 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIMPSE : Real-Time Text Recognition and Contextual Understanding for VQA in Wearables
Feb 13, 2026Video Large Language Models (Video LLMs) have shown remarkable progress in understanding and reasoning about visual content, particularly in tasks involving text recognition and text-based visual question answering (Text VQA). However, deploying Text VQA on wearable devices faces a fundamental tension: text recognition requires high-resolution video, but streaming high-quality video drains battery and causes thermal throttling. Moreover, existing models struggle to maintain coherent temporal context when processing text across multiple frames in real-time streams. We observe that text recognition and visual reasoning have asymmetric resolution requirements - OCR needs fine detail while scene understanding tolerates coarse features. We exploit this asymmetry with a hybrid architecture that performs selective high-resolution OCR on-device while streaming low-resolution video for visual context. On a benchmark of text-based VQA samples across five task categories, our system achieves 72% accuracy at 0.49x the power consumption of full-resolution streaming, enabling sustained VQA sessions on resource-constrained wearables without sacrificing text understanding quality.
EgoQR: Efficient QR Code Reading in Egocentric Settings
Oct 07, 2024



QR codes have become ubiquitous in daily life, enabling rapid information exchange. With the increasing adoption of smart wearable devices, there is a need for efficient, and friction-less QR code reading capabilities from Egocentric point-of-views. However, adapting existing phone-based QR code readers to egocentric images poses significant challenges. Code reading from egocentric images bring unique challenges such as wide field-of-view, code distortion and lack of visual feedback as compared to phones where users can adjust the position and framing. Furthermore, wearable devices impose constraints on resources like compute, power and memory. To address these challenges, we present EgoQR, a novel system for reading QR codes from egocentric images, and is well suited for deployment on wearable devices. Our approach consists of two primary components: detection and decoding, designed to operate on high-resolution images on the device with minimal power consumption and added latency. The detection component efficiently locates potential QR codes within the image, while our enhanced decoding component extracts and interprets the encoded information. We incorporate innovative techniques to handle the specific challenges of egocentric imagery, such as varying perspectives, wider field of view, and motion blur. We evaluate our approach on a dataset of egocentric images, demonstrating 34% improvement in reading the code compared to an existing state of the art QR code readers.
Lumos : Empowering Multimodal LLMs with Scene Text Recognition
Feb 12, 2024



We introduce Lumos, the first end-to-end multimodal question-answering system with text understanding capabilities. At the core of Lumos is a Scene Text Recognition (STR) component that extracts text from first person point-of-view images, the output of which is used to augment input to a Multimodal Large Language Model (MM-LLM). While building Lumos, we encountered numerous challenges related to STR quality, overall latency, and model inference. In this paper, we delve into those challenges, and discuss the system architecture, design choices, and modeling techniques employed to overcome these obstacles. We also provide a comprehensive evaluation for each component, showcasing high quality and efficiency.
A textual transform of multivariate time-series for prognostics
Sep 19, 2017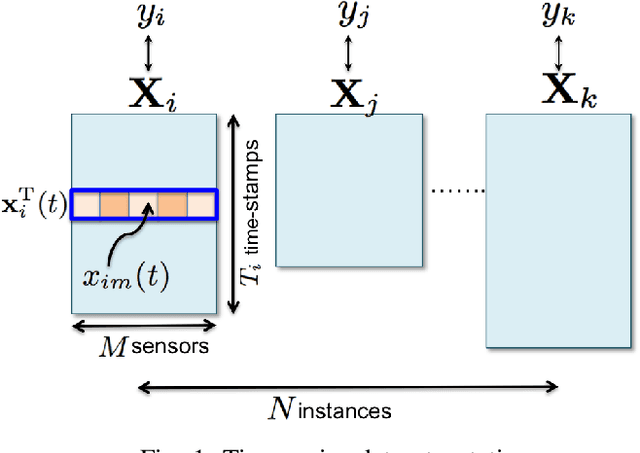
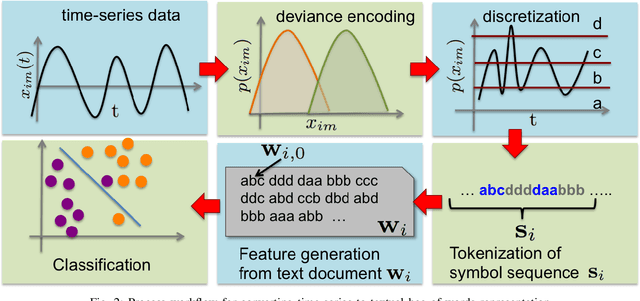

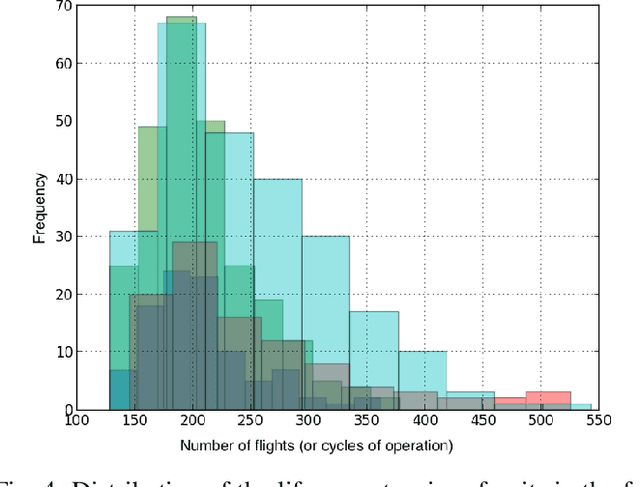
Prognostics or early detection of incipient faults is an important industrial challenge for condition-based and preventive maintenance. Physics-based approaches to modeling fault progression are infeasible due to multiple interacting components, uncontrolled environmental factors and observability constraints. Moreover, such approaches to prognostics do not generalize to new domains. Consequently, domain-agnostic data-driven machine learning approaches to prognostics are desirable. Damage progression is a path-dependent process and explicitly modeling the temporal patterns is critical for accurate estimation of both the current damage state and its progression leading to total failure. In this paper, we present a novel data-driven approach to prognostics that employs a novel textual representation of multivariate temporal sensor observations for predicting the future health state of the monitored equipment early in its life. This representation enables us to utilize well-understood concepts from text-mining for modeling, prediction and understanding distress patterns in a domain agnostic way. The approach has been deployed and successfully tested on large scale multivariate time-series data from commercial aircraft engines. We report experiments on well-known publicly available benchmark datasets and simulation datasets. The proposed approach is shown to be superior in terms of prediction accuracy, lead time to prediction and interpretability.