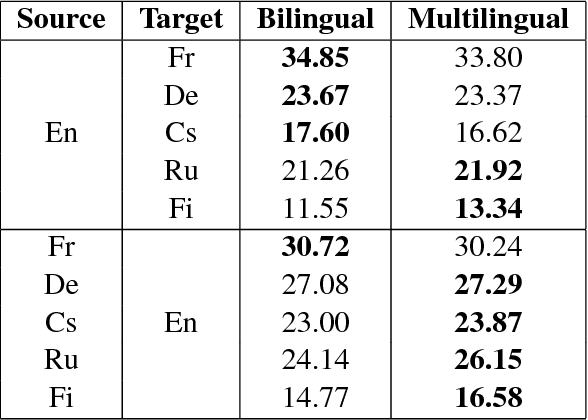
We incorporate an explicit neural interlingua into a multilingual encoder-decoder neural machine translation (NMT) architecture. We demonstrate that our model learns a language-independent representation by performing direct zero-shot translation (without using pivot translation), and by using the source sentence embeddings to create an English Yelp review classifier that, through the mediation of the neural interlingua, can also classify French and German reviews. Furthermore, we show that, despite using a smaller number of parameters than a pairwise collection of bilingual NMT models, our approach produces comparable BLEU scores for each language pair in WMT15.
A practical approach to dialogue response generation in closed domains
Mar 28, 2017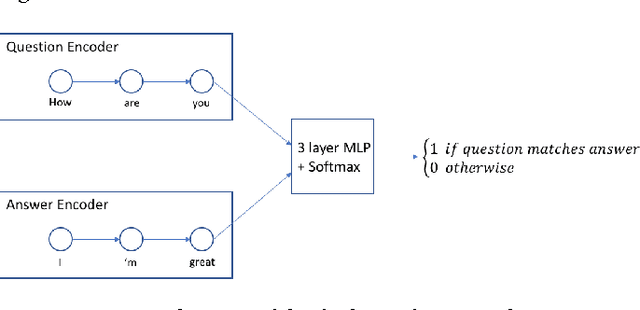


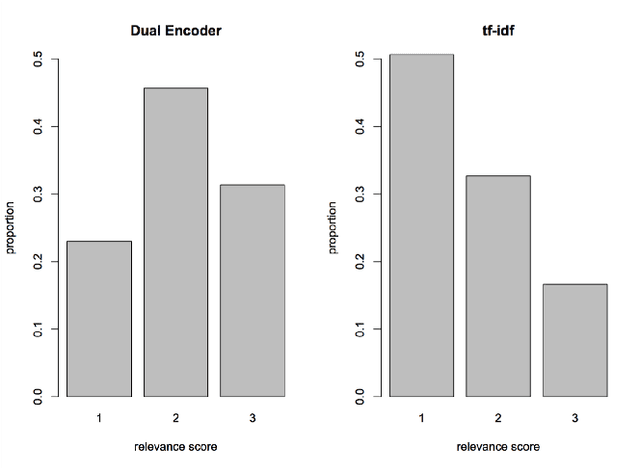
We describe a prototype dialogue response generation model for the customer service domain at Amazon. The model, which is trained in a weakly supervised fashion, measures the similarity between customer questions and agent answers using a dual encoder network, a Siamese-like neural network architecture. Answer templates are extracted from embeddings derived from past agent answers, without turn-by-turn annotations. Responses to customer inquiries are generated by selecting the best template from the final set of templates. We show that, in a closed domain like customer service, the selected templates cover $>$70\% of past customer inquiries. Furthermore, the relevance of the model-selected templates is significantly higher than templates selected by a standard tf-idf baseline.